
A pesquisa em inteligência artificial viu avanços revolucionários na reflexão e compreensão de tarefas complexas. Os desenvolvimentos mais recentes são linguagens modelo de grande escala (LLMs) e linguagens multimodelo de grande escala (MLLMs). Esses sistemas podem processar dados visuais e de texto, permitindo-lhes analisar tarefas complexas. Ao contrário dos métodos tradicionais que apoiam as suas capacidades de pensamento de forma verbal, os sistemas multimodais tentam simular a compreensão humana combinando o pensamento escrito e o pensamento visual, portanto, podem ser utilizados de forma eficaz para resolver vários desafios.
O problema até agora é que estes modelos não conseguem ligar o pensamento textual e visual em ambientes dinâmicos. Os modelos desenvolvidos para inferência funcionam bem com entradas baseadas em texto ou imagens, mas não podem ser executados simultaneamente quando ambos são inseridos. Tarefas de raciocínio espacial, como navegação em labirintos ou interpretação de estruturas dinâmicas, mostram fraquezas nesses modelos. As capacidades de pensamento integrado não podem ser acomodadas nestes modelos. Portanto, cria limitações na transformação e interpretação de modelos, principalmente quando a tarefa é compreender e gerenciar padrões visuais e instruções dadas por palavras.
Várias abordagens foram propostas para lidar com esses problemas. As informações da cadeia de pensamento (CoT) desenvolvem o pensamento, gerando uma sequência textual passo a passo. É baseado em script por natureza e não realiza tarefas que exijam conhecimento local. Outros métodos de entrada visual são ferramentas externas, como legendas de imagens ou geração de gráficos de cena, que permitem que os modelos processem dados visuais e textuais. Embora eficientes até certo ponto, estes métodos dependem fortemente de módulos visuais separados, tornando-os inflexíveis e propensos a erros para tarefas complexas.
Pesquisadores da Microsoft Research, da Universidade de Cambridge e da Academia Chinesa de Ciências introduziram a estrutura de Visualização Multimodal do Pensamento (MVoT) para resolver essas limitações. Este novo paradigma de pensamento permite que os modelos gerem trilhas de pensamento verbais e integradas, proporcionando uma abordagem integrada ao pensamento multimodal. O MVoT incorpora o poder do raciocínio visual diretamente na modelagem, eliminando assim a dependência de ferramentas externas e tornando-o uma solução mais integrada para tarefas de raciocínio complexas.

Usando Chameleon-7B, um MLLM automatizado ajustado para tarefas de múltiplas inferências, os pesquisadores implementaram o MVoT. Essa abordagem envolve tokenização com perdas para preencher a lacuna representacional entre os processos de tokenização de texto e imagem para extrair recursos visuais de qualidade. O MVoT processa entradas multimodais passo a passo, criando trilhas de pensamento verbal e visual. Por exemplo, em tarefas espaciais como navegação em labirintos, o modelo gera pistas visuais que complementam as etapas cognitivas, melhorando tanto a interpretação quanto o desempenho. Esta capacidade tradicional de pensamento visual, integrada na estrutura, torna-a mais semelhante à compreensão humana, proporcionando assim uma forma intuitiva de compreender e resolver tarefas complexas.
O MVoT superou os modelos de última geração em testes extensivos de diversas tarefas de raciocínio espacial, incluindo MAZE, MINI BEHAVIOR e FROZEN LAKE. A estrutura alcançou uma alta precisão de 92,95% em tarefas de navegação em labirinto, o que supera os métodos CoT padrão. Na tarefa MINI BEHAVIOR que requer compreensão das interações com estruturas locais, o MVoT alcançou uma precisão de 95,14%, demonstrando seu desempenho em ambientes dinâmicos. No projeto FROZEN LAKE, que é conhecido por sua complexidade devido aos finos detalhes espaciais, a robustez do MVoT atingiu uma precisão de 85,60%, superando o CoT e outros benchmarks. O MVoT melhorou consistentemente em situações desafiadoras, especialmente aquelas que envolviam padrões visuais complexos e raciocínio espacial.
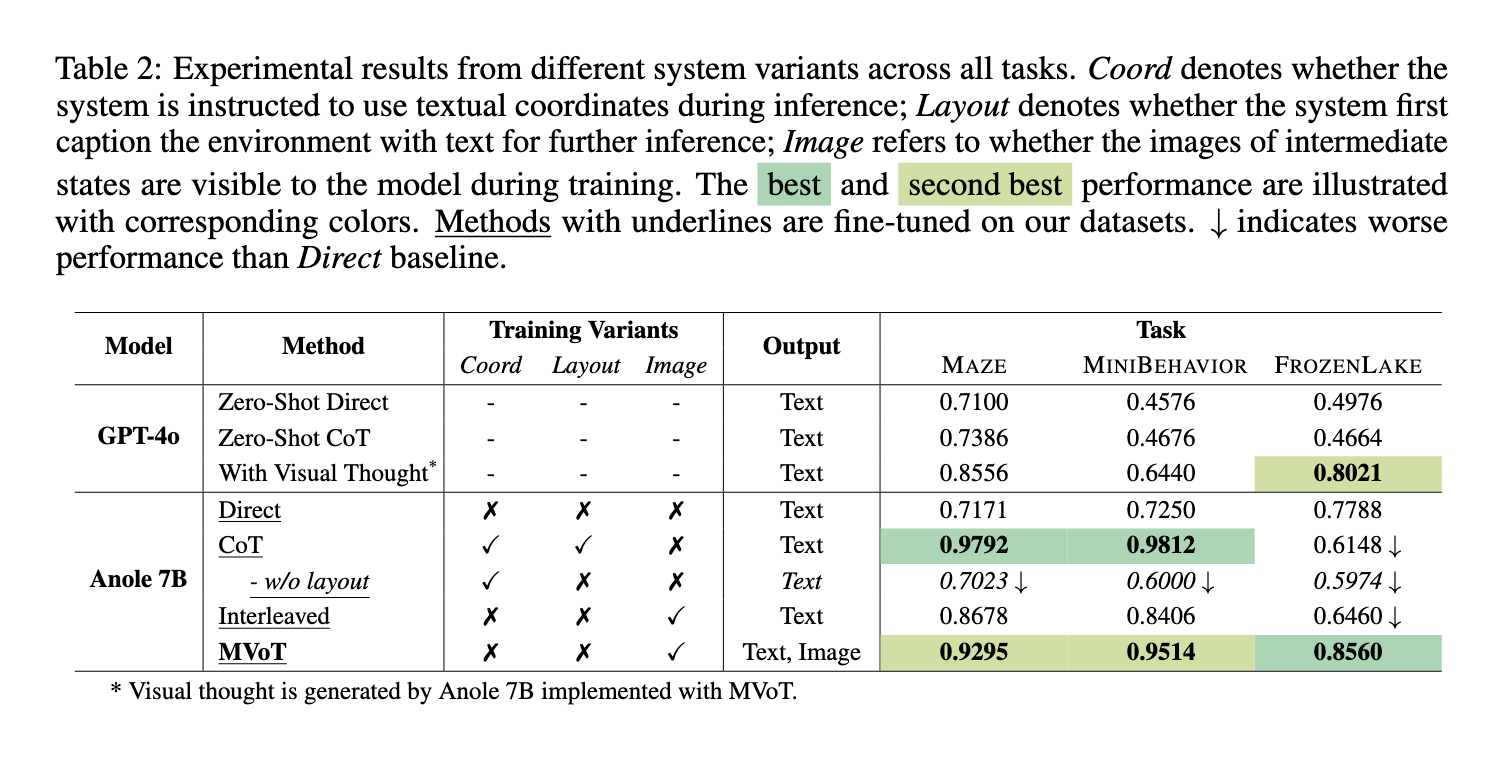
Além das métricas de desempenho, o MVoT demonstrou uma interpretação melhorada ao produzir traços de pensamento visual que complementam o raciocínio verbal. Essa capacidade permitiu aos usuários acompanhar visualmente o processo de pensamento do modelo, facilitando a compreensão e a verificação de suas conclusões. Ao contrário do CoT, baseado apenas na descrição do texto, a abordagem de raciocínio multimodal do MVoT reduziu os erros causados pela representação incorreta do texto. Por exemplo, no projeto FROZEN LAKE, o MVoT manteve um desempenho estável no aumento da complexidade do seu ambiente, demonstrando assim robustez e confiabilidade.

Esta pesquisa, portanto, redefine o escopo das capacidades de pensamento da inteligência artificial através do MVoT, integrando texto e visão em tarefas de pensamento. O uso da perda de disparidade de token garante que o raciocínio visual seja facilmente compatível com o processamento de texto. Isto preencherá uma lacuna importante nos métodos atuais. Maior desempenho e melhor interpretabilidade marcarão o MVoT como um passo marcante em direção ao pensamento multimodal que pode abrir portas para sistemas de IA complexos e desafiadores em situações do mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 Recomende uma plataforma de código aberto: Parlant é uma estrutura que muda a forma como os agentes de IA tomam decisões em situações voltadas para o cliente. (Promovido)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
📄 Conheça 'Height': ferramenta independente de gerenciamento de projetos (patrocinado)


: um salto semântico além da modelagem de linguagem baseada em tokens")