
O ataque de inversão de modelo (MI) é um tipo de ataque de privacidade em modelos de aprendizado de máquina e aprendizado profundo, onde o invasor tenta alterar a saída do modelo para recriar os dados de treinamento confidenciais usados durante o treinamento, incluindo o vazamento de imagens faciais secretas. modelos de reconhecimento, informações confidenciais de saúde em dados médicos, informações financeiras, como registros de empregos e saldos de contas, e preferências pessoais e interações sociais em dados de mídia social, etc. levantando preocupações generalizadas sobre as ameaças à privacidade das Redes Neurais Profundas (DNNs). Infelizmente, à medida que os ataques MI se desenvolveram, não houve uma forma completa e fiável de testar e comparar estes ataques, o que torna difícil avaliar a segurança do modelo. Esta deficiência leva a comparações inadequadas entre diferentes métodos de ataque e configurações de teste consistentes. Além disso, a ausência de protocolos de testes padronizados resulta num cenário heterogêneo onde há pouca validade e justiça em estudos comparativos.
Até agora tem sido muito difícil encontrar qualquer referência que possa medir a capacidade do modelo de se defender contra tais ameaças. Embora protejam contra ataques de MI, muitos métodos existentes podem ser divididos em dois tipos: processamento de saída de modelo e treinamento robusto de modelo. O processamento de saída do modelo refere-se à redução das informações privadas disponíveis no modelo da vítima para melhorar a privacidade. Yang et al. proponho treinar um autoencoder para limpar o vetor de saída, reduzindo seu nível de dispersão. Wen et al. use sons de contador para sair do modelo e confundir os atacantes. Sim e outros. use um método de privacidade diferente para dividir o vetor de saída em múltiplas subdimensões. O treinamento de modelo forte refere-se à incorporação de estratégias defensivas durante o processo de treinamento. MID Wang et al. penaliza informações compartilhadas entre a entrada e a saída do modelo na perda de treinamento, reduzindo assim informações desnecessárias transportadas na saída do modelo que podem ser abusadas por invasores.
Os ataques e defesas de MI existentes carecem de benchmarks abrangentes, específicos e confiáveis, levando a comparações inadequadas e configurações de teste inconsistentes. Portanto, os pesquisadores introduziram um benchmark para medir a força e determinar a vulnerabilidade do modelo contra tais ataques de inversão de modelo.
Para aliviar estes problemas, investigadores do Instituto de Tecnologia UniHarbin (Shenzhen) e da Universidade de Tsinghua introduziram o primeiro benchmark no campo das MI, denominado MIBench. Para criar uma caixa de ferramentas extensível baseada em módulos, eles dividiram o pipeline ofensivo e defensivo do MI em quatro módulos principais, cada um projetado processamento de dados, métodos de ataque, estratégias de defesade novo testaro que melhora a elasticidade desta estrutura composta. O que é proposto MIBench agregar valor 16 métodos incluindo 11 métodos de ataque e 4 técnicas de defesa, combinados 9 protocolos de teste gerais para medir adequadamente o desempenho geral de métodos de MI individuais e focar em ataques de MI baseados em Rede Adversarial Generativa (GAN). Com base no acesso aos parâmetros do modelo alvo, os pesquisadores distinguem Ataques MI No meio caixa branca de novo uma caixa preta para atacar. Um ataque de caixa branca pode incluir informações completas do modelo alvo, permitindo o cálculo de gradientes para retropropagação, enquanto um ataque de caixa preta é forçado a encontrar apenas os vetores de confiança de predição do modelo alvo. EU MIBench referência inclui 8 ataques de caixa branca métodos e 4 ataques de caixa preta métodos.
Visão geral da estrutura básica da caixa de ferramentas baseada no módulo de benchmark MIB
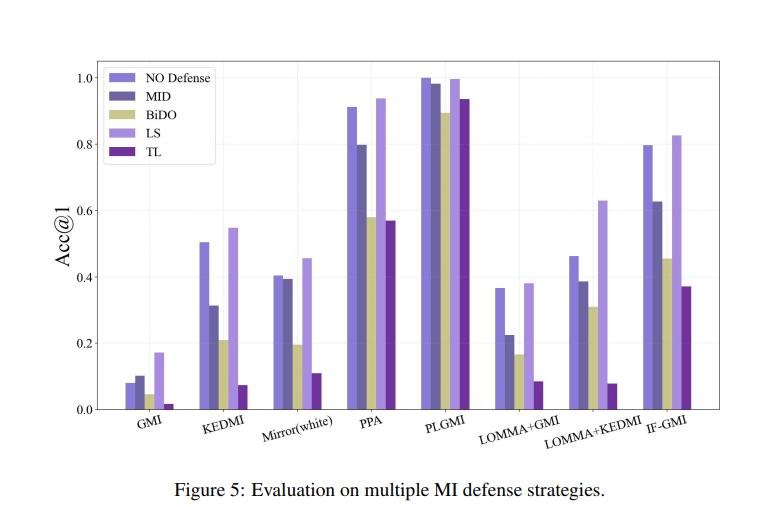
Os pesquisadores testaram estratégias de ataque MI em dois modelos (IR-152 porque baixo e ResNet-152 com alta resolução) usando conjuntos de dados públicos e privados. Parâmetros como precisão, distância do recurso e FID foram usados para comparar ataques de caixa branca e caixa preta para validar o método. Métodos fortes como PLGMI de novo LOKT mostrou alta precisão, enquanto PPA de novo C2FMI produzir imagens realistas, especialmente em alta resolução. Foi observado pelos pesquisadores que a eficácia dos ataques de MI aumentou com o poder do modelo de previsão. As técnicas de segurança atuais não têm sido totalmente eficazes, destacando a necessidade de melhores formas de proteger a privacidade sem reduzir a precisão do modelo.

Concluindo, um benchmark reprodutível facilitará o desenvolvimento do campo de MI e trará novos experimentos para as próximas pesquisas. No futuro, o MIBench pode fornecer uma caixa de ferramentas compacta, eficiente e extensível e será amplamente utilizado por pesquisadores nesta área para testar e comparar rigorosamente seus novos métodos, garantir medições iguais e, assim, impulsionar o progresso no desenvolvimento futuro.
No entanto, um potencial impacto negativo do benchmark MIB é que usuários mal-intencionados podem usar métodos de ataque para recriar dados confidenciais de sistemas públicos. Para lidar com isso, os usuários de dados precisam implementar estratégias e métodos de segurança robustos e confiáveis. Além disso, definir controlos de acesso e limitar a frequência com que cada utilizador pode aceder aos dados é importante para construir sistemas de IA responsáveis e reduzir potenciais conflitos com dados humanos privados.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
![OCR (Ocline Character Recognition) – Definição, vantagens, desafios e casos de uso [Infographic]](https://i0.wp.com/f5b623aa.rocketcdn.me/wp-content/uploads/2022/09/Blog-SM_What-is-OCR.jpg?w=320&resize=320,200&ssl=1 "OCR (Ocline Character Recognition) – Definição, vantagens, desafios e casos de uso [Infographic]")

