
A pesquisa em inteligência artificial (IA) tem se concentrado cada vez mais em melhorar a eficiência e a robustez dos modelos de aprendizagem profunda. Esses modelos revolucionaram o processamento de linguagem natural, a visão computacional e a análise de dados, mas apresentam desafios computacionais significativos. Especificamente, à medida que os modelos crescem, eles exigem mais recursos computacionais para processar grandes conjuntos de dados. Técnicas como retropropagação são importantes para treinar esses modelos otimizando seus parâmetros. No entanto, os métodos tradicionais lutam para dimensionar modelos de aprendizagem profunda de forma eficaz, sem incorrer em gargalos de desempenho ou exigir muito poder computacional.
Um dos principais problemas dos modelos atuais de aprendizagem profunda é a dependência de computação densa, que ativa todos os parâmetros do modelo simultaneamente durante o treinamento e a interpretação. Este método não funciona bem no processamento de dados em grande escala, resultando no uso desnecessário de recursos que podem não ser adequados para a tarefa em questão. Além disso, a natureza indiferenciada de alguns componentes nesses modelos torna um desafio o uso da otimização baseada em gradiente, o que limita o desempenho do treinamento. À medida que os modelos continuam a evoluir, superar estes desafios é fundamental para avançar no campo da IA e criar sistemas mais poderosos e eficientes.
Os métodos atuais para dimensionar modelos de IA geralmente incluem modelos densos e esparsos que usam métodos de roteamento especializados. Modelos densos, como GPT-3 e GPT-4, abrem todas as camadas e parâmetros para todas as entradas, tornando-os complicados de usar e difíceis de escalar. Modelos mínimos, que visam usar apenas um subconjunto de parâmetros baseados em requisitos de entrada, têm se mostrado promissores na redução das demandas computacionais. No entanto, os métodos existentes, como GShard e Switch Transformers, ainda dependem fortemente de correspondência especializada e usam técnicas como descida de token para gerenciar a distribuição de recursos. Embora eficientes, esses métodos apresentam compensações na eficiência do treinamento e no desempenho do modelo.
Pesquisadores da Microsoft introduziram uma nova solução para esses desafios com GRIN (Gross Informatics Expertise). Esta abordagem visa abordar as limitações dos modelos esparsos existentes, introduzindo um novo método para estimar o gradiente de uma rota especializada. GRIN melhora a uniformidade do modelo, permitindo um treinamento eficiente sem a necessidade de depreciação de tokens, um problema comum em microcomputação. Ao aplicar o GRIN a modelos de linguagem automáticos, os pesquisadores desenvolveram um modelo especialista híbrido top-2 com 16 especialistas por camada, chamado modelo GRIN MoE. Este modelo seleciona especialistas seletivamente com base nas informações fornecidas, reduzindo significativamente o número de parâmetros ativos e mantendo o alto desempenho.
O modelo GRIN MoE utiliza diversas técnicas avançadas para alcançar seu desempenho notável. A arquitetura do modelo consiste em camadas MoE onde cada camada contém 16 especialistas, e apenas os 2 primeiros são ativados para cada token de entrada, usando o método de roteamento. Cada especialista é utilizado como uma rede GLU (Gated Linear Unit), que permite ao modelo estimar a eficiência e a potência de saída do computador. Os pesquisadores introduziram o SparseMixer-v2, que é um componente importante que estima gradientes relacionados ao método especialista, substituindo os métodos tradicionais que usam gradientes de controle como proxies. Isso permite que o modelo seja dimensionado sem depender de tokenização ou correspondência de especialistas, o que é comum em outros modelos minoritários.
O desempenho do modelo GRIN MoE foi rigorosamente testado em múltiplas tarefas e os resultados mostram sua alta eficiência e escalabilidade. Nos benchmarks MMLU (Massive Multitask Language Understanding), o modelo obteve impressionantes 79,4, superando vários modelos massivos de tamanhos semelhantes ou maiores. Também obteve pontuação de 83,7 no HellaSwag, que mede o pensamento lógico, e 74,4 no HumanEval, que mede a capacidade do modelo de resolver problemas de codificação. Notavelmente, o desempenho do modelo em MATH, uma referência para o raciocínio matemático, foi de 58,9, indicando a sua força em tarefas especializadas. O modelo GRIN MoE utiliza apenas 6,6 mil milhões de parâmetros ativados durante a projeção, o que é inferior aos 7 mil milhões de parâmetros ativados de modelos densos concorrentes, mas que corresponde ou excede o seu desempenho. Em outra comparação, o GRIN MoE superou um modelo denso de 7 bilhões de parâmetros e igualou o desempenho de um modelo denso de 14 bilhões de parâmetros no mesmo conjunto de dados.
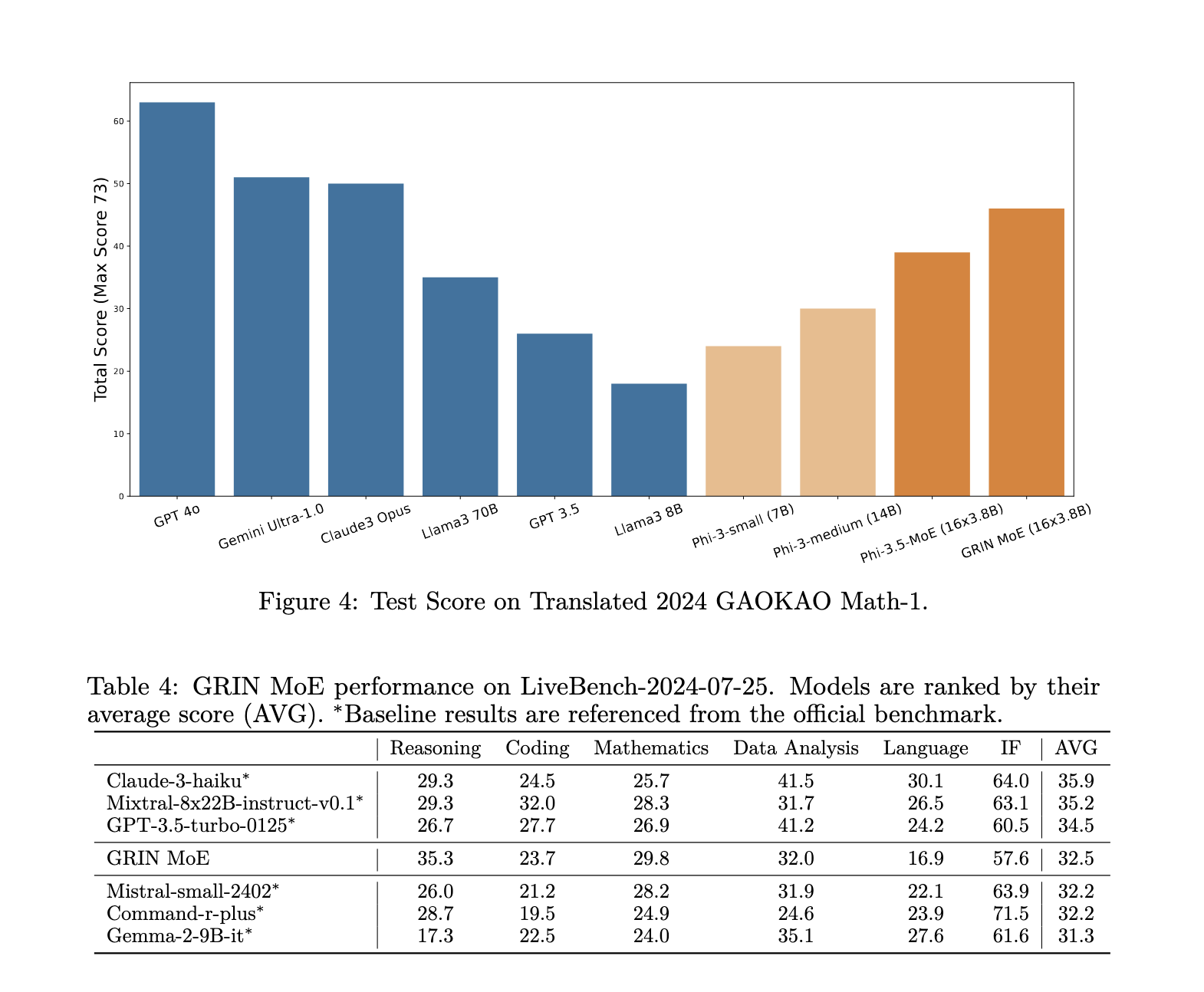
A introdução do GRIN também traz melhorias significativas na eficiência do treinamento. Quando treinado em 64 GPUs H100, o modelo GRIN MoE alcançou um resultado de 86,56%. Isto marca uma melhoria significativa em relação aos modelos anteriores, que muitas vezes sofriam com velocidades de treinamento lentas à medida que o número de parâmetros aumentava. Além disso, a capacidade do modelo de evitar a degradação de tokens significa que ele mantém um alto nível de precisão e robustez em uma variedade de tarefas, ao contrário dos modelos que perdem informações durante o treinamento.
No geral, o trabalho da equipa de investigação da GRIN apresenta uma solução convincente para o desafio contínuo de dimensionar modelos de IA. Ao introduzir um método aprimorado para estimar a tendência e a relevância do modelo, eles desenvolveram com sucesso um modelo que não apenas tem melhor desempenho, mas também treina com mais eficiência. Esses desenvolvimentos poderiam levar a aplicações mais amplas em processamento de linguagem natural, codificação, matemática e muito mais. O modelo GRIN MoE representa um importante passo em frente na investigação em IA, abrindo caminho para modelos mais intuitivos, eficientes e eficazes no futuro.
Confira Papel, Cartão Modelode novo Demonstração. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


