
Multilínguas multiníveis (MLLMs) estão se desenvolvendo rapidamente, permitindo que as máquinas interpretem e raciocinem com texto e dados visuais simultaneamente. Esses modelos têm aplicações transformadoras na análise de imagens, respondendo a questões visuais e raciocínio multidimensional. Ao preencherem a lacuna entre a percepção e a linguagem, desempenham um papel importante no desenvolvimento da capacidade da inteligência artificial de compreender e interagir com o mundo.
Apesar da sua promessa, estes programas precisam de superar desafios significativos. A principal limitação é a dependência da supervisão da linguagem natural para o treinamento, o que muitas vezes resulta em representações visuais de baixa qualidade. Embora o aumento do tamanho do conjunto de dados e da complexidade computacional tenha levado a melhorias limitadas, eles precisam de um desenvolvimento mais direcionado para a compreensão visual desses modelos, a fim de garantir que alcancem o desempenho esperado em tarefas baseadas na visão. Os métodos atuais geralmente exigem equilibrar a eficiência computacional com melhor desempenho.
As técnicas existentes para treinar MLLMs geralmente envolvem o uso de codificadores visuais para extrair características de imagens e inseri-las em um modelo de linguagem em conjunto com dados de linguagem natural. Outros métodos usam codificadores mais visuais ou métodos de atenção para melhorar a compreensão. No entanto, esses métodos têm o custo de dados e requisitos computacionais muito elevados, limitando sua escalabilidade. Esta ineficiência enfatiza a necessidade de um método mais eficiente de desenvolvimento de MLLMs para compreensão visual.
Pesquisadores do SHI Labs da Georgia Tech e da Microsoft Research introduziram um novo método chamado OLA-VLM para enfrentar esses desafios. Esta abordagem visa melhorar os MLLMs integrando informações visuais auxiliares em suas camadas ocultas durante o pré-treinamento. Em vez de aumentar a complexidade do codificador visual, o OLA-VLM propõe a incorporação para melhorar a compatibilidade dos dados visuais e textuais. A introdução dessa otimização nas camadas intermediárias do modelo de linguagem garante uma melhor inferência visual sem sobrecarga computacional adicional durante a inferência.
A tecnologia por trás do OLA-VLM envolve a incorporação de funções com perdas para melhorar as representações de codificadores visuais especiais. Esses codificadores são treinados para segmentação de imagens, estimativa de profundidade e tarefas de geração de imagens. Recursos dissolvidos são criados para camadas específicas do modelo de linguagem usando métodos de incorporação preditiva. Além disso, tokens específicos de tarefas são adicionados às sequências de entrada, permitindo que o modelo integre informações auxiliares visuais perfeitamente. Este design garante que os recursos visuais sejam incorporados com sucesso na apresentação do MLLM sem comprometer o objetivo principal do treinamento de predição de token subsequente. O resultado é um modelo que aprende uma representação forte e ancora a visão.
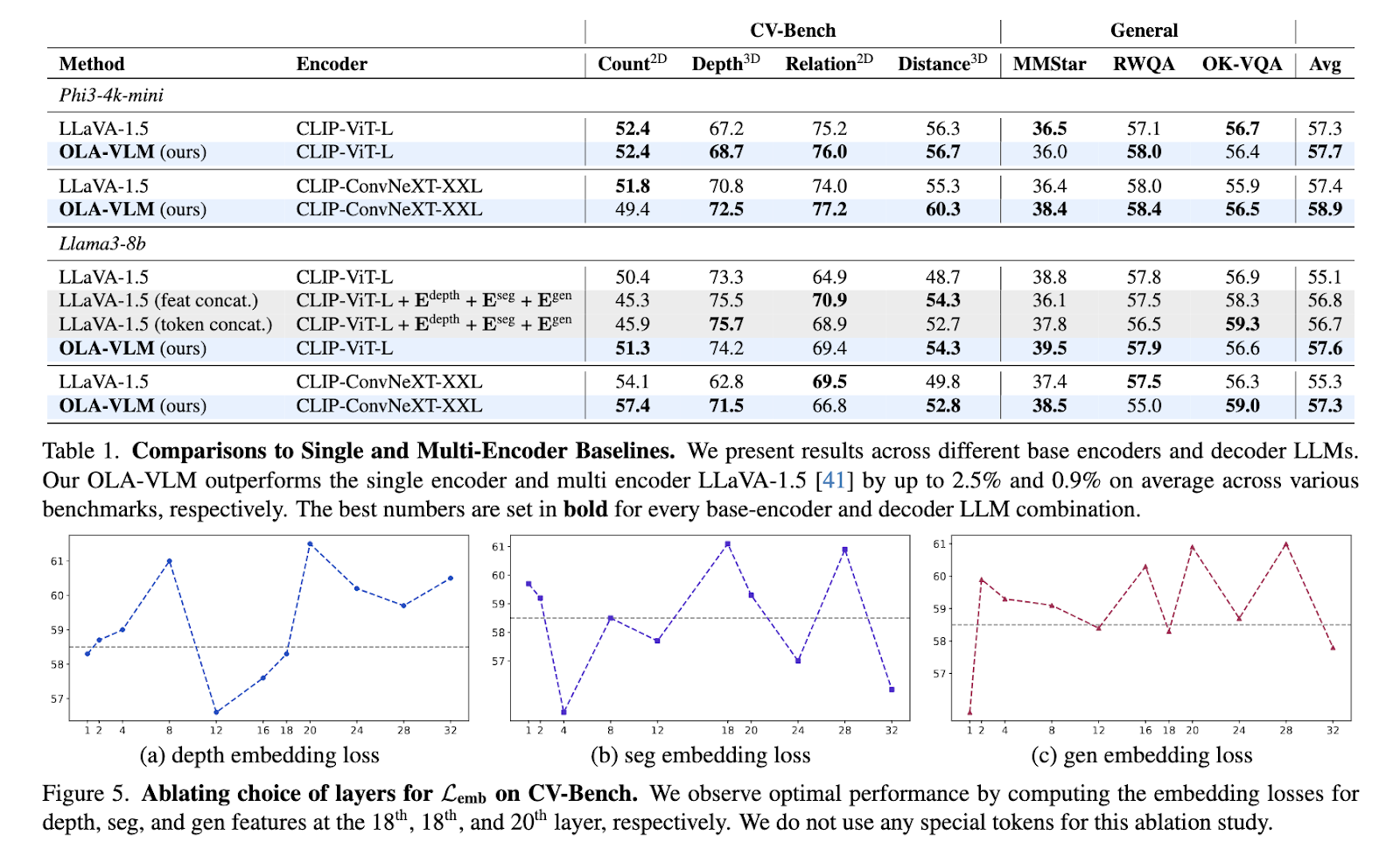
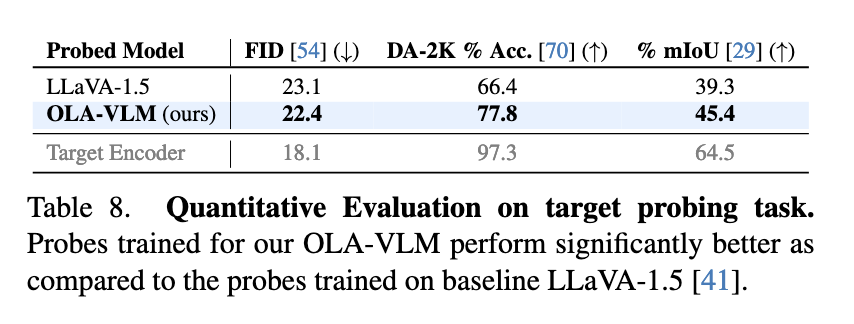
O desempenho do OLA-VLM foi rigorosamente testado em vários benchmarks, mostrando melhorias significativas em relação aos modelos existentes de codificador único. No CV-Bench, um conjunto de benchmark centrado na visão, o OLA-VLM superou o LLaVA-1.5 de linha de base em até 8,7% em tarefas de medição profunda, alcançando 77,8% de precisão. Em tarefas de segmentação, alcançou uma classificação média de Interseção sobre União (mIoU) de 45,4%, uma melhoria significativa em relação aos 39,3%. O modelo também mostrou ganhos consistentes em tarefas de visão 2D e 3D, alcançando uma melhoria média de até 2,5% em benchmarks como distância e raciocínio relativo. O OLA-VLM alcançou esses resultados usando apenas um codificador durante a previsão, tornando-o mais eficiente do que vários esquemas de incorporação.
Para garantir a sua eficácia contínua, os investigadores analisaram as representações recebidas pelo OLA-VLM. Testes experimentais revelaram que o modelo alcançou o maior alinhamento de características visuais em suas camadas intermediárias. Esse alinhamento melhorou muito o desempenho do modelo downstream em diversas funções. Por exemplo, os pesquisadores observaram que a combinação de tokens específicos de tarefas durante o treinamento contribuiu para melhorias nos recursos de profundidade, segmentação e tarefas de produção de imagens. Os resultados enfatizaram a eficácia do método de incorporação preditiva, comprovando sua capacidade de medir percepção visual de alta qualidade e eficiência computacional.
OLA-VLM estabelece um novo padrão para integração de informações visuais em MLLMs, concentrando-se na otimização incorporada durante o pré-treinamento. Este estudo aborda uma lacuna nos métodos de treinamento atuais, introduzindo uma visão em perspectiva para melhorar a qualidade da representação visual. O método proposto melhora o desempenho de tarefas de percepção de linguagem e consegue isso com menos recursos computacionais em comparação aos métodos existentes. OLA-VLM é um exemplo de como a otimização de alvos durante o treinamento pode melhorar significativamente o desempenho de um modelo multimodal.
Concluindo, um estudo realizado pela SHI Labs e pela Microsoft Research destaca os avanços inovadores na IA multimodal. Ao melhorar as representações visuais nos MLLMs, o OLA-VLM preenche uma lacuna crítica em desempenho e eficiência. Esta abordagem mostra como uma melhor incorporação pode resolver eficazmente os desafios no alinhamento da linguagem visual, abrindo caminho para sistemas multimodais robustos e incontroláveis no futuro.
Confira eu Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


