
Nos últimos anos, os modelos linguísticos de grande escala (LLMs) mostraram progressos significativos numa variedade de aplicações, desde a geração de texto até à resposta a consultas. No entanto, uma área importante a ser melhorada é garantir que esses modelos sigam com precisão instruções específicas durante as operações, como ajustar o formato, o tom ou a duração do conteúdo. Isso é especialmente importante em setores como jurídico, de saúde ou de tecnologia, onde é essencial produzir textos que sigam diretrizes rígidas.
A incapacidade dos modelos de linguagem de seguir instruções detalhadas durante a execução do script é um problema importante. Embora os modelos possam compreender informações gerais, muitas vezes precisam de ajuda para cumprir determinados parâmetros, como requisitos de formatação, extensão do conteúdo ou inclusão ou exclusão de determinados critérios. Esta lacuna entre as capacidades do modelo e as expectativas do usuário apresenta um grande desafio para os pesquisadores. Ao lidar com tarefas complexas que envolvem vários comandos, os modelos atuais podem afastar-se das restrições iniciais ao longo do tempo ou falhar completamente, reduzindo a fiabilidade dos seus resultados.
Várias tentativas têm sido feitas para lidar com esse problema, principalmente através do uso de métodos de ensino. Isso inclui modelos de treinamento em conjuntos de dados com instruções incorporadas, permitindo-lhes compreender e aplicar restrições subjacentes a tarefas em tempo real. No entanto, embora esta abordagem tenha demonstrado algum sucesso, requer mais flexibilidade e luta com direções complexas, especialmente quando múltiplos obstáculos são usados simultaneamente. Além disso, os modelos ativados por instrução muitas vezes precisam ser treinados novamente em grandes conjuntos de dados, o que consome tempo e muitos recursos. Esta limitação reduz a sua eficácia em situações reais e de ritmo acelerado, onde é necessário um processamento rápido de instruções.
Pesquisadores da ETH Zürich e da Microsoft Research introduziram uma nova maneira de lidar com essas limitações: orientação de ativação. Esta abordagem evita a necessidade de retreinar os modelos para cada novo conjunto de instruções. Em vez disso, apresenta uma solução dinâmica que ajusta o funcionamento interno do modelo. Os pesquisadores podem calcular vetores específicos que capturam as mudanças desejadas analisando as diferenças em como o modelo de linguagem se comporta quando recebe uma instrução e não recebe. Esses vetores podem ser usados durante a inferência, orientando o modelo a seguir novas restrições sem exigir modificação da estrutura central do modelo ou retreinamento em novos dados.
A orientação de ativação funciona identificando e manipulando as camadas internas do modelo responsáveis por seguir as instruções. Quando o modelo recebe informações, ele as processa por meio de múltiplas camadas de redes neurais, onde cada camada refina a compreensão da tarefa pelo modelo. O mecanismo de ativação rastreia essas alterações internas e aplica as alterações necessárias às principais áreas dessas camadas. Os vetores de direção atuam como um mecanismo de controle, ajudando o modelo a permanecer no caminho certo com instruções específicas, seja formatando o texto, limitando seu comprimento ou garantindo que determinados termos sejam incluídos ou excluídos. Esta abordagem modular permite um controle ajustado, o que possibilita modificar o comportamento do modelo durante a tomada de decisões sem exigir um extenso pré-treinamento.

Testes de desempenho realizados em três modelos de linguagem principais – Phi-3, Gemma 2 e Mistral – mostraram a eficácia da orientação de ativação. Por exemplo, os modelos mostraram uma melhor adesão às instruções, mesmo sem instruções explícitas na entrada, e os níveis de precisão aumentaram 30% em comparação com o seu desempenho inicial. Quando receberam instruções claras, os modelos apresentaram aderência ainda maior, com 60% a 90% de precisão no seguimento de obstáculos. O teste se concentra em vários tipos de instruções, incluindo formato de saída, texto ou saída e comprimento do conteúdo. Por exemplo, se você tiver a tarefa de gerar texto em um formato específico, como JSON, os modelos poderão armazenar a estrutura necessária com mais frequência com uma diretiva de ativação do que sem ela.
Outra descoberta importante é que a orientação de abertura permite que os modelos lidem com múltiplos obstáculos simultaneamente. Esta é uma grande melhoria em relação aos métodos anteriores, que muitas vezes falham quando mais de uma instrução é usada ao mesmo tempo. Por exemplo, os pesquisadores mostraram que o modelo pode aderir às restrições de formatação e comprimento ao mesmo tempo, o que teria sido fácil de conseguir com os métodos anteriores. Outro resultado importante foi a capacidade de transferir vetores de direção entre modelos. Vetores de direção computadorizados para modelos ativados por instrução foram aplicados com sucesso a modelos básicos, melhorando seu desempenho sem retreinamento adicional. Esta transferência sugere que a orientação de ativação pode desenvolver uma gama mais ampla de modelos em diferentes aplicações, tornando a abordagem mais versátil.
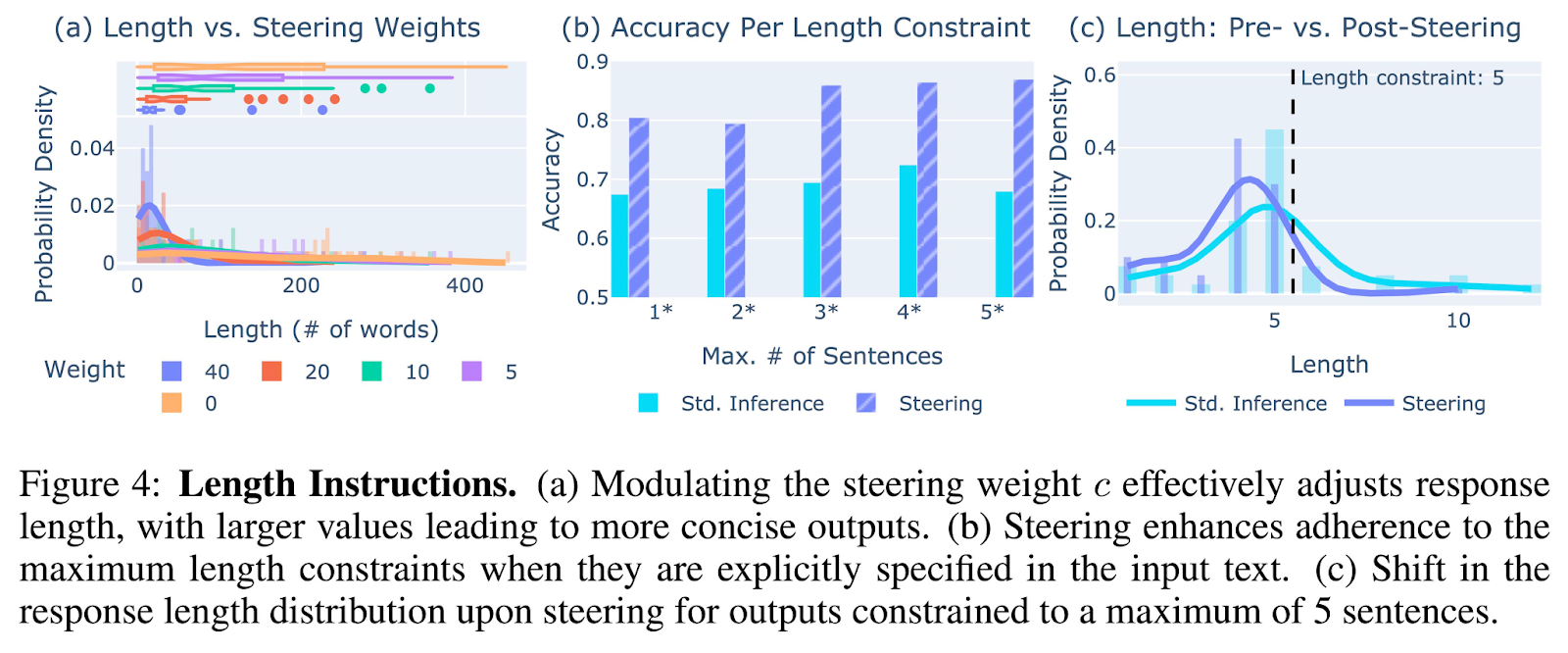
Concluindo, o estudo representa um avanço importante no campo da PNL, fornecendo uma solução confiável e flexível para melhorar o acompanhamento da instrução em modelos de linguagem. Usando o controle de circuito aberto, pesquisadores da ETH Zürich e da Microsoft Research demonstraram que os modelos podem ser modificados de forma flexível para seguir instruções específicas, melhorando sua usabilidade em aplicações do mundo real onde a precisão é crítica. A abordagem melhora a capacidade dos modelos de lidar com vários problemas simultaneamente e reduz a necessidade de reciclagem extensiva, proporcionando uma forma mais eficiente de controlar o resultado da produção linguística. Estas descobertas abrem novas oportunidades para usar LLMs em campos que exigem alta precisão e adesão às diretrizes.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


