
Os sistemas generativos de IA estão revolucionando a maneira como as pessoas interagem com a tecnologia, fornecendo processamento básico de linguagem natural e recursos de geração de conteúdo. No entanto, estes sistemas apresentam riscos significativos, especialmente na geração de conteúdos inseguros ou que violam políticas. Enfrentar este desafio requer ferramentas de medição avançadas que garantam que os resultados sejam seguros e cumpram as diretrizes éticas. Tais ferramentas devem ser funcionais e eficientes, especialmente no uso de hardware com dispositivos como dispositivos móveis.
Um desafio persistente na utilização de modelos de avaliação de segurança é o seu tamanho e requisitos computacionais. Embora poderosos e precisos, os modelos de linguagem em larga escala (LLMs) exigem grande memória e poder de processamento, tornando-os inadequados para dispositivos com capacidades de hardware limitadas. A desativação desses modelos pode levar ao bloqueio do tempo de execução ou à falha de dispositivos móveis com DRAM limitada, o que limita severamente seu uso. Para resolver isso, os pesquisadores estão se concentrando na compactação de LLMs sem sacrificar o desempenho.
Os métodos existentes de compressão de modelos, incluindo remoção e dimensionamento, contribuíram para reduzir o tamanho dos modelos e melhorar a eficiência. A poda envolve a remoção seletiva de parâmetros irrelevantes do modelo, enquanto a calibração reduz a precisão dos pesos do modelo em formatos de poucos bits. Apesar desses avanços, muitas soluções precisam de ajuda para equilibrar efetivamente o tamanho, as demandas de computação e o desempenho de segurança, especialmente quando usadas em dispositivos de ponta.
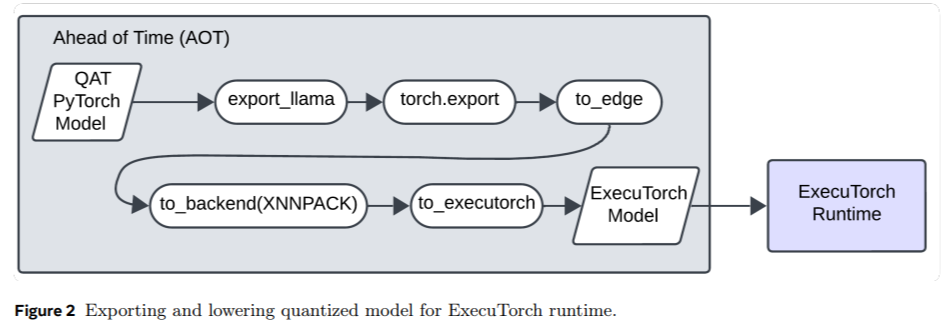
Pesquisadores da Meta presentes Guarda Lhama 3-1B-INT4modelo de avaliação de segurança concebido para enfrentar estes desafios. O modelo, apresentado durante o Meta Connect 2024, tem apenas 440 MB, o que o torna sete vezes menor que seu antecessor, o Llama Guard 3-1B. Isso é conseguido com técnicas avançadas de compactação, como remoção de bloco de decodificador, remoção em nível de neurônio e treinamento de quantização. Os pesquisadores também usaram a destilação no modelo grande Llama Guard 3-8B para restaurar a qualidade perdida durante a compressão. Notavelmente, o modelo atinge um resultado de pelo menos 30 tokens por segundo com um token-to-first de menos de 2,5 segundos em uma CPU móvel Android padrão.
Vários mecanismos importantes apoiam os avanços tecnológicos no Llama Guard 3-1B-INT4. Os métodos de poda reduziram os blocos decodificadores do modelo de 16 para 12 e o tamanho oculto do MLP de 8.192 para 6.400, atingindo uma contagem de parâmetros de 1,1 bilhão, abaixo dos 1,5 bilhões. A quantização comprimiu ainda mais o modelo, reduzindo a precisão dos pesos para INT4 e a ativação para INT8, reduzindo seu tamanho por um fator de quatro em comparação com a base de 16 bits. Além disso, a remoção da remoção da camada reduziu o tamanho da camada de saída, concentrando-se apenas nos 20 tokens necessários, mantendo a compatibilidade com as interfaces existentes. Esta configuração garantiu a aplicabilidade do modelo em dispositivos móveis sem comprometer os seus níveis de segurança.
O desempenho do Llama Guard 3-1B-INT4 enfatiza sua eficácia. Atinge uma pontuação F1 de 0,904 em conteúdo em inglês, superando seu homólogo maior, o Llama Guard 3-1B, com uma pontuação de 0,899. Para habilidades multilíngues, o modelo tem desempenho igual ou melhor que os modelos maiores em cinco dos oito idiomas testados além do inglês, incluindo francês, espanhol e alemão. Comparado ao GPT-4, testado em um ambiente de disparo zero, o Llama Guard 3-1B-INT4 apresentou as mais altas pontuações de classificação de segurança em sete idiomas. Seu tamanho reduzido e desempenho aprimorado tornam-no uma solução viável para implantação móvel e foi demonstrado com sucesso no telefone Moto-Razor.
A pesquisa destaca várias conclusões importantes, resumidas a seguir:
- Técnicas de Pressão: Métodos de poda e métodos de dimensionamento aprimorados podem reduzir o tamanho do LLM em mais de 7× sem perda significativa de precisão.
- Métricas de desempenho: O Llama Guard 3-1B-INT4 atinge uma pontuação F1 de 0,904 para inglês e pontuações comparáveis para vários idiomas, superando o GPT-4 em algumas tarefas de teste de segurança.
- Disponibilidade de Remessas: O modelo executa 30 tokens por segundo em CPUs comuns do Android com um tempo de token até o primeiro de menos de 2,5 segundos, demonstrando seu poder para aplicativos no dispositivo.
- Padrões de segurança: o modelo mantém uma forte capacidade de medir a segurança, medir a eficiência e o desempenho em conjuntos de dados multilíngues.
- Escalabilidade: O modelo permite aplicações escaláveis em dispositivos de ponta, reduzindo as demandas de computação e ampliando sua usabilidade.


Concluindo, o Llama Guard 3-1B-INT4 representa um avanço significativo em testes produtivos de segurança de IA. Enfrentando os principais desafios de tamanho, eficiência e desempenho, fornece um modelo compacto para implantação móvel, mas robusto o suficiente para garantir altos níveis de segurança. Usando novas técnicas de compressão e otimização cuidadosa, os pesquisadores criaram uma ferramenta escalonável e confiável, abrindo caminho para sistemas de IA seguros em diversas aplicações.
Confira Papel e códigos. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre o público.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


