: Como os dados estruturados melhoram as habilidades matemáticas e de raciocínio de modelos de linguagem baseados em IA")
Modelos de linguagem em larga escala (LLMs) podem compreender e gerar texto semelhante ao humano em uma variedade de aplicações. No entanto, apesar do seu sucesso, os LLMs muitas vezes precisam de ajuda com o raciocínio matemático, especialmente ao resolver problemas complexos que exigem pensamento lógico passo a passo. Este campo de investigação está a desenvolver-se rapidamente à medida que os investigadores de IA exploram novas formas de melhorar as competências dos LLMs no tratamento de tarefas de pensamento avançado, especialmente em matemática. Melhorar o raciocínio matemático é importante para fins educacionais e aplicações práticas, como sistemas baseados em IA nas áreas de ciência, modelagem financeira e inovação tecnológica.
O raciocínio matemático em IA é uma área que apresenta desafios únicos. Embora os LLMs atuais tenham um bom desempenho em tarefas gerais, eles precisam de ajuda com problemas matemáticos complexos que exigem pensamento em várias etapas e dedução lógica. Esta limitação decorre principalmente da necessidade de dados estatísticos estruturados e de alta qualidade durante o pré-treinamento dos modelos. Sem exposição suficiente a problemas matemáticos complexos formatados passo a passo, estes modelos não conseguem decompor os problemas em partes geríveis, o que afecta o seu desempenho global em tarefas que requerem pensamento lógico. A falta de conjuntos de dados selecionados e específicos para problemas também torna difícil treinar modelos de uma forma que possa efetivamente melhorar essas habilidades.
As abordagens existentes para resolver este problema incluem a utilização de dados sintéticos para melhorar a organização da formação dos LLMs. Embora a geração artificial de dados tenha se mostrado importante em muitas áreas da IA, incluindo tarefas cognitivas gerais, seu uso no raciocínio estatístico ainda precisa ser desenvolvido. O principal problema é que os métodos existentes para gerar dados sintéticos muitas vezes exigem a integração de processos detalhados e passo a passo de resolução de problemas, necessários para desenvolver o raciocínio lógico. Em tarefas matemáticas, os dados devem ser formatados para ensinar aos modelos como resolver problemas, dividindo-os em subproblemas e abordando cada componente individualmente. A falta de estrutura em muitos métodos de processamento de dados os torna menos eficazes no desenvolvimento das habilidades matemáticas dos LLMs.
Pesquisadores da NVIDIA, Carnegie Mellon University e Boston University introduziram um novo método chamado A MENTE (Mele disse EUé conhecido simNtexto Ddiálogo). Este método cria conversas interativas que simulam o processo passo a passo de resolução de problemas matemáticos complexos. O método MIND usa um grande conjunto de dados conhecido como OpenWebMath, que contém bilhões de tokens de conteúdo matemático da web. O método utiliza esses textos estatísticos baseados na web e os transforma em discussões estruturadas, que desenvolvem as habilidades de pensamento dos LLMs. O MIND permite a criação de conversas em sete estilos diferentes, incluindo configurações como “Professor-Aluno” e “Dois Professores”, para explorar diferentes formas de apresentar e explicar conceitos matemáticos.
A tecnologia no MIND funciona informando ao LLM o texto bruto do OpenWebMath e instruindo-o a dividir o problema em uma série de turnos de conversação. Cada estilo de discussão tem o efeito de dividir um problema matemático em seus componentes principais, permitindo que o modelo se concentre em cada componente de maneira detalhada e lógica. Os pesquisadores usam vários filtros heurísticos para refinar as entrevistas sintéticas, garantindo que permaneçam relevantes e precisas. Desta forma, as discussões geradas pelo MIND mantêm a complexidade dos problemas matemáticos originais, ao mesmo tempo que fornecem uma forma estruturada de pensamento que melhora a capacidade do modelo para resolver problemas de múltiplas etapas.
Os experimentos da equipe de pesquisa mostraram que os LLMs treinados com dados gerados pelo MIND tiveram melhor desempenho do que aqueles treinados apenas com dados brutos. Por exemplo, modelos pré-treinados usando MIND mostraram uma melhoria de 13,42% na precisão no conjunto de dados GSM 8K, que mede a capacidade do modelo de resolver problemas matemáticos de palavras, e um ganho de 2,30% no conjunto de dados MATH. Além disso, os modelos treinados pelo MIND apresentaram resultados superiores em tarefas de conhecimento especializado, como MMLU (Multiple Language Multitasking), com melhoria de 4,55%, e MMLU-STEM, onde o ganho foi de 4,28%. Esta melhoria não se limita apenas ao raciocínio matemático, uma vez que o método MIND também melhorou o desempenho do raciocínio geral em 2,51%, comprovando a ampla aplicabilidade dos dados de entrevistas estruturadas para melhorar os LLMs.
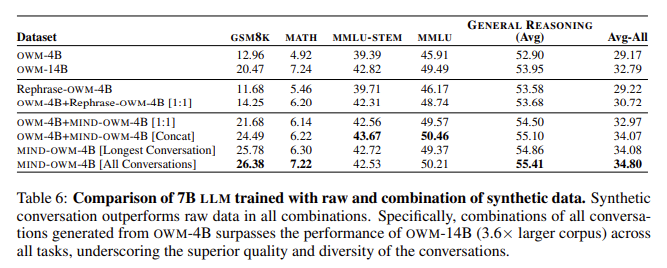
Principais conclusões do estudo:
- Os dados gerados pelo MIND resultaram em uma melhoria de 13,42% na resolução de problemas matemáticos com palavras (GSM 8K) e uma melhoria de 2,30% no conjunto de dados MATH.
- Ganhos de desempenho em ocupações de conhecimento especializado, incluindo uma melhoria de 4,55% em MMLU e um ganho de 4,28% em ocupações MMLU-STEM.
- As tarefas cognitivas gerais apresentaram aumento de 2,51% no desempenho, indicando desempenho mais amplo.
- As discussões produzidas pelo MIND fornecem uma abordagem estruturada para a resolução de problemas, melhorando a capacidade dos LLMs de resolver problemas matemáticos complexos.
- O método é calibrado com sucesso com os dados, fornecendo uma maneira econômica de melhorar as habilidades de raciocínio dos LLMs.

Concluindo, a pesquisa apresentada no MIND apresenta uma forma flexível de melhorar as habilidades de raciocínio matemático de grandes modelos de linguagem. Ao gerar uma variedade de conversas sintéticas, o MIND preenche a lacuna deixada pelos métodos de treinamento tradicionais que dependem fortemente de dados não estruturados. A natureza estruturada das discussões produzidas pelo MIND fornece aos LLMs uma estrutura para resolver problemas complexos que requerem pensamento lógico e múltiplas etapas, fornecendo uma solução confiável para melhorar o desempenho da IA neste importante domínio. A capacidade do MIND de combinar dados brutos e sintéticos aumenta a sua eficiência, uma vez que os modelos beneficiam de um processo de aprendizagem sistemático, mantendo ao mesmo tempo o conhecimento diversificado contido nas fontes de dados brutos.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre o público.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


