
A combinação de visão e processamento de linguagem em IA tornou-se a base para o desenvolvimento de sistemas que podem compreender simultaneamente dados visuais e textuais, ou seja, dados multimodais. Este campo interdisciplinar concentra-se em permitir que máquinas interpretem imagens, extraiam informações textuais relevantes e reconheçam relações espaciais e contextuais. Estas capacidades prometem remodelar as aplicações do mundo real, colmatando a lacuna de compreensão visual e linguística dos veículos autónomos até aos sistemas avançados de interação humano-computador.
Apesar de muitas conquistas neste campo, ele enfrenta desafios significativos. Muitos modelos priorizam a compreensão semântica de alto nível das imagens, capturando as descrições gerais da cena, mas muitas vezes observando informações detalhadas em pixels ou em nível de região. Esta omissão prejudica o seu desempenho em tarefas especializadas que requerem compreensão complexa, como extrair texto de imagens ou compreender relações entre objetos espaciais. Além disso, combinar vários codificadores de visão para resolver esses problemas geralmente resulta em ineficiências estatísticas, aumentando a complexidade do treinamento e da implantação.
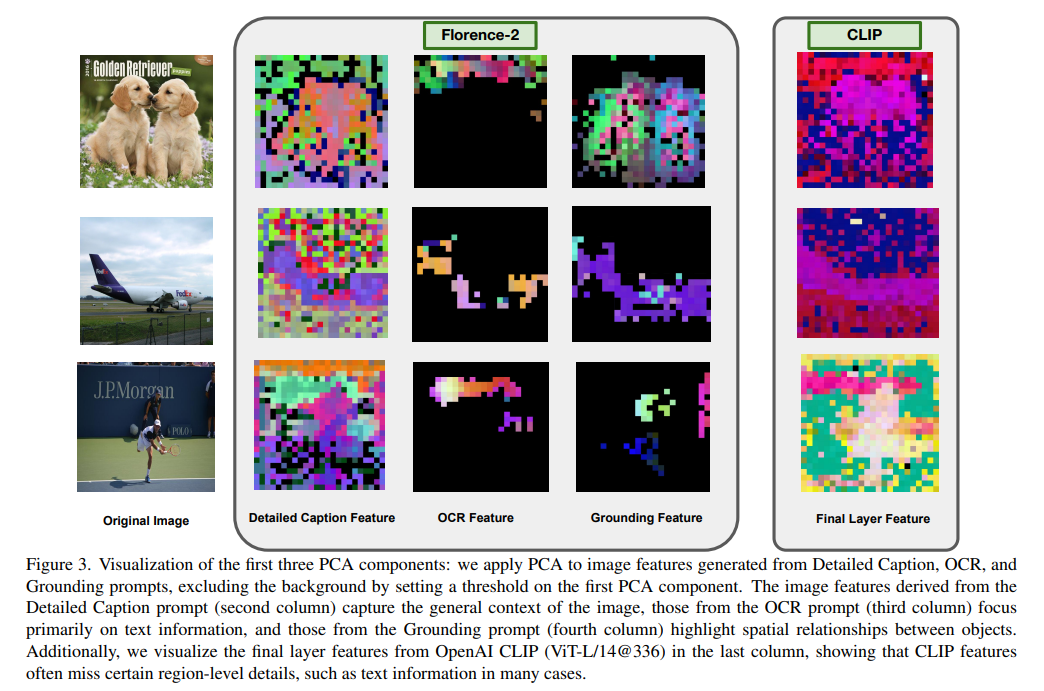
Ferramentas como o CLIP historicamente estabeleceram a referência para alinhar representações visuais e textuais usando diferentes treinamentos anteriores. Embora funcione bem para tarefas gerais, a dependência do CLIP em recursos semânticos de camada única limita sua adaptabilidade a vários desafios. Métodos avançados introduziram modelos de automonitoramento e classificação que abordam tarefas específicas, mas muitas vezes dependem de vários códigos, o que pode aumentar as demandas computacionais. Estas limitações realçam a necessidade de uma abordagem flexível e eficiente que equilibre a generalização e a precisão específica da tarefa.
Pesquisadores da Universidade de Maryland e da Microsoft apresentaram Florença-VLuma estrutura única para enfrentar esses desafios e melhorar a integração da linguagem visual. Este modelo usa um codificador de visão básico, Florence-2, para fornecer representações visuais específicas de tarefas. Este codificador se afasta dos métodos convencionais ao usar uma abordagem baseada em conhecimento, permitindo-nos integrar seus recursos em diversas tarefas, como legendagem de imagens, detecção de objetos e reconhecimento óptico de caracteres (OCR).
A chave para a eficiência do Florence-VL é seu método Depth-Breadth Fusion (DBFusion), que integra elementos visuais em camadas e instruções. Esta abordagem dupla garante que o modelo capture informações granulares e de alto nível, levando em consideração as diferentes funções da linguagem visual. Os recursos profundos são derivados de camadas sucessivas, fornecendo informações visuais detalhadas, enquanto os recursos amplos são extraídos usando informações específicas da tarefa, garantindo adaptabilidade a diversas situações e desafios. Florence-VL combina esses recursos de forma eficaz usando uma estratégia de cluster baseada em canal, mantendo a computação simples sem sacrificar o desempenho. O treinamento extensivo em 16,9 milhões de legendas de imagens e 10 milhões de conjuntos de dados de instruções melhora os recursos do modelo. Ao contrário dos modelos tradicionais que congelam certas partes durante o treino, o Florence-VL ajusta toda a sua estrutura durante o treino, conseguindo uma melhor compatibilidade entre métodos visuais e textuais. Sua seção de planejamento de instruções aumenta sua capacidade de adaptação a tarefas posteriores, apoiada por conjuntos de dados de alta qualidade selecionados para aplicações específicas.
Florence-VL foi testado em todos os 25 benchmarks, incluindo resposta visual a consultas, OCR e tarefas de compreensão de gráficos. Obteve uma perda de alinhamento de 2,98, que supera significativamente modelos como LLaVA-1.5 e Cambrain-8B. A variante Florence-VL 3B teve um bom desempenho em 12 das 24 tarefas testadas, enquanto a versão maior 8B superou consistentemente a concorrência. Seus resultados nos benchmarks OCRBench e InfoVQA sublinham sua capacidade de extrair e interpretar informações de texto de imagens com precisão incomparável.
As principais conclusões do estudo Florence-VL são as seguintes:
- Codificação Unificada: um codificador de visualização única reduz a complexidade enquanto mantém a flexibilidade específica da tarefa.
- Flexibilidade Específica do Trabalho: A abordagem baseada em reconhecimento suporta uma variedade de aplicações, incluindo OCR e digitalização.
- Estratégia de fusão avançada: DBFusion garante uma rica combinação de recursos de profundidade e amplitude, capturando informações granulares e contextuais.
- Resultados de alto benchmark: Florence-VL lidera desempenho em 25 benchmarks, alcançando uma perda de alinhamento de 2,98.
- Treinamento para o sucesso: O ajuste fino de toda a arquitetura durante o pré-treinamento melhora a compreensão multimodal, proporcionando melhores resultados nas tarefas.

Concluindo, Florence-VL aborda limitações importantes dos modelos de linguagem visual existentes, introduzindo uma nova abordagem que integra com sucesso recursos visuais granulares e de alto nível. O modelo multimodal garante flexibilidade específica para tarefas usando Florence-2 como seu codificador de visão generativo e usa o método Depth-Breadth Fusion (DBFusion), mantendo a eficiência computacional. Florence-VL se destaca em todas as diferentes aplicações, como OCR e resposta visual a consultas, alcançando desempenho superior em todos os 25 benchmarks.
Confira eu Papel, Demonstraçãode novo Página GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 [Must Attend Webinar]: 'Transforme provas de conceito em aplicativos e agentes de IA prontos para produção' (Promovido)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
🚨🚨 WEBINAR DE IA GRATUITO: 'Acelere suas aplicações LLM com deepset e Haystack' (promovido)


