
LLMs autoregressivos redes neurais complexas geram texto coerente e contextualmente relevante por meio de previsão sequencial. Esses LLms são excelentes no manuseio de grandes conjuntos de dados e são fortes em tradução, resumo e IA conversacional. No entanto, alcançar um elevado nível de geração de ideias geralmente isso ocorre às custas de maiores requisitos de computação, especialmente resoluções mais altas ou vídeos mais longos. Apesar do estudo bem-sucedido de espaços latentes comprimidos, os modelos de difusão de vídeo estão limitados a efeitos de comprimento fixo e não podem se adaptar modelos autorregressivos como GPT.
Os modelos atuais de automação de vídeo enfrentam muitas limitações. Modelos de distribuição ele faz excelentes conversões de texto para imagem e texto para vídeo, mas depende de tokens de comprimento fixo, o que limita sua flexibilidade e tamanho entre gerações de vídeo. Modelos autorregressivos geralmente sofrem quantização vetorial problemas porque convertem dados físicos em espaços de token com um valor diferente. Tokens de alta qualidade requerem mais tokens, enquanto o uso desses tokens aumenta o custo de computação. Embora o desenvolvimento goste VAR de novo MAR melhorar a qualidade da imagem e a modelagem produtiva, seu uso na produção de vídeo é muitas vezes dificultado por ineficiências de modelagem e desafios de adaptação a diferentes contextos.
Para resolver essas questões, pesquisadores do BUPT, ICT-CAS, DLUT e BAAI propuseram NOVAmodelo autoregressivo não ponderado para produção de vídeo. A NOVA aborda a geração de vídeo prevendo quadros temporalmente independentes e conjuntos de tokens espaciais dentro de cada quadro de maneira flexível. Este modelo inclui baseado no tempo de novo baseado em localização previsão diferencial de como quadros e conjuntos espaciais são produzidos. Ele usa um modelo de linguagem pré-treinado para processar comandos de texto e fluxo visual para rastrear movimentos. Para previsão baseada no tempo, o modelo usa um método de mascaramento causal em bloco, enquanto para previsão baseada no espaço, ele usa um método bidirecional para prever conjuntos de tokens. O modelo introduz camadas de escala e mudança para melhorar a estabilidade e usa incorporação seno-cosseno para melhor estabilização. Ele também adiciona perda de difusão para ajudar a prever a probabilidade de um token em um ambiente contínuo, tornando o treinamento e a interpretação mais eficientes e melhorando a qualidade e a escalabilidade do vídeo.
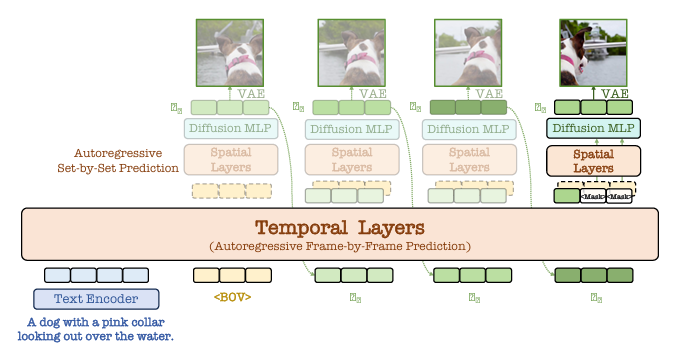
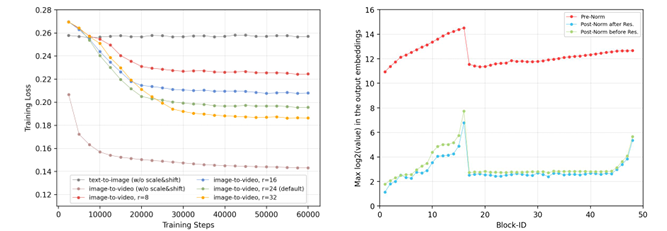
Pesquisadores são treinados NOVA usando conjuntos de dados de alta qualidade, para começar 16 milhões de pares de imagens de texto de fontes como DataComp, COYO, Remover respingode novo TripDBque mais tarde foram ampliados para 600 milhões de pares de LAION, DataCompde novo COYO. Do texto ao vídeo, os pesquisadores usaram 19 milhões pares de videotexto de Panda–70 milhões e outros conjuntos de dados internos, bem 1 milhão em pares de Pexels-mecanismo de legenda suportado Em 2-17B definições geradas. Os edifícios da NOVA incluíram espaço RA camada, remoção de ruído MLP bloco e um 16 camadas uma estrutura codificador-decodificador para lidar com componentes espaciais e temporais. A dimensão temporal do codificador-decodificador vem deles 768 a 1536e o removedor de ruído MLP tem três blocos com 1280 medições. Um modelo VAE pré-treinado capturou os recursos da imagem usando máscaras e cronogramas de distribuição. NOVA foi formada aos dezesseis anos A100 nós com otimizador AdamW. Ele foi treinado primeiro para tarefas de texto para imagem e depois para tarefas de texto para vídeo.
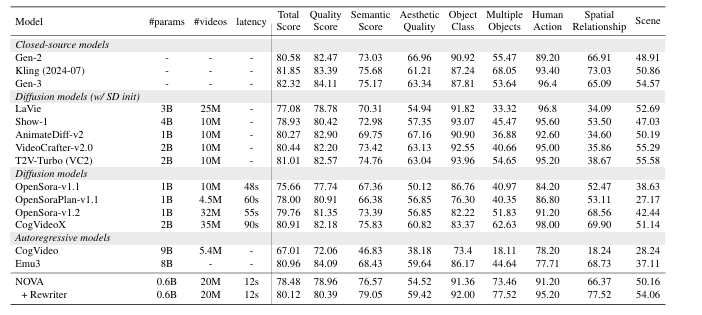
Resultados dos testes T2I-CompBench, Avaliação Geralde novo Banco DPG mostrou que a NOVA é mais bem-sucedida do que modelos semelhantes PixArt-α de novo SD v1/v2 em funções de texto para imagem e texto para vídeo. A NOVA produziu fotos e vídeos de alta qualidade com imagens mais nítidas e detalhadas. Ele também forneceu resultados mais precisos e resultados de entrada e saída de texto melhor alinhados.

Em resumo, o modelo NOVA proposto melhora muito a reprodução de texto para imagem e de texto para vídeo. O método reduz a complexidade computacional e melhora a eficiência ao combinar projeções temporais quadro a quadro e espaciais com uma saída definida e de boa qualidade. Seu desempenho supera os modelos existentes, com qualidade de imagem e fidelidade de vídeo próximas às comerciais. Este trabalho fornece uma base para pesquisas futuras, fornece uma base para o desenvolvimento de modelos escaláveis e produção de vídeo em tempo real e abre novas oportunidades para desenvolvimento na área.
Confira eu Papel de novo Página GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


