
Os modelos multimodais visam criar sistemas que possam integrar e usar facilmente vários métodos para fornecer uma compreensão abrangente dos dados fornecidos. Tais sistemas visam replicar a percepção e consciência humana através do processamento de interações multimodais. Usando esses recursos, os modelos multimodais abrem caminho para sistemas de IA mais avançados que podem realizar uma variedade de tarefas, como responder perguntas visuais, gerar fala e contar uma história.
Apesar do desenvolvimento de modelos multimodais, os métodos atuais ainda precisam ser atualizados. A maioria dos modelos existentes não consegue processar e gerar dados de maneiras diferentes ou focar apenas em um ou dois tipos de entrada, como texto e imagens. Isso leva a uma aplicação menor e a um desempenho reduzido ao lidar com situações complexas do mundo real que exigem integração entre vários métodos. Além disso, a maioria dos modelos não consegue criar conteúdo multidimensional – incluindo texto e conteúdo visual ou de áudio – impedindo assim a sua versatilidade e aplicação em aplicações do mundo real. Enfrentar estes desafios é essencial para desbloquear o verdadeiro potencial dos modelos multidimensionais e permitir o desenvolvimento de sistemas de IA robustos que possam compreender e interagir plenamente com o mundo.
As abordagens atuais à pesquisa multimodal dependem frequentemente de diferentes codificadores e módulos de alinhamento para processar diferentes tipos de dados. Por exemplo, modelos como EVA-CLIP e CLAP usam codificadores para extrair características de imagens e alinhá-las com representações textuais usando módulos externos como Q-Former. Outros métodos incluem modelos como SEED-LLaMA e AnyGPT, que se concentram na combinação de texto e imagens, mas não suportam interações multimodais. Embora o GPT-4o tenha feito progressos no suporte à entrada e saída de dados um para um, ele é de código fechado e não tem a capacidade de gerar sequências cruzadas envolvendo mais de dois caminhos. Tais limitações levaram os pesquisadores a explorar novas estruturas e métodos de treinamento que possam integrar a compreensão e a execução de diversos formatos.
Uma equipe de pesquisadores da Universidade Beihang, AIWaves, Universidade Politécnica de Hong Kong, Universidade de Alberta e várias instituições conhecidas, em um esforço colaborativo, apresentou um novo modelo chamado MIO (Entrada e Saída Multimodal), projetado para superar os modelos existentes. limitações. MIO é um modelo multimodal de código aberto, qualquer para qualquer, que pode processar texto, fala, imagens e vídeos em uma estrutura integrada. O modelo suporta a geração de sequências inversas envolvendo múltiplas modalidades, tornando-o uma ferramenta flexível para interações multimodais complexas. Por meio de um extenso processo de treinamento em quatro etapas, o MIO combina diferentes tokens em quatro modalidades e aprende a produzir resultados multimodais consistentes. As empresas que desenvolvem este modelo incluem MAP e AIWaves, que contribuíram significativamente para o desenvolvimento da investigação em IA multimodal.

O processo de treinamento exclusivo da MIO consiste em quatro estágios para desenvolver sua compreensão multimodal e capacidades de desempenho. A primeira etapa, alinhamento pré-treinamento, garante que as representações dos dados do modelo não textual sejam consistentes com o seu ambiente linguístico. Isto é seguido por um pré-treinamento em loop, incorporando vários tipos de dados, incluindo texto de vídeo e texto de imagem e dados residuais, para melhorar a compreensão contextual do modelo. A terceira fase, pré-treinamento avançado da fala, concentra-se na melhoria das habilidades relacionadas à fala, mantendo ao mesmo tempo um desempenho equilibrado em todas as outras modalidades. Finalmente, a quarta fase envolve um ajuste fino supervisionado usando uma variedade de atividades multimodais, incluindo narrativa visual e pensamento conceitual e cadeia de raciocínio. Este método de treinamento robusto permite que o MIO compreenda profundamente os dados multimodais e produza conteúdo integrado que integra facilmente texto, fala e informações visuais.
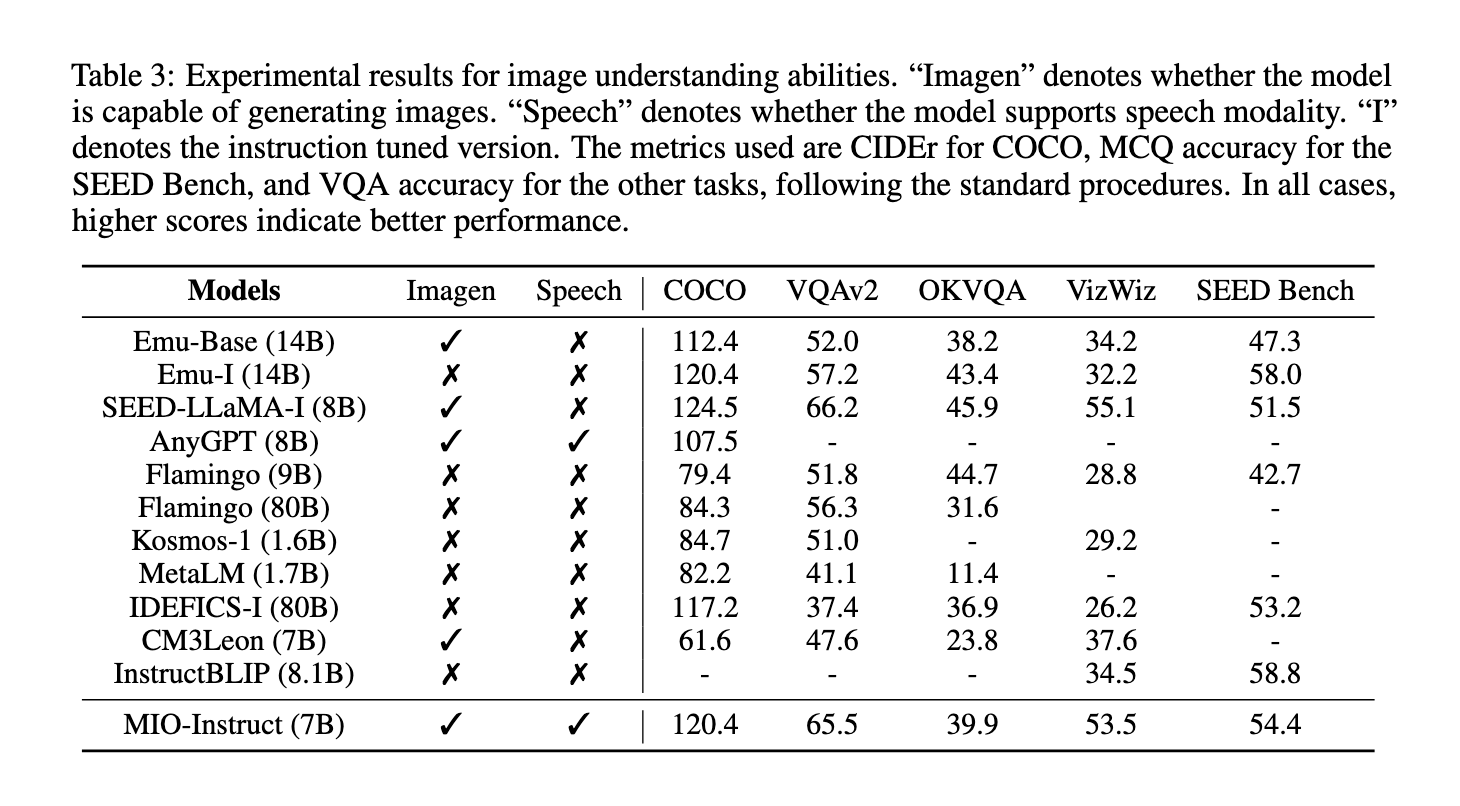
Os resultados experimentais mostram que o MIO atinge desempenho de última geração em vários benchmarks, superando o modo duplo existente e quaisquer modelos multimodo existentes. Em tarefas de resposta visual a perguntas, o MIO alcançou 65,5% de precisão no VQAv2 e 39,9% no OK-VQA, superando outros modelos como Emu-14B e SEED-LLaMA. Nos testes relacionados à fala, o MIO apresentou alto potencial, atingindo taxa de erro de palavras (WER) de 4,2% em tarefas de reconhecimento automático de fala (ASR) e 10,3% em tarefas de conversão de texto em fala (TTS). O modelo também se destacou em tarefas de reconhecimento de vídeo, com precisão top-1 de 42,6% em MSVDQA e 35,5% em MSRVTT-QA. Estes resultados destacam a robustez e eficiência do MIO no tratamento de interações multimodais, mesmo quando comparado a modelos maiores como o IDEFICS-80B. Além disso, o desempenho da MIO na produção dinâmica de textos em vídeo e séries de visualização demonstra suas capacidades únicas para produzir resultados multimodais coerentes e contextuais.

No geral, o MIO apresenta um avanço significativo no desenvolvimento de modelos básicos multimodais, fornecendo uma solução robusta e eficiente para integração e geração de conteúdo através de texto, fala, imagens e vídeos. Seu extenso processo de treinamento e alto desempenho em vários benchmarks demonstram seu potencial para estabelecer novos padrões na pesquisa de IA multimodal. A colaboração entre a Universidade Beihang, a AIWaves, a Universidade Politécnica de Hong Kong e muitas outras instituições conhecidas conduziu a uma ferramenta poderosa que preenche a lacuna entre a compreensão e a geração multimodal, abrindo caminho para novos futuros sistemas de inteligência artificial.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Quer chegar a mais de 1 milhão de leitores de IA? Trabalhe conosco aqui
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.


