
A Nvidia apresentou seu mais recente modelo de linguagem grande (LLM), i Lhama-3.1-Nemotron-51B. Baseado no Llama-3.1-70B da Meta, este modelo é ajustado usando métodos avançados de Pesquisa de Arquitetura Neural (NAS), resultando em um avanço em desempenho e eficiência. Projetado para caber em uma única GPU Nvidia H100, o modelo reduz significativamente o consumo de memória, a complexidade computacional e os custos associados à execução de modelos tão grandes. É um marco nos esforços contínuos da Nvidia para desenvolver modelos de IA em larga escala para aplicações do mundo real.
Origem do Lhama-3.1-Nemotron-51B
O Llama-3.1-Nemotron-51B é um sucessor do Llama-3.1-70B da Meta, lançado em julho de 2024. Embora o modelo Meta já estabelecesse um padrão alto de desempenho, a Nvidia queria ir além, concentrando-se na eficiência. Ao alugar um NAS, os pesquisadores da Nvidia criaram um modelo que oferece o mesmo, se não melhor, desempenho e reduz significativamente os requisitos de recursos. Em termos de poder computacional bruto, o Llama-3.1-Nemotron-51B oferece definição 2,2x mais rápida que seu antecessor, mantendo um nível comparável de precisão.
Sucesso no bom desempenho
Um dos principais desafios no desenvolvimento do LLM é medir a precisão e a eficiência do computador. Muitos modelos grandes oferecem resultados modernos, mas à custa de grandes recursos de hardware e energia, que limitam seu desempenho. O novo modelo da Nvidia atinge um equilíbrio delicado entre esses dois recursos concorrentes.
O Llama-3.1-Nemotron-51B alcança uma compensação eficiente em precisão, reduz a largura de banda da memória, reduz o número de pontos flutuantes por segundo (FLOPs) e reduz a memória geral sem comprometer a capacidade do modelo de executar operações complexas. como raciocínio, resumo e construção da linguagem. A Nvidia levou o modelo ao ponto em que ele pode realizar tarefas maiores do que nunca em uma única GPU H100, abrindo muitas novas oportunidades para desenvolvedores e empresas.
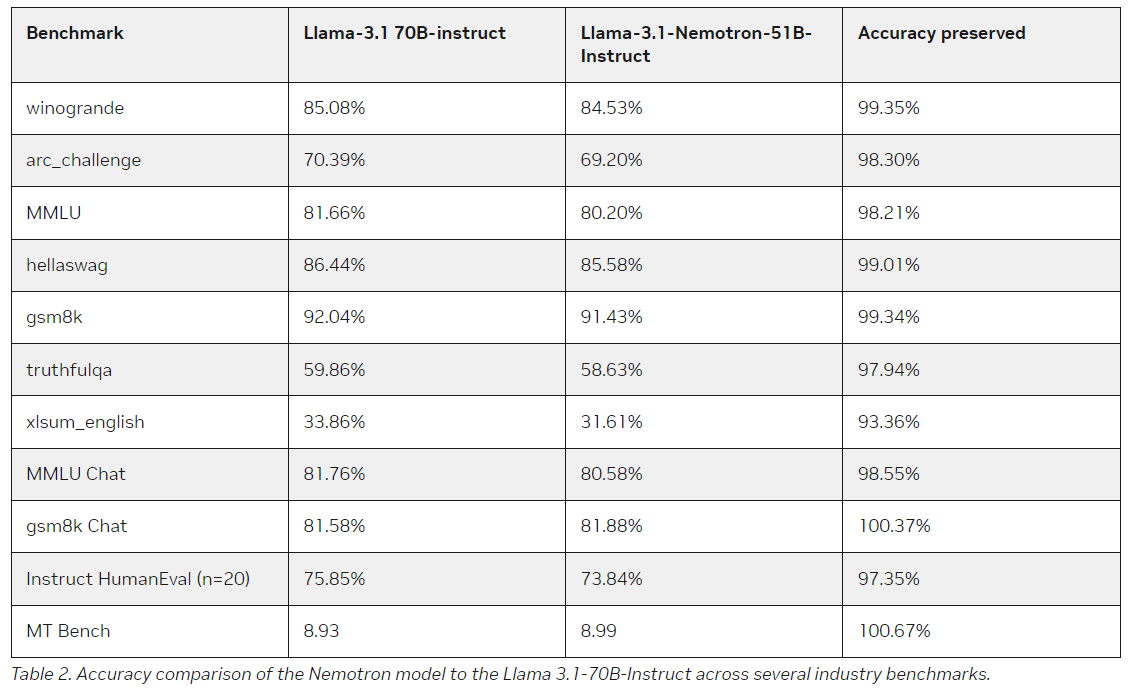
Melhor gerenciamento de carga de trabalho e eficiência de custos
A característica marcante do Llama-3.1-Nemotron-51B é sua capacidade de lidar com grandes cargas de trabalho em uma única GPU. Este modelo permite que os desenvolvedores usem LLMs de alto desempenho em ambientes de baixo custo, executando tarefas que antes exigiam múltiplas GPUs em apenas uma unidade H100.
Por exemplo, o modelo pode lidar com cargas de trabalho 4x maiores durante o índice do que a referência Llama-3.1-70B. Ele também permite resultados mais rápidos, com a Nvidia relatando desempenho 1,44x melhor em áreas-chave do que outros modelos. A eficiência do Llama-3.1-Nemotron-51B é baseada em uma nova abordagem arquitetônica, que se concentra na redução da reatividade em processos computacionais, mantendo a capacidade do modelo de executar tarefas linguísticas complexas com alta precisão.
Desenvolvimento imobiliário: a chave para o sucesso
O Llama-3.1-Nemotron-51B deve muito de seu sucesso a uma nova abordagem para construção civil. Tradicionalmente, os LLMs são construídos utilizando os mesmos blocos, que são repetidos ao longo do modelo. Embora isto simplifique o processo de construção, introduz ineficiências, especialmente em termos de memória e custos computacionais.
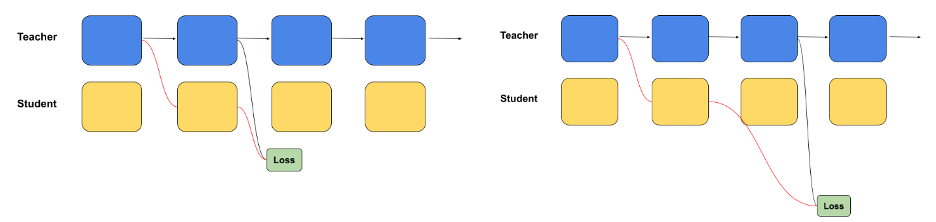
A Nvidia resolveu esses problemas usando técnicas NAS que dimensionam o modelo com precisão. A equipe usou uma técnica de destilação em bloco, na qual modelos de alunos pequenos e de alto desempenho são treinados para imitar o desempenho de um modelo de professor grande. Ao refinar esses modelos de estudantes e testar seu desempenho, a Nvidia produziu uma versão do Llama-3.1 que oferece os mesmos níveis de precisão, ao mesmo tempo que reduz significativamente os requisitos de recursos.
O processo de destilação em bloco permite à Nvidia testar diferentes combinações de redes de atenção e alimentação (FFNs) dentro do modelo, criando configurações alternativas que priorizam velocidade ou precisão, dependendo das necessidades específicas da tarefa. Essa flexibilidade torna o Llama-3.1-Nemotron-51B uma ferramenta poderosa para uma variedade de setores que precisam implementar IA em escala, seja em ambientes de nuvem, data centers ou até mesmo configurações de computação de ponta.
Algoritmo de quebra-cabeça e extração de informações
O algoritmo Puzzle é outra parte importante que diferencia o Llama-3.1-Nemotron-51B de outros modelos. Este algoritmo mede cada bloco possível dentro do modelo e determina qual configuração produzirá o melhor equilíbrio entre velocidade e precisão. Ao usar técnicas de destilação de informações, a Nvidia reduziu a lacuna de precisão entre o modelo de referência (Llama-3.1-70B) e o Nemotron-51B, ao mesmo tempo que reduziu significativamente os custos de treinamento.
Através deste processo, a Nvidia criou um modelo que funciona na fronteira efetiva do desenvolvimento de modelos de IA, ultrapassando os limites do que pode ser alcançado com uma única GPU. Ao garantir que cada bloco do modelo seja o mais eficiente possível, a Nvidia criou um modelo que supera muitos de seus concorrentes em exatidão e precisão.
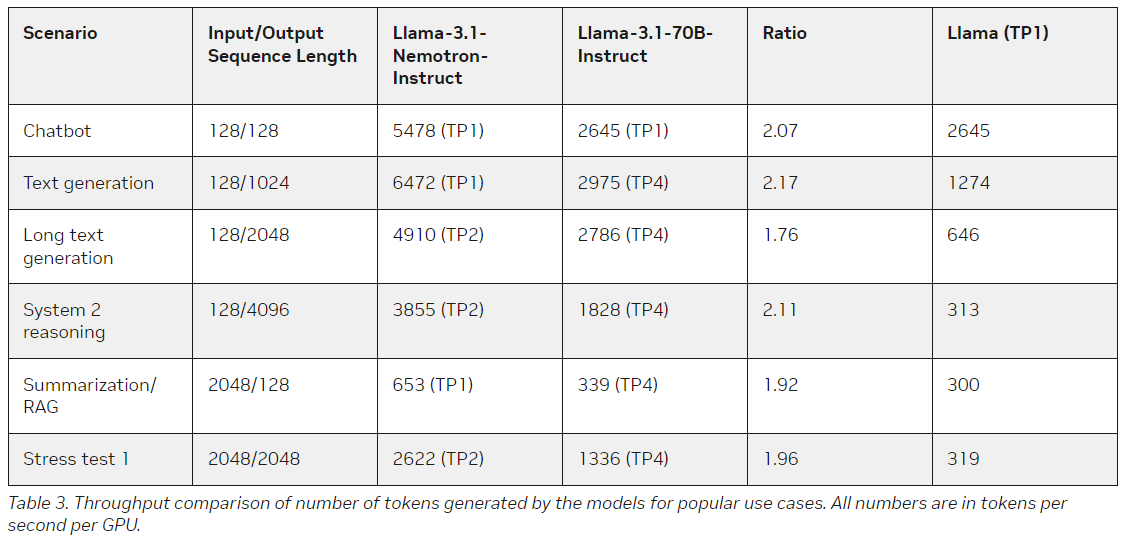
Compromisso da Nvidia com soluções de IA econômicas
O custo sempre foi uma barreira significativa para a adoção generalizada de modelos de macrolinguagem. Embora a eficácia destes modelos não possa ser negada, o seu custo percebido limitou a sua utilização apenas às organizações mais prósperas. O Llama-3.1-Nemotron-51B da Nvidia enfrenta esse desafio de frente, oferecendo um modelo de alto desempenho e ao mesmo tempo visando economia.
A memória reduzida e os requisitos computacionais do modelo o tornam mais acessível para organizações menores e desenvolvedores que podem não ter recursos para executar modelos grandes. A Nvidia também organizou o processo de implantação, empacotando o modelo como parte de seu Nvidia Inference Microservice (NIM), que usa mecanismos TensorRT-LLM para alto rendimento. O sistema foi projetado para ser fácil de usar em uma variedade de configurações, desde ambientes de nuvem até dispositivos de borda, e pode ser dimensionado sob demanda.
Aplicações e implicações futuras
O lançamento do Llama-3.1-Nemotron-51B tem implicações de longo alcance para o futuro da IA e dos LLMs produtivos. Ao tornar os modelos de alto desempenho acessíveis e baratos, a Nvidia abriu as portas para que muitas indústrias usassem essa tecnologia. O custo reduzido de inferência também significa que os LLMs agora podem ser implantados em áreas que são caras demais para serem justificadas, como aplicativos em tempo real, chatbots de atendimento ao cliente e muito mais.
A flexibilidade da abordagem NAS usada no desenvolvimento do modelo significa que a Nvidia pode continuar a refinar e expandir a arquitetura para diferentes configurações de hardware e casos de uso. Quer um desenvolvedor precise de um modelo otimizado para velocidade ou precisão, o Llama-3.1-Nemotron-51B da Nvidia fornece uma base que pode ser modificada para atender a uma variedade de requisitos.
A conclusão
O Llama-3.1-Nemotron-51B da Nvidia é uma versão revolucionária no mundo da IA. Com foco no desempenho e na eficiência, a Nvidia criou um modelo que não apenas rivaliza com os melhores do setor, mas também estabelece um novo padrão de relação custo-benefício e acessibilidade. O uso de NAS e técnicas de destilação em bloco permitiu à Nvidia contornar as limitações usuais dos LLMs, tornando possível executar esses modelos em uma única GPU, mantendo alta precisão. À medida que a IA produtiva continua a evoluir, modelos como o Llama-3.1-Nemotron-51B desempenharão um papel importante na definição do futuro da indústria, permitindo que mais organizações aproveitem o poder da IA nas suas operações diárias. Seja para processamento de big data, geração de linguagem em tempo real ou tarefas de computação avançadas, a oferta mais recente da Nvidia promete ser uma ferramenta valiosa para desenvolvedores e empresas.
Confira Modelo e Blog. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


