 para geração eficiente de dados incorporados em grande escala")
A incorporação de texto, um foco central no processamento de linguagem natural (PNL), converte texto em vetores numéricos que capturam o significado essencial de palavras ou frases. Essa incorporação permite que as máquinas processem operações de linguagem, como classificação, combinação, recuperação e resumo. Ao organizar os dados em formato vetorial, a incorporação fornece uma maneira cada vez mais eficiente para as máquinas interpretarem e agirem de acordo com a linguagem humana, melhorando a compreensão da máquina em aplicações que vão desde a análise de sentimentos até sistemas de recomendação.
Um grande desafio na incorporação de texto é gerar a grande quantidade de dados de treinamento de alta qualidade necessários para desenvolver modelos robustos. Rotular manualmente grandes conjuntos de dados é caro e demorado e, embora a geração de dados sintéticos ofereça uma solução potencial, muitas abordagens dependem fortemente de modelos de linguagem proprietários, como o GPT-4. Estes métodos, embora eficientes, representam uma barreira de custos significativa devido ao grande número de recursos necessários para executar modelos em grande escala, tornando as tecnologias de incorporação avançadas inacessíveis à comunidade de investigação mais ampla e limitando as oportunidades de refinamento e adaptação dos métodos de incorporação.
A maioria dos métodos atuais para gerar dados de treinamento para modelos de incorporação dependem de modelos linguísticos de grande escala (LLMs) para gerar texto sintético. Por exemplo, o GPT-4 gera trigêmeos – perguntas combinadas com documentos negativos e fortes – para produzir exemplos diversos e contextualmente ricos. Esta abordagem, embora poderosa, acarreta elevados custos computacionais e envolve frequentemente modelos de caixa negra, que limitam a capacidade dos investigadores de desenvolver e adaptar o processo às suas necessidades específicas. Essa dependência de modelos proprietários pode limitar a escalabilidade e a eficiência, destacando a necessidade de alternativas novas e conscientes dos recursos que mantenham a qualidade dos dados sem custos excessivos.
Pesquisadores da Gaoling School of Artificial Intelligence e da Microsoft Corporation introduziram uma nova estrutura chamada SPEED. Essa abordagem usa modelos pequenos e de código aberto para gerar dados incorporados de alta qualidade e, ao mesmo tempo, reduzir significativamente os requisitos de recursos. Ao substituir modelos proprietários dispendiosos por uma alternativa eficiente e de código aberto, o SPEED visa democratizar o acesso à geração de dados sintéticos de risco. Esta estrutura foi projetada para produzir dados de treinamento de incorporação de texto altamente eficientes, usando menos de um décimo das chamadas de API exigidas por LLMs proprietários.
O SPEED trabalha com um pipeline estruturado composto por três componentes principais: um gerador mínimo, um gerador máximo e um atualizador de dados. O processo começa com o agrupamento de trabalhos e a criação de dados iniciais, onde o GPT-4 é usado para desenvolver as descrições dos vários trabalhos. Essas especificações formam um conjunto de instruções básicas, que fornecem um pequeno modelo de produção com ajuste fino supervisionado para gerar dados sintéticos iniciais e de baixo custo. Os dados produzidos pelo micromodelo são então processados por um gerador avançado, que utiliza configurações de preferência para melhorar a qualidade com base nos sinais de teste fornecidos pelo GPT-4. Na fase final, o modelo de revisão de dados melhora estes resultados, aborda quaisquer inconsistências ou problemas de qualidade e melhora o alinhamento e a qualidade dos dados gerados. Esse processo permite que o SPEED integre dados com eficiência e alinhe modelos pequenos e de código aberto com requisitos de tarefas normalmente gerenciados por modelos proprietários grandes.
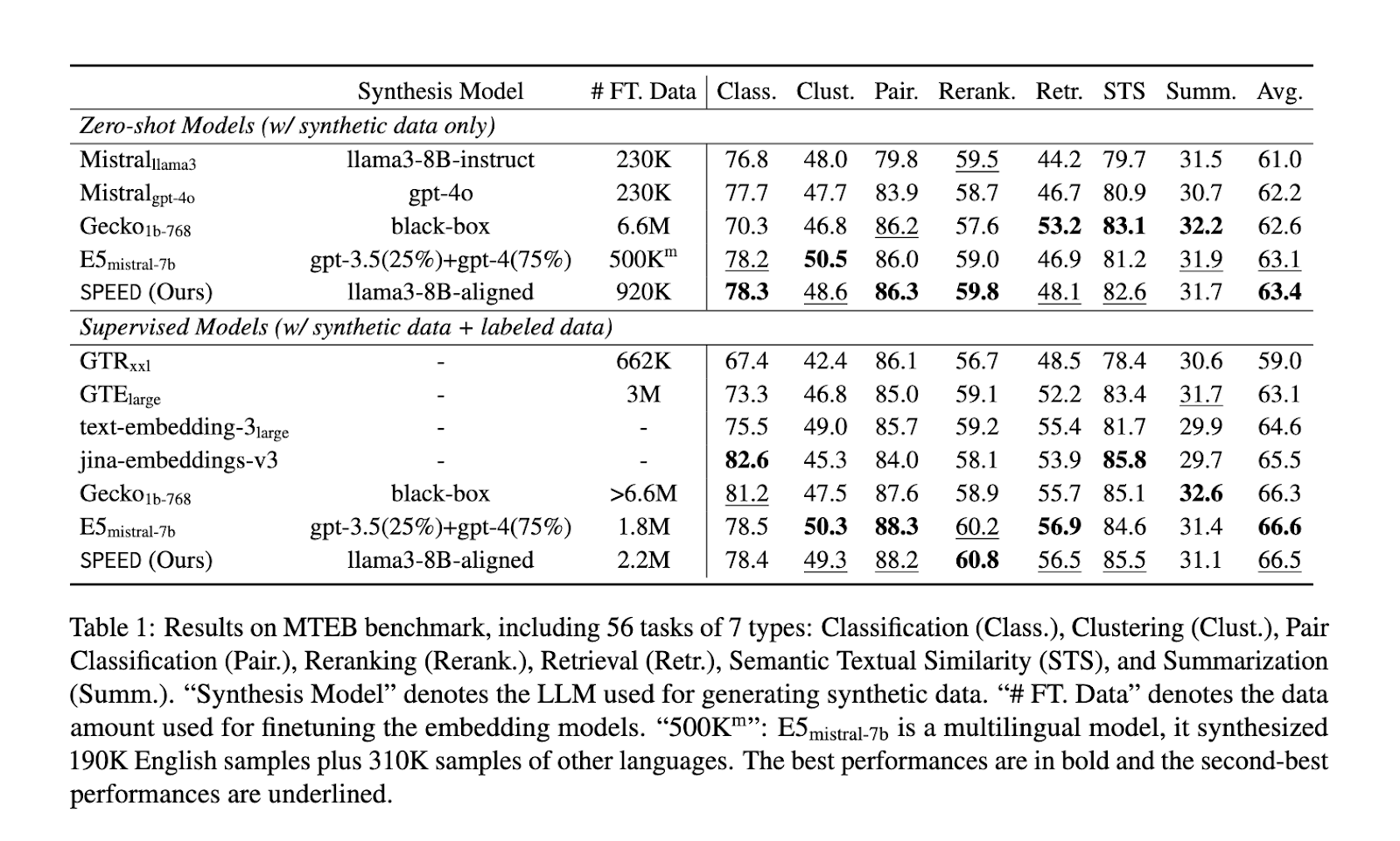
Os resultados do SPEED mostram melhorias significativas na qualidade de incorporação, economia de custos e durabilidade. O SPEED superou o modelo de incorporação líder, o E5mistral, com muito menos recursos. O SPEED conseguiu isso usando apenas 45.000 chamadas de API, em comparação com 500.000 do E5mistral, representando uma redução de custos de mais de 90%. No Massive Text Embedding Benchmark (MTEB), o SPEED apresentou um desempenho médio de 63,4 para todas as tarefas, incluindo classificação, agrupamento, recuperação e classificação de pares, ressaltando a alta flexibilidade e qualidade do modelo. O SPEED alcançou os melhores resultados em todos os diferentes benchmarks e tipos de trabalho em configurações zero-shot, correspondendo de perto ao desempenho de modelos proprietários de alta utilidade, apesar de sua estrutura de baixo custo. Por exemplo, o desempenho do SPEED atingiu 78,4 em tarefas de classificação, 49,3 em agrupamento, 88,2 em bissecção, 60,8 em reorganização, 56,5 em recuperação, 85,5 em correspondência semântica de texto e 31,1 em sumarização, o que o coloca em todas as categorias competitivas.
O SPEED Framework oferece uma alternativa eficaz e econômica para a comunidade da PNL. Ao alcançar a integração de dados de alta qualidade por uma fração do custo, os pesquisadores podem ter uma maneira eficiente, escalonável e acessível de treinar modelos de incorporação sem depender de tecnologia proprietária e cara. As técnicas de alinhamento e otimização de preferências do SPEED demonstram a viabilidade de treinar modelos pequenos e de código aberto para atender às necessidades complexas de processamento de dados sintéticos, tornando este método um recurso importante para o desenvolvimento de tecnologias de incorporação e facilitando o amplo acesso a ferramentas sofisticadas de PNL.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


