
O rápido crescimento dos modelos linguísticos de grande escala (LLMs) e as suas crescentes exigências computacionais resultaram numa necessidade premente de soluções melhoradas para controlar o uso da memória e a velocidade de decisão. À medida que modelos como GPT-3, Llama e outras grandes arquiteturas ultrapassam os limites da capacidade da GPU, o uso eficiente do hardware torna-se crítico. Altos requisitos de memória, geração lenta de tokens e limitações na largura de banda da memória contribuíram para gargalos significativos de desempenho. Esses problemas são especialmente perceptíveis ao implantar LLMs em GPUs NVIDIA Hopper, pois medir o uso de memória e a velocidade de integração se torna mais desafiador.
Neural Magic apresenta Machete: um novo kernel GEMM híbrido para GPUs NVIDIA Hopper, que representa um grande avanço na compreensão de alto desempenho do LLM. Machete usa escalonamento de entrada mista w4a16 para reduzir significativamente o uso de memória e, ao mesmo tempo, garantir desempenho de computação consistente. Esta inovação permite que o Machete reduza os requisitos de memória em quase 4x em ambientes com restrição de memória. Comparado com a precisão do FP16, o Machete corresponde ao desempenho do computador, ao mesmo tempo que melhora significativamente a eficiência das implantações com atraso de memória. À medida que o escopo dos LLMs continua a expandir, abordar as restrições de memória com soluções eficientes como o Machete torna-se fundamental para permitir um modelo mais suave, rápido e eficiente.
Uma das inovações do Machete está no seu desempenho técnico. Construído sobre o CUTLASS 3.5.1, Machete usa comandos de tecla tensor wgmma para superar as limitações do computador, resultando em uma renderização de modelo mais rápida. Ele também possui pré-carregamento leve, que permite carregamentos de memória compartilhada mais rápidos, reduzindo efetivamente os gargalos que geralmente aparecem em grandes LLMs. Esse processo de ponderação otimiza a memória compartilhada, permitindo o carregamento de 128 bits, aumentando o rendimento e reduzindo a latência. Além disso, Machete melhorou os métodos de conversão que permitem a conversão eficiente de objetos de 4 bits para 16 bits, aumentando o uso do núcleo tensor. Juntas, essas inovações tornam o Machete uma solução viável para melhorar o desempenho do LLM sem a sobrecarga normalmente associada ao aumento da precisão ou ao custo computacional adicional.
A importância do Machete não pode ser exagerada, especialmente no contexto da crescente demanda por suprimentos LLM que são memória e eficiência computacional. Ao reduzir o uso de memória em quatro vezes, o Machete ajuda a garantir que mesmo os maiores LLMs, como o Llama 3.1 70B e o Llama 3.1 405B, possam ser usados com eficiência no hardware disponível. Nos testes, o Machete obteve resultados notáveis, incluindo um aumento de 29% no rendimento e uma taxa de geração de token 32% mais rápida para o Llama 3.1 70B, com um impressionante tempo de token até o primeiro token (TTFT) de menos de 250 ms em um H100. A GPU. Quando medido em uma configuração 4xH100, o Machete apresentou uma aceleração de saída de 42% no Llama 3.1 405B. Esses resultados mostram não apenas as melhorias significativas de desempenho oferecidas pelo Machete, mas também sua capacidade de escalar com sucesso em todos os tipos de hardware. O suporte para melhorias futuras, como w4a8 FP8, AWQ, QQQ, e melhor desempenho para operações de baixo tamanho de lote, fortalece ainda mais o papel do Machete em ampliar os limites de implantações LLM bem-sucedidas.
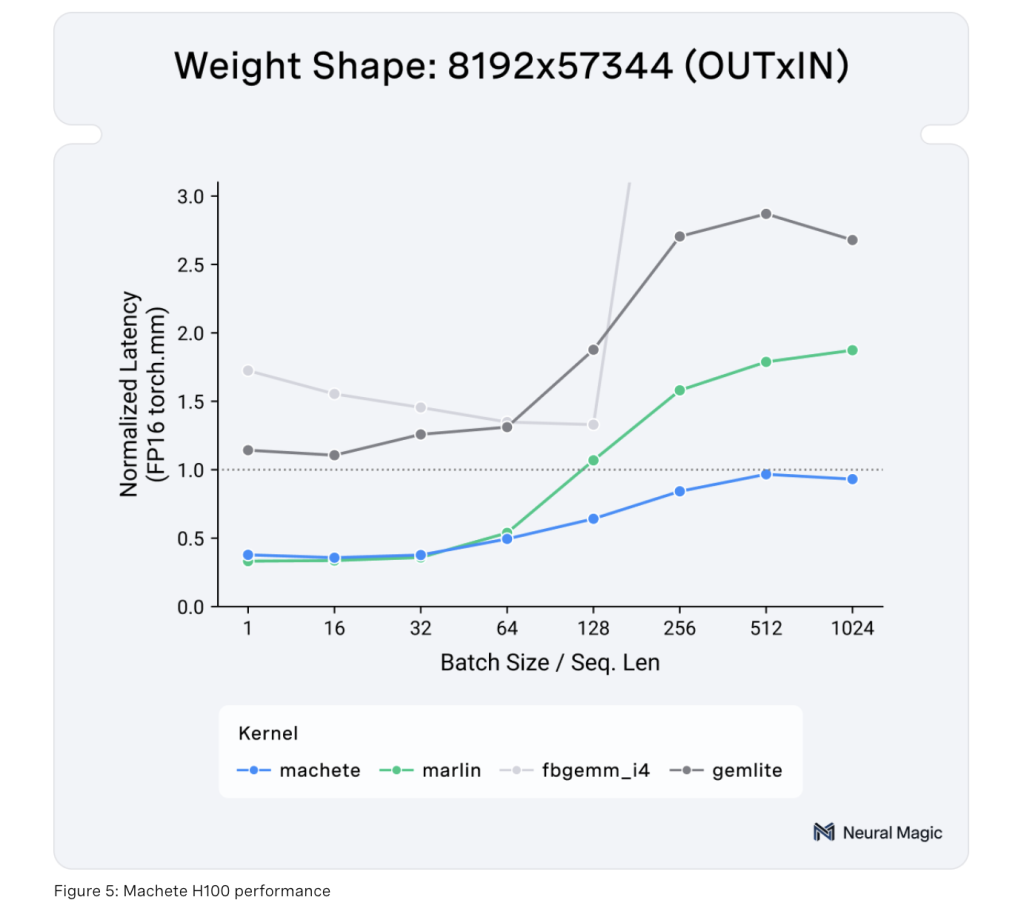
Concluindo, Machete representa um avanço lógico no desenvolvimento da lógica LLM em GPUs NVIDIA Hopper. Ao abordar as restrições significativas de uso de memória e largura de banda, Machete introduziu uma nova maneira de gerenciar os requisitos de grandes modelos de linguagem. A estimativa de entradas mistas, a otimização técnica e a calibração tornam-no uma ferramenta inestimável para melhorar o desempenho do modelo e, ao mesmo tempo, reduzir o custo computacional. Os impressionantes benefícios mostrados nos modelos Llama mostram que o Machete está pronto para ser o principal facilitador de implantações LLM bem-sucedidas, estabelecendo um novo padrão de desempenho em ambientes de memória. À medida que os LLMs continuam a crescer em escala e complexidade, ferramentas como o Machete serão essenciais para garantir que estes modelos possam ser implementados de forma eficiente, fornecendo resultados rápidos e fiáveis sem comprometer a qualidade.
Confira Detalhes. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre o público.



: oferece aumento de até 2 a 4x na velocidade de computação e redução de 56% no tamanho do modelo")