
Uma visualização de ponte com linguagem grande multimodal (MLLMs), que permite uma interpretação eficaz do conteúdo visual. No entanto, alcançar uma compreensão precisa e quantificável de imagens estáticas e vídeos dinâmicos continua sendo um desafio. Conflitos temporais, ineficiências de medição e inteligibilidade limitada do vídeo dificultam o progresso, especialmente na manutenção de uma representação consistente de objetos e regiões entre quadros de vídeo. A deriva temporal, causada por movimento, escala ou mudança de visão, acompanhada pela dependência de métodos computacionalmente pesados, como caixas delimitadoras ou recursos alinhados com a região de interesse (RoI), aumenta a complexidade e limita a análise de vídeo em tempo real e em grande escala .
Técnicas recentes, como coordenadas de região de texto, símbolos visuais e recursos baseados em RoI, tentaram resolver esses problemas. No entanto, muitas vezes eles não conseguem garantir a consistência temporal entre os quadros ou processar adequadamente grandes conjuntos de dados. As caixas delimitadoras não possuem a robustez do rastreamento de vários quadros, e a análise de quadros estáticos perde relacionamentos temporais complexos. Embora novas técnicas, como a incorporação de links em informações textuais e o uso de tags baseadas em imagens, tenham avançado neste campo, uma solução unificada para domínios de imagem e vídeo permanece indefinida.
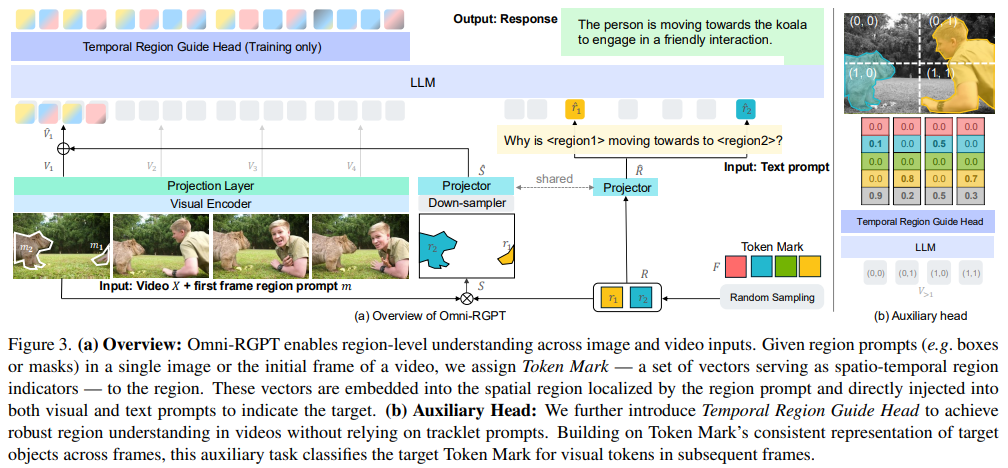
Pesquisadores da NVIDIA e da Universidade Yonsei o desenvolveram OmniRGPTum novo modelo de macrolinguagem projetado para alcançar uma compreensão contínua de imagens e vídeos em nível regional para enfrentar esses desafios. Este modelo introduz Marca Tokenum método básico que incorpora tokens específicos da região em informações visuais e textuais, estabelecendo uma conexão mútua entre os dois métodos. O sistema Token Mark substitui os métodos convencionais baseados em RoI, definindo um token exclusivo para cada local de destino, que permanece constante entre os quadros do vídeo. Esta estratégia evita desvios temporais e reduz custos computacionais, permitindo um raciocínio robusto para entradas estáticas e dinâmicas. A inclusão do Cabeçalho de Região Temporal também melhora o desempenho do modelo em dados de vídeo, segmentando tokens visuais para evitar a dependência de métodos de rastreamento complexos.
Omni-RGPT usa um grande conjunto de dados recém-desenvolvido chamado RegVID-300k, que contém 98.000 vídeos exclusivos, 214.000 regiões anotadas e 294.000 amostras de treinamento em nível de região. Este conjunto de dados foi criado combinando dados de dez conjuntos de dados de vídeos públicos, fornecendo descrições diversas e refinadas de atividades específicas da região. O conjunto de dados oferece suporte ao raciocínio visual de bom senso, legendas baseadas em região e compreensão de fala indexada. Ao contrário de outros conjuntos de dados, o RegVID-300k inclui legendas detalhadas com contexto temporal e reduz a acuidade visual por meio de técnicas avançadas de validação.
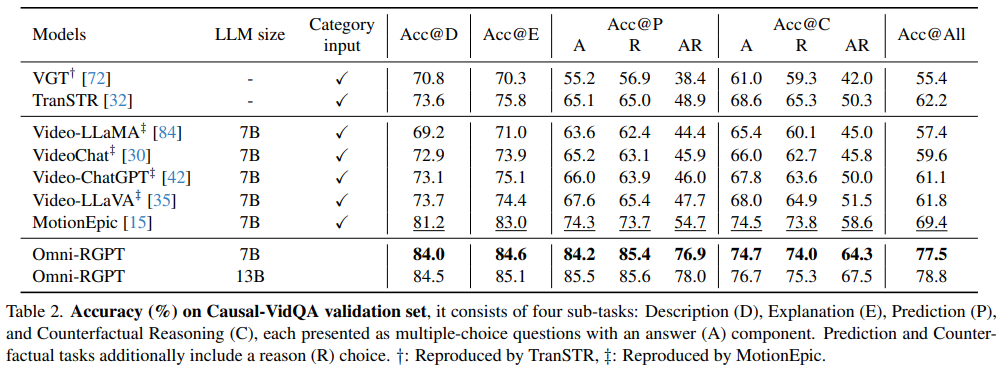
Omni-RGPT alcançou resultados de última geração em vários benchmarks, incluindo 84,5% de precisão no conjunto de dados Causal-VidQA, que examina o raciocínio temporal e espacial em sequências de vídeo. O modelo superou os métodos existentes, como o MotionEpic, em mais de 5% em algumas subtarefas, mostrando desempenho superior em previsão e falsos positivos. Da mesma forma, o modelo funciona muito bem em tarefas de trechos de vídeo, alcançando altas pontuações METEOR em conjuntos de dados desafiadores, como Vid-STG e BenSMOT. O modelo alcançou precisão significativa para tarefas baseadas em imagens no conjunto de dados Visual Commonsense Reasoning (VCR), um método altamente eficiente otimizado especificamente para domínios de imagens.

Algumas conclusões importantes do estudo Omni-RGPT incluem:
- Esta abordagem facilita a compreensão e a consistência a nível regional, incorporando tokens predefinidos em entradas visuais e textuais. Isso evita desvios temporais e oferece suporte à renderização contínua entre quadros.
- O conjunto de dados fornece anotações detalhadas, refinadas e diferenciadas, permitindo que o modelo se destaque em tarefas de vídeo complexas. Inclui 294.000 instruções e espaços de endereço em nível distrital em conjuntos de dados existentes.
- Omni-RGPT apresentou o melhor desempenho em todos os benchmarks, como Causal-VidQA e VCR, alcançando uma melhoria de precisão de até 5% em comparação com os modelos líderes.
- O design do modelo minimiza a sobrecarga de computação, evitando a dependência de caixas de junção ou tracklets de vídeo completos, tornando-o adequado para aplicações do mundo real.
- A moldura integra facilmente funções de foto e vídeo em uma única estrutura, alcançando desempenho excepcional sem comprometer a eficiência.
Concluindo, o Omni-RGPT aborda desafios críticos na aprendizagem multimodal específica da região, introduzindo o Token Mark e um novo conjunto de dados para apoiar a compreensão detalhada de imagens e vídeos. O design flexível do modelo e o desempenho de última geração em uma ampla gama de funções estabelecem um novo padrão para a área. Omni-RGPT fornece uma base sólida para pesquisas futuras e aplicações práticas em IA, eliminando desvios temporais, reduzindo a complexidade computacional e usando dados em grande escala.
Confira Página de papel e design. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 Recomendar plataforma de código aberto: Parlant é uma estrutura que muda a forma como os agentes de IA tomam decisões em situações voltadas para o cliente. (Promovido)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
📄 Conheça 'Height': ferramenta independente de gerenciamento de projetos (patrocinado)

? Principais diferenças, exemplos do mundo real e dados de treinamento")
