: uma abordagem integrada para reforçar a aprendizagem humana e o feedback de IA, resolvendo desafios de padronização e coleta de feedback")
A aprendizagem por reforço (RL) tem sido fundamental no desenvolvimento da inteligência artificial, permitindo que os modelos aprendam com suas interações com o ambiente. Tradicionalmente, a aprendizagem por reforço depende de recompensas para boas ações e punições para as más. Uma abordagem recente, a Aprendizagem por Reforço com Feedback Humano (RLHF), trouxe melhorias dramáticas aos modelos linguísticos de grande escala (LLMs), ao incorporar as preferências humanas no processo de formação. A RLHF garante que os sistemas de IA se comportam de forma consistente com os padrões humanos. No entanto, a recolha e o processamento deste feedback consome muitos recursos, exigindo grandes conjuntos de dados de preferências rotuladas por humanos. À medida que os sistemas de IA crescem em escala e complexidade, os investigadores estão a explorar formas mais eficientes de melhorar o desempenho dos modelos sem depender apenas da contribuição humana.
Os modelos treinados usando RLHF requerem grandes quantidades de dados de preferências para tomar decisões consistentes com as expectativas do usuário. Como a coleta de dados humanos é cara, o processo cria um gargalo, limitando o desenvolvimento do modelo. Além disso, confiar no feedback humano limita a aplicabilidade dos modelos a novas tarefas que ainda não foram encontradas durante o treinamento. Isto pode levar a um desempenho insatisfatório quando os modelos são usados em ambientes do mundo real que precisam lidar com condições irregulares ou fora de distribuição (OOD). A resolução deste problema requer uma abordagem que reduza a dependência de dados humanos e melhore o desempenho do modelo.
Os métodos atuais, como o RLHF, provaram ser úteis, mas apresentam limitações. No RLHF, os modelos são refinados com base no feedback fornecido por humanos, o que envolve dimensionar os resultados de acordo com as preferências do usuário. Embora este método melhore o alinhamento, pode ser ineficiente. Outra abordagem recente, a Aprendizagem por Reforço com Feedback de IA (RLAIF), procura superar esta situação utilizando feedback gerado por IA. O modelo utiliza diretrizes predefinidas, ou “constituições”, para avaliar seus resultados. Embora o RLAIF reduza a dependência da contribuição humana, pesquisas recentes mostram que o feedback gerado pela IA está alinhado de forma imprecisa com as preferências humanas reais, resultando em um desempenho insatisfatório. Esta discrepância é particularmente evidente em tarefas não distributivas onde o modelo requer uma compreensão limitada das expectativas humanas.
Pesquisadores da SynthLabs e da Universidade de Stanford apresentaram uma solução híbrida: Modelos de recompensa generativos (GenRM). Este novo método combina os pontos fortes de ambos os métodos para treinar modelos de forma mais eficiente. GenRM usa um processo iterativo para ajustar LLMs gerando traços lógicos, que atuam como rótulos de preferência artificiais. Esses rótulos refletem melhor as preferências de uma pessoa, ao mesmo tempo que eliminam a necessidade de uma resposta demográfica ampla. A estrutura GenRM preenche a lacuna entre RLHF e RLAIF, permitindo que a IA gere os seus próprios contributos e os refine continuamente. A introdução do pensamento de acompanhamento ajuda o modelo a simular o processo detalhado do pensamento humano que melhora a precisão da tomada de decisões, especialmente em tarefas complexas.
GenRM usa um LLM grande e pré-treinado para gerar cadeias de raciocínio que auxiliam na tomada de decisões. O pensamento Chain-of-Thought (CoT) é incorporado ao fluxo de trabalho do modelo, onde a IA gera um pensamento passo a passo antes de concluir. Esse pensamento inato atua como um modelo de feedback, que é desenvolvido em ciclos repetidos. O modelo GenRM compara-se favoravelmente com métodos tradicionais, como modelos de recompensa Bradley-Terry e DPO (Direct Preference Optimization), superando em precisão de 9 a 31% em tarefas distribuídas e de 10 a 45% em tarefas não distribuídas. Esta otimização iterativa reduz a carga de recursos e melhora a capacidade do modelo de gerar todas as funções.
Em tarefas distribuídas, quando os modelos são testados em problemas já vistos, o GenRM apresenta desempenho semelhante ao modelo de recompensa de Bradley-Terry, mantendo altas taxas de precisão. Contudo, o benefício real do GenRM é visto nas atividades OOD. Por exemplo, o GenRM supera os modelos tradicionais em 26% em tarefas típicas, tornando-o mais adequado para aplicações do mundo real onde os sistemas de IA são necessários para lidar com situações novas ou inesperadas. Além disso, os modelos que utilizam GenRM mostraram melhorias na redução de erros na tomada de decisões e no fornecimento de resultados mais precisos e consistentes com os valores humanos, mostrando entre 9% e 31% de melhoria no desempenho em tarefas que exigem raciocínio complexo. O modelo também teve um desempenho melhor do que os juízes baseados em LLM, que dependem apenas do feedback da IA, mostrando uma abordagem mais equilibrada para melhorar o feedback.
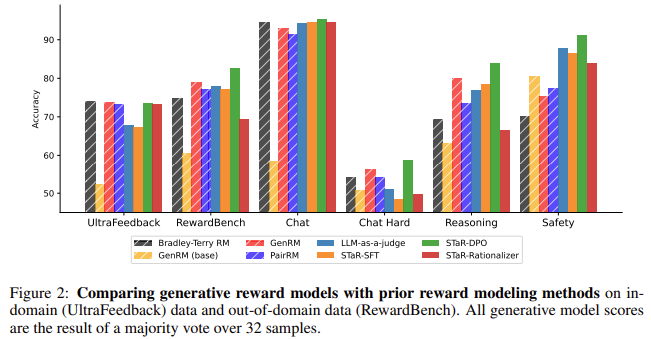
Principais conclusões do estudo:
- Funcionalidade Adicional: O GenRM melhora o desempenho das operações de distribuição em 9-31% e das operações OOD em 10-45%, demonstrando capacidades operacionais gerais.
- Dependência reduzida da resposta humana: Os métodos de raciocínio desenvolvidos pela IA substituem a necessidade de grandes conjuntos de dados rotulados por humanos, acelerando o processo de feedback.
- Normalização avançada fora de distribuição: O GenRM tem um desempenho 26% melhor que os modelos tradicionais em tarefas não rotineiras, melhorando a robustez em situações do mundo real.
- Método medido: O uso combinado de IA e feedback humano garante que os sistemas de IA permaneçam consistentes com os valores humanos, ao mesmo tempo que reduz os custos de treinamento.
- Leitura repetitiva: O refinamento contínuo das cadeias de raciocínio melhora a tomada de decisões em tarefas complexas, melhorando a precisão e reduzindo erros.

Concluindo, a introdução de Modelos de Recompensa Gerativos representa um poderoso passo em frente no reforço da aprendizagem. A combinação do feedback humano com o raciocínio gerado pela IA permite o treinamento eficiente do modelo sem sacrificar o desempenho. O GenRM resolve dois problemas importantes: reduz a necessidade de coleta intensiva de dados populacionais e, ao mesmo tempo, melhora a capacidade do modelo de lidar com tarefas novas e não treinadas. Ao combinar RLHF e RLAIF, o GenRM representa uma solução inovadora e flexível para melhorar a compreensão da IA e dos valores humanos. O sistema híbrido melhora a precisão da distribuição e melhora muito o desempenho sem distribuição, tornando-o uma estrutura promissora para a próxima geração de sistemas inteligentes.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Sana Hassan, estagiária de consultoria na Marktechpost e estudante de pós-graduação dupla no IIT Madras, é apaixonada pelo uso de tecnologia e IA para enfrentar desafios do mundo real. Com um profundo interesse em resolver problemas do mundo real, ele traz uma nova perspectiva para a intersecção entre IA e soluções da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


