
O processamento de linguagem natural (PNL) continua a evoluir com novos métodos, como a aprendizagem in-context (ICL), fornecendo novas maneiras de desenvolver modelos linguísticos em larga escala (LLMs). A ICL envolve modelar a situação em instâncias específicas do modelo sem alterar diretamente os parâmetros do modelo. Este método é muito importante para treinar rapidamente LLMs em diversas profissões. No entanto, o ICL pode consumir muitos recursos, especialmente em modelos baseados em Transformer, onde a memória precisa ser dimensionada com o número de instâncias de entrada. Esta limitação significa que à medida que o número de exibições aumenta, tanto a complexidade computacional quanto o uso de memória aumentam significativamente, potencialmente excedendo a capacidade de processamento dos modelos e impactando o desempenho. Como os sistemas de PNL buscam maior eficiência e robustez, otimizar a forma como as exibições são tratadas na ICL tornou-se um ponto-chave de pesquisa.
O principal problema da ICL é como usar os dados de exibição de maneira eficiente, sem esgotar os recursos de computação ou a memória. Em um cenário típico, a implementação da ICL depende da concatenação de todas as representações em uma única sequência, uma técnica conhecida como ICL baseada em concat. No entanto, este método deve distinguir a qualidade de cada exibição ou correlação, o que muitas vezes leva a um desempenho muito fraco. Além disso, a ICL baseada em concat deve funcionar dentro das limitações de contexto ao lidar com grandes conjuntos de dados, que podem incluir dados irrelevantes ou ruidosos. Essa ineficiência torna o treinamento mais intensivo em recursos e afeta negativamente a precisão do modelo. A seleção de monitores que representem com precisão os requisitos da tarefa e, ao mesmo tempo, controlem as demandas de memória continua sendo uma barreira crítica para o sucesso do aprendizado motor.
Os métodos baseados em síntese, embora simples, precisam ser melhorados no sentido de fazer bom uso das demonstrações disponíveis. Esses métodos combinam todos os exemplos sem verificar sua compatibilidade, o que muitas vezes leva à sobrecarga de memória. As técnicas atuais dependem fortemente de heurísticas, que carecem de precisão e escalabilidade. Esta limitação, juntamente com o aumento dos custos computacionais, cria uma barreira que dificulta o potencial da ICL. Além disso, combinar todos os modelos significa que o mecanismo de atenção nos modelos Transformer, que escala quatro vezes o comprimento da entrada, aumenta ainda mais a intensidade da memória. Este desafio de estimativa quadrática é um grande obstáculo para permitir que a ICL funcione de forma eficaz em diversos conjuntos de dados e tarefas.
Pesquisadores da Universidade de Edimburgo e Miniml.AI desenvolveram um Combinações de alunos no conteúdo (MoICL) caminho. O MoICL introduziu uma nova estrutura para lidar com demonstrações, dividindo-as em grupos menores e especializados, conhecidos como “especialistas”. Um subconjunto de especialistas processa parte das demonstrações e produz um resultado preditivo. Uma função de classificação, concebida para melhorar a utilização de um subconjunto de especialistas, inclui este resultado. Esta tarefa é configurada com base no conjunto de dados e nos requisitos da tarefa, permitindo que o modelo utilize os recursos de memória de forma eficiente. O MoICL fornece, portanto, um método flexível e extensível para aprendizagem em contexto, mostrando melhorias significativas de desempenho em relação aos métodos convencionais.
O submétodo MoICL concentra-se na sua função de estimativa dinâmica, que combina previsões de subconjuntos de especialistas para criar um resultado final holístico. Os pesquisadores podem escolher entre pesos escalares ou de hiper-rede, com cada opção afetando a dinâmica do modelo. Os pesos escalares, inicializados proporcionalmente, permitem ajustar a contribuição de cada especialista durante o treinamento. Alternativamente, a hiper-rede pode gerar pesos baseados em contexto, otimizando os resultados para diferentes subconjuntos de entrada. Essa adaptabilidade permite que o MoICL funcione de forma eficaz com diferentes tipos de modelos, tornando-o versátil em diversas aplicações de PNL. O esquema de classificação MoICL também reduz os custos computacionais ao limitar a necessidade de processar todo o conjunto de dados em vez de priorizar informações relevantes.
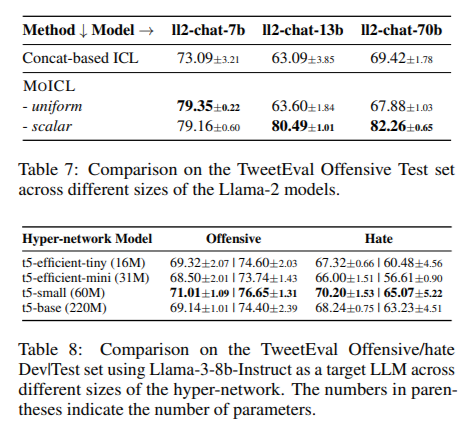
Nos testes de todas as sete tarefas de classificação, o MoICL superou consistentemente os métodos ICL padrão. Por exemplo, alcançou uma precisão maior de até 13% em conjuntos de dados como o TweetEval, onde alcançou uma precisão de 81,33%, e melhorou a robustez de dados ruidosos em 38%. O sistema também mostrou resiliência ao desalinhamento de rótulos (melhoria de até 49%) e dados fora do domínio (manuseio 11% melhor). Ao contrário dos métodos convencionais, o MoICL mantém um desempenho estável mesmo com conjuntos de dados não simétricos ou quando exposto a exibições fora do domínio. Usando o MoICL, os pesquisadores alcançaram maior eficiência de memória e tempos de processamento mais rápidos, provando que ele é eficiente em integração e desempenho.
Principais conclusões do estudo:
- Benefícios Funcionais: O MoICL mostrou uma melhoria de precisão de até 13% no TweetEval em comparação aos métodos convencionais, com vantagens significativas em tarefas de classificação.
- Intensidade sonora e desequilíbrio: O método melhorou a robustez para dados ruidosos em 38% e administrou a distribuição desigual de rótulos 49% melhor do que os métodos ICL convencionais.
- Cálculo Ativo: O MoICL reduziu os tempos de decisão sem sacrificar a precisão, mostrando eficiência de dados e memória.
- Em geral: MoICL mostrou forte adaptabilidade a diferentes tipos de modelos e tarefas de PNL, fornecendo uma solução complexa para aprendizagem de memória de maneira eficiente.
- Administração fora do local: O MoICL é robusto contra variações imprevisíveis de dados, com uma melhoria documentada de 11% no tratamento de exemplos fora do domínio.

Concluindo, o MoICL representa uma grande melhoria em relação ao ICL, superando as restrições de memória e fornecendo desempenho consistentemente alto. Ao usar subconjuntos especializados e funções de escala, ele fornece uma maneira muito eficiente de selecionar exibições. Essa abordagem atenua as limitações dos métodos baseados em concat e oferece precisão robusta em diversos conjuntos de dados, tornando-a altamente adequada para futuras tarefas de PNL.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


