
Agentes de fortalecimento da aprendizagem (RL) que treinam agentes para tomar decisões consecutivas aumentando as recompensas integradas. Ele contém uma variedade de solicitações, incluindo robótico, jogos e automação, onde os agentes estão em contato com locais para aprender as condições apropriadas. As formas tradicionais de RL se enquadram em duas etapas: métodos e modence sem modelo. As estratégias de modelo gratuitas avançam os mais simples, mas exigem dados mais amplos da Internet, enquanto os modelos de suporte estão apresentando aprendizado formal, mas querem ser mais exigentes. A crescente área de estudo visa fechar esses métodos e melhorar algumas das estruturas de RL mais eficazes que se aplicam bem a todos os domínios.
O desafio persistente na ausência de algoritmo universal pode fazer de forma consistente em muitos lugares sem a ajuste dos parâmetros de parâmetro de parâmetro. A maioria dos algoritmos RL são algoritmos RL projetados para programas específicos, que precisam ser ajustados para se aplicar efetivamente a novas configurações. Os métodos de RL baseados em RL geralmente indicam alta produção, mas com o custo de sérias dificuldades e um leve abate. Por outro lado, os modelos de modelos são simples de usar, mas geralmente em fraqueza quando usados em atividades desconhecidas. Melhorar uma estrutura de RL que inclui as habilidades de ambos os métodos sem comprometer o engano continua sendo uma meta de pesquisa significativa.
Vários métodos de RL apareceram, cada um contendo traders-offs entre trabalho e eficiência. As soluções baseadas em soluções como Douksving3 e TD-MPC2 foram detectadas pelos principais efeitos em diferentes atividades, mas são altamente dependentes de planos de planejamento complexos e maior energia. Outras técnicas gratuitas, incluindo TD3 e PPO, a preferência por requisitos computacionais, mas requer planejamento de domínio. Essa poluição enfatiza a necessidade de algoritmo RL que inclua adaptação e eficiência, o que permite o uso de costuras para todas as várias atividades e lugares.
A equipe de pesquisa da Meta Fair Delegates Mr.Q, algoritmo RL sem modelo, incluindo modelo para melhorar o aprendizado e o desempenho comum. Ao contrário dos métodos de modelo tradicionais, o Sr.Q coloca a fase de leitura prematadora inspirada no modelo, fazendo com que o algoritmo funcione corretamente em todos os diferentes bancos RL. Esta abordagem permite o Sr.
O Mr.Q Framework Spaces dois dois pulmões para entrar no protesto que mantém vários relacionamentos e valorizam o trabalho. Isso incorporou e processado por uma linha limitada de acordo em diferentes locais. O programa inclui o encomer que emite os recursos apropriados da instalação e execução do estado de estado, desenvolvendo estabilidade da aprendizagem. Além disso, o Sr.Q usa um sistema priorit e um processo de reabilitação para melhorar o desempenho do treinamento. O algoritmo atinge a funcionalidade sólida de todos os bancos RL, mantendo a eficiência do computador, concentrando -se em um plano de aprendizado fixo.
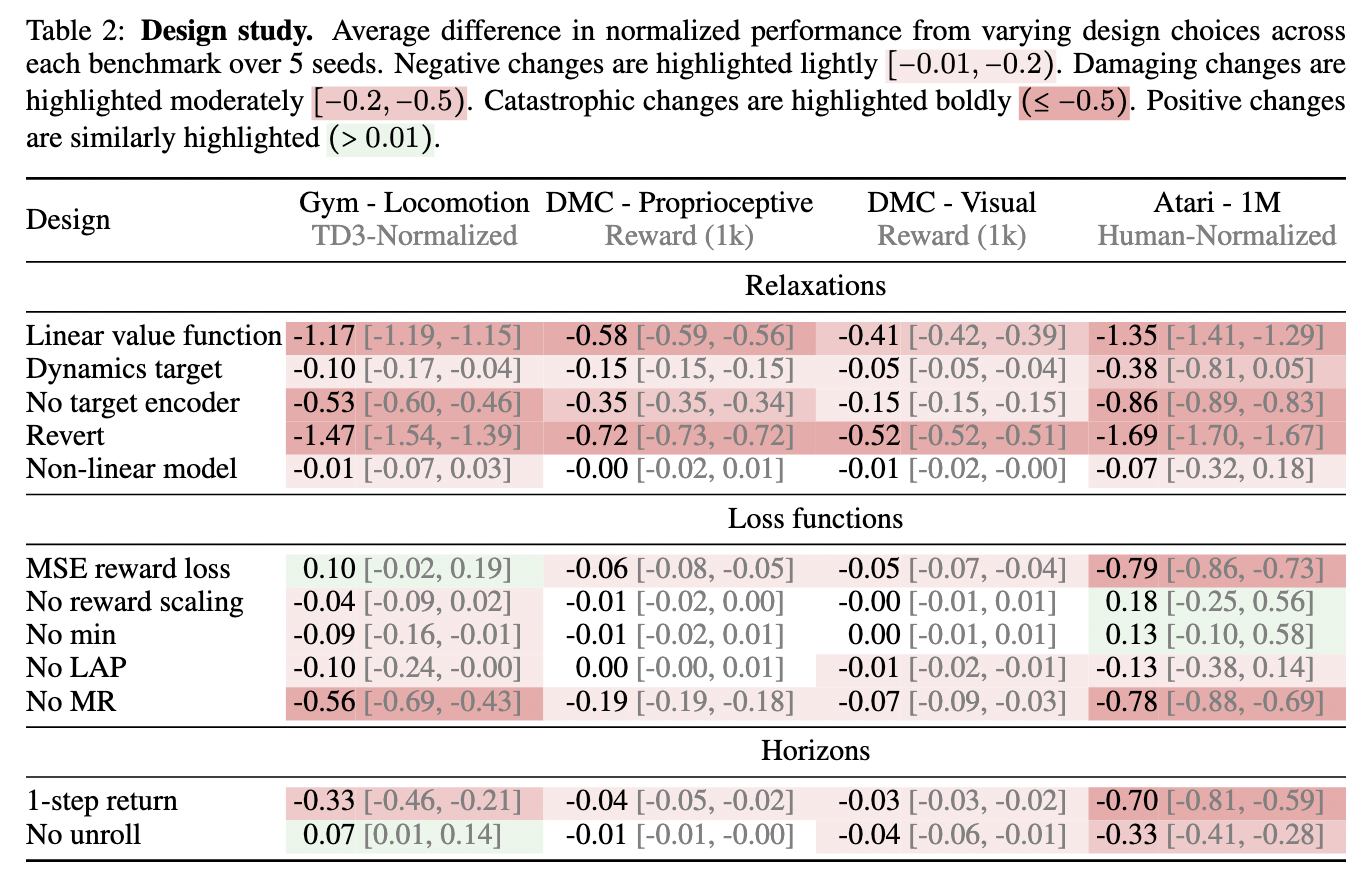
Quatro Serviços Locomocionais de Benchmarks-Gym RL, Suíte de Controle Deepmind, bem como Atari-Show, que o Sr. Q atinge fortes resultados com uma coleção de hiperparemeter. O algoritmo Acndenducforms comuns bases comuns, como PPO e DQN, enquanto continuam trabalhando em comparação com o Dooudrver3 NETD-MPC2. O Sr.Q alcança resultados competitivos ao usar o maior número de recursos do computador, o que a torna uma decisão válida das aplicações reais de terra. Na Atari Benchmark, o Sr.Q está fazendo especialmente nos espaços das ações do discreto, que excedem os métodos existentes. O Mr.Q mostra um forte desempenho nas instalações de controle em andamento, o modelo bases sem modelo e DQN, enquanto armazenam resultados de concorrência em comparação com o DOUPERV3 NETD-MPC2. O algoritmo atinge o melhor desenvolvimento de bons exercícios em todos os bancos sem exigir uma amostra de várias funções. A avaliação destaca a capacidade do Sr.Q de reduzir com sucesso, sem precisar de uma inovação mais ampla de novos serviços.
Estudos enfatizam os benefícios de arquivar o modelo baseado em algoritmos sem algoritos RL. O Mr.Q está colocando ações para obter a construção da estrutura RL mais variáveis, melhorando a eficiência e a flexibilidade. O avanço futuro pode comprometer sua abordagem para lidar com desafios, como problemas de testes difíceis e áreas não-markovian. As descobertas podem contribuir para a ampla vacina do RLS mais acessível e bem -sucedida em muitas aplicações, o Sr.Q Position como a ferramenta promissora para pesquisadores e os reclamantes que desejam RL.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 70k + ml subreddit.
🚨 Conheça o trabalho: um código aberto aberto com várias fontes para verificar o programa difícil AI (Atualizado)
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
✅ [Recommended] Junte -se ao nosso canal de telégrafo
 para automatizar a descoberta de vida artificial usando modelos baseados em visão de linguagem.")

