
A estimativa de profundidade monocular (MDE) desempenha um papel importante em várias aplicações, incluindo edição de imagens e vídeos, reconstrução de cenas, síntese de novas cenas e navegação de robôs. Porém, este trabalho apresenta grandes desafios devido à incerteza da faixa de escala, o que o impossibilita. Os métodos baseados na aprendizagem devem utilizar um forte conhecimento semântico para alcançar resultados precisos e superar esta limitação. O progresso recente viu a adaptação de modelos de difusão MDE em larga escala, tratando a previsão de profundidade como um problema de geração de imagem condicional, mas eles sofrem com velocidades lentas. Os requisitos computacionais para testar iterativamente grandes redes neurais durante a inferência têm sido uma grande preocupação na área.
Recentemente, várias abordagens foram desenvolvidas para enfrentar os desafios do MDE. Um desses métodos é a estimativa de profundidade monocular, que prevê a profundidade com base em pixels. Outro método é a medição de profundidade métrica, que fornece uma representação mais detalhada, mas contém complexidade adicional devido às variações de altura da câmera. Além disso, a medição mais geral evoluiu de métodos baseados em aprendizagem para métodos de aprendizagem profunda mais complexos. Mais recentemente, modelos de difusão têm sido usados em modelagem geométrica, com alguns métodos produzindo profundidade de múltiplas visualizações e mapas normais de objetos únicos. Métodos de medição de profundidade em nível de cena, como VPD, usam difusão estável, mas a generalização ainda é um desafio em ambientes complexos e realistas.
Pesquisadores da RWTH Aachen University e da Eindhoven University of Technology apresentaram uma nova solução para a ineficiência do MDE baseada na transmissão. Eles construíram um modelo aninhado pegando um erro antigo e desconhecido no pipeline de indexação, onde o modelo aninhado superou a melhor otimização relatada e foi 200 vezes mais rápido. O ajuste fino ponta a ponta é aplicado com perdas específicas de tarefas em um modelo de etapa única para melhorar o desempenho. Este método resulta em um modelo determinístico que supera todos os outros modelos baseados em difusão e modelos de calibração convencionais em benchmarks padrão de disparo zero. Além disso, este protocolo de ajuste fino funciona diretamente na Difusão Estável, alcançando o mesmo desempenho dos modelos topo de linha.
O método proposto utiliza dois conjuntos de dados sintéticos para treinamento: Hypersim para cenas internas fotorrealistas e Virtual KITTI 2 para cenários de direção para fornecer anotações de alta qualidade. Para testes, é usado um conjunto diversificado de benchmarks, incluindo NYUv2 e ScanNet para ambientes internos, ETH3D e DIODE para cenas mistas internas e externas e KITTI para condições de direção externas. A implementação é construída no teste oficial do Marigold para medição de profundidade, enquanto a mesma configuração é usada para medição geral, escrevendo mapas regulares como vetores 3D em canais coloridos. A equipe segue os hiperparâmetros do Marigold, treinando todos os modelos 20.000 vezes usando o otimizador AdamW.
Os resultados mostram que o processo de extração de ruído do Marigold não funciona tão bem quanto o esperado e o desempenho diminui à medida que as etapas de extração de ruído aumentam. O escalonador DDIM consistente apresentou desempenho superior para todas as contagens de passos. Uma comparação entre o vanilla Marigold, uma variante do Modelo de Consistência Latente, e os modelos de uma etapa dos pesquisadores mostra que o escalonador implícito do DDIM alcança resultados comparáveis ou melhores em uma etapa, sem agrupamento. Além disso, a otimização Marigold supera todas as otimizações anteriores em um passo sem integração. Surpreendentemente, a otimização direta da difusão estável produz resultados semelhantes aos do modelo Marigold pré-treinado.
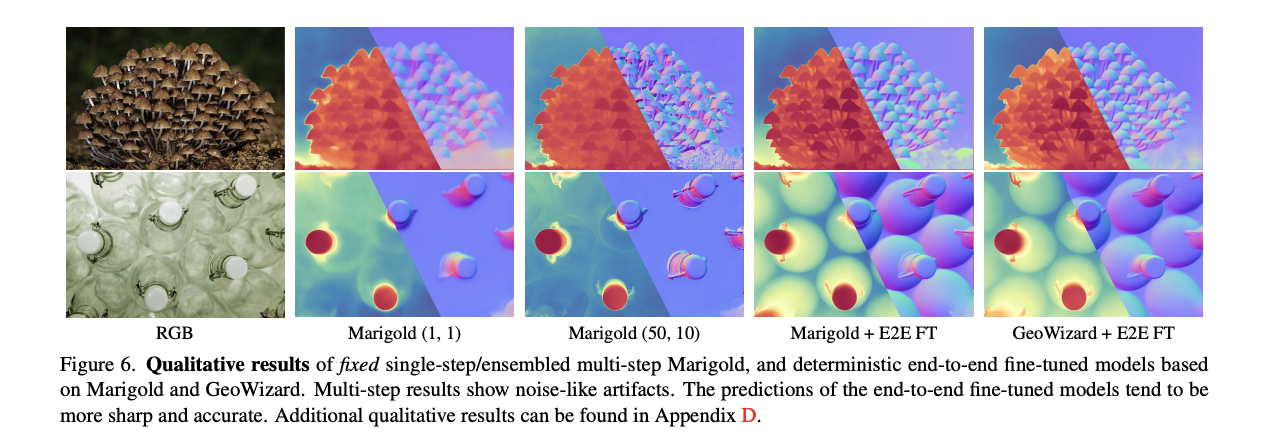
Em resumo, os pesquisadores apresentaram uma solução para a ineficiência do MDE baseado em broadcast, que revela uma falha fundamental na implementação do escalonador DDIM. Desafia conclusões anteriores sobre profundidade baseadas na transmissão monocular e medições convencionais. Os pesquisadores mostraram que um arranjo simples de ponta a ponta é mais eficaz do que pipelines e estruturas de treinamento complexas, sem perder o suporte para a teoria de que o treinamento prévio de difusão fornece a melhor prioridade para tarefas geométricas. Os modelos emergentes permitem uma previsão precisa em uma etapa e possibilitam o uso de big data e métodos avançados de treinamento. Esta descoberta estabelece as bases para desenvolvimentos futuros em modelos de difusão, permitindo materiais confiáveis e melhor desempenho na estimativa geométrica.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


