
Como os modelos profundos de estudo continuam a crescer, a construção dos modelos de aprendizado da máquina é importante e a necessidade de métodos práticos de salto se tornou mais forte. A cotação inferior é um meio reduzido o tamanho do modelo enquanto tenta manter a precisão. Os investigadores têm determinado a melhor largura para melhorar o desempenho adequado sem comprometer o desempenho. Estudos diferentes consideraram diferentes configurações para um diâmetro espesso, mas conclusões conflitantes estão surgindo devido à ausência de estrutura de avaliação regular. Essa obtenção contínua afeta o desenvolvimento dos modelos máximos de articulação, determine se é possível ser usado nos ambientes pressionados.
O maior desafio para o menor dos menores indicar um comércio completo entre computacional e precisão. O debate em que a largura mais eficaz é constantemente em solidismo. No entanto, a pesquisa anterior não foi punida para comparar diferentes configurações para reduzir o tamanho, resultando em conclusões não relevantes. Essa lacuna de informação é acompanhada pelo estabelecimento de leis confiáveis de medição da precisão mínima da precisão. Além disso, alcançar o treinamento estável na preparação mais baixa cria um problema técnico, pois os modelos de baixo bit geralmente ouvem as mudanças mais altas representando os principais parceiros.
Os métodos de uso dos preços variam de trabalho e desempenho. Após treinar o modelo com precisão precisa, o pós-treinamento (PTQ) é aplicado à construção da quantidade, facilitando a redução da corrupção do escopo mais baixo. O treinamento de uma quantia decente (QAT), por outro lado, inclui a construção de treinamento, que permite modelar modelos de maneira eficaz. Algumas estratégias, como a quantidade legível e as estratégias combinadas combinadas, inspecionadas para confirmar o equilíbrio entre precisão e tamanho do modelo. No entanto, esses métodos não têm uma estrutura universal de avaliação formal, dificultando a comparação de seu desempenho em diferentes circunstâncias.
Os investigadores inativos silenciam o Partoq, uma estrutura formal para combinar 4 estratégias menores. Essa estrutura permite comparações fortes em diferentes configurações de alcance, incluindo qualidade de 1 bit, 1,58 bit, 2 bits e 4 bits. Ao avaliar os esquemas de treinamento e as funções do valor especificado, o Paretoq atinge a precisão e a eficiência avançadas dos caminhos anteriores. Diferentemente dos trabalhos anteriores que funcionam melhor em determinados níveis, o Paretoq estabelece o processo de teste consistente comparado diretamente os preços.
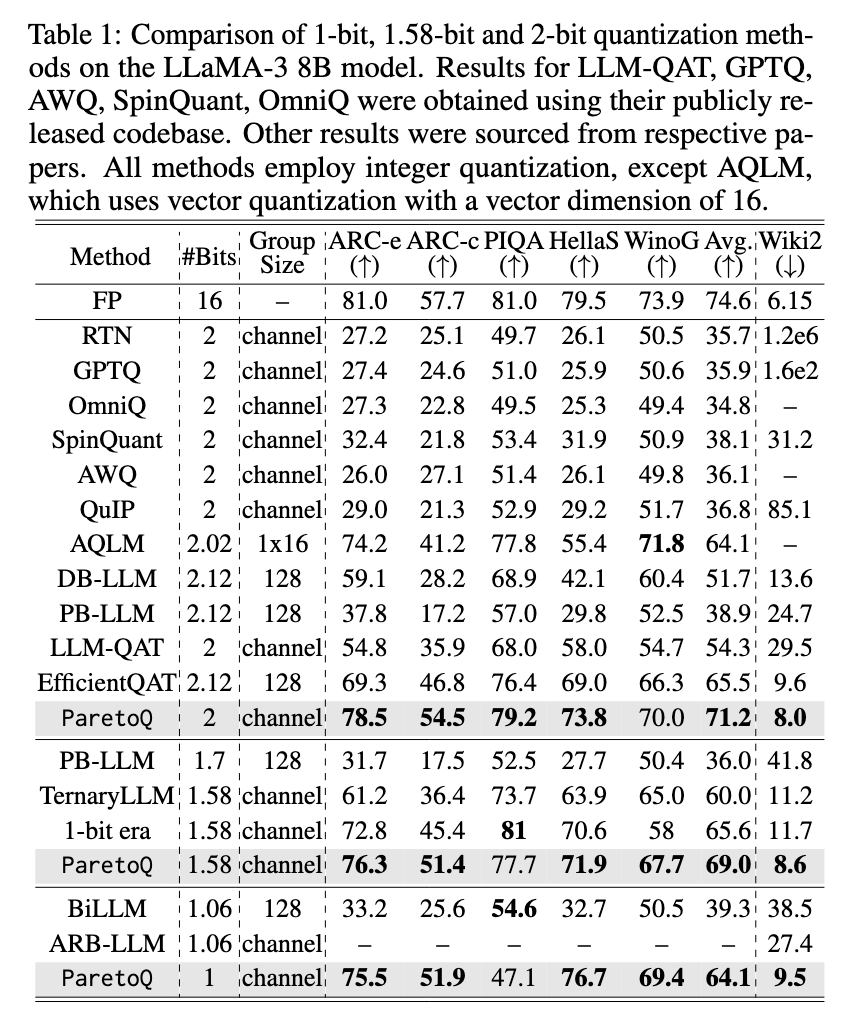
O Paroq usa a estratégia de treinamento para o valor justo de reduzir a perda de precisão, enquanto armazena a eficiência do eflion. A estrutura limpa as funções de bits para encontrar a sensível deste estudo da transformação única do aprendizado armazenado entre preços de 2 bits e 3. Os modelos são treinados em 3 precisão e alto armazenamento, como sua distribuição pré-treinamento, e os colegas de 2 bits ou baixos são treinados. Para superar esse desafio, a estrutura organizou formalmente a quantidade de grade, treinamento e estratégias especializadas de aprendizado.
A avaliação mais ampla garante o maior desempenho do Paretoq na capacidade existente. O modelo de 600m-parâmetros é aprimorado usando o Paretoq ApperPorms Ternery 3B-Parâmetro Modern 3B-Parâmetro com precisão ao usar apenas um cinco do parâmetro. Estudos mostram que 2 pequenas formação alcançaram o desenvolvimento de 1,8% em relação ao modelo de 4 bits do mesmo tamanho, estabelecendo seu desempenho como um método comum de 4 bits. Além disso, o Paretoq permite um uso mais amigável, que é preparado para CPUs de 2 bits que ganham alta velocidade e operação de memória em comparação com o valor de 4 bits. O teste também é revelado que os modelos Terry, 2 bits e 3
A aquisição deste estudo fornece uma base sólida para fazer bem menos que uma pequena formulação de linguagem da linguagem. Ao enviar uma estrutura estruturada, a pesquisa lida com os desafios da negociação comercial e da execução de bom desempenho. Os resultados mostram que, embora a classificação mais baixa seja válida, a taxa de 2 bits e de 3 bits atualmente fornece o melhor equilíbrio entre trabalho e eficiência. O progresso futuro do suporte de hardware para o computador lentamente melhorará a eficácia desses métodos, fazendo o envio adequado de grandes modelos de aprendizado de máquina nas máquinas mais pressionadas.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Registre a plataforma de IA de código aberto: 'Sistema de código aberto interestagente com muitas fontes para testar o programa difícil' (Atualizado)
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
✅ [Recommended] Junte -se ao nosso canal de telégrafo
: estrutura Noviosa que melhora a eficiência de grandes idiomas (LLS) até 4,4 × poucas farinhas")
: uma família multilíngue de última geração para preencher a lacuna linguística na IA")
