
Os modelos linguísticos demonstraram capacidades notáveis no processamento de vários tipos de dados, incluindo texto multilíngue, código, expressões matemáticas, imagens e áudio. No entanto, surge uma questão importante: como é que estes modelos lidam eficazmente com dados tão diversos utilizando um único conjunto de parâmetros? Embora uma abordagem sugira a criação de subespaços especializados para cada tipo de dados, esta ignora as conexões semânticas inerentes que existem entre tipos de dados aparentemente distintos. Por exemplo, frases semelhantes em idiomas diferentes, pares de legendas de imagens ou trechos de código com descrições em linguagem natural compartilham semelhança conceitual. Semelhante ao centro semântico transmodal do cérebro humano que integra informações de vários inputs sensoriais, existe uma oportunidade de desenvolver modelos que possam apresentar diferentes tipos de dados numa representação unificada, realizar cálculos e produzir resultados relevantes. O desafio reside na criação de uma arquitetura que possa explorar eficazmente esta semelhança estrutural, mantendo ao mesmo tempo as características únicas de cada tipo de dados.
As tentativas anteriores de lidar com a representação heterogênea de tipos de dados concentraram-se principalmente em atingir diferentes modelos de tipos de dados que são treinados separadamente usando técnicas de transformação. A pesquisa mostrou sucesso na compreensão de incorporações de palavras em diferentes idiomas usando métodos de mapeamento, e métodos semelhantes foram usados para vincular representações visuais e textuais de diferentes modelos. Outros estudos examinaram pequenas adaptações de modelos somente de linguagem para lidar com tarefas multimodais. Pesquisas adicionais investigaram a evolução da representação usando camadas transformadoras, examinando seu impacto no raciocínio, na realidade e no processamento de informações. As camadas de poda e os estudos iniciais de crescimento também forneceram insights sobre a representação dinâmica. No entanto, estes métodos requerem frequentemente diferentes modelos ou transformações entre representações, o que limita a sua eficácia e pode carecer de ligações profundas entre diferentes tipos de dados. Além disso, a necessidade de métodos de alinhamento gráfico adiciona complexidade e sobrecarga computacional aos sistemas.
Pesquisadores do MIT, da Universidade do Sul da Califórnia e do Allen Institute for AI propõem uma abordagem robusta para compreender como os modelos de linguagem processam vários tipos de dados por meio de um espaço de representação compartilhado. A metodologia se concentra em investigar a presença de “centro semântico”- um espaço de representação unificado composto pelo tipo de dados dominante do modelo, geralmente inglês. Este método examina três aspectos importantes: primeiro, analisar como entradas semanticamente semelhantes de diferentes tipos de dados (linguagens, expressões aritméticas, código e entradas multimodais) se reúnem em camadas intermediárias do modelo; segundo, investigar como essas representações ocultas podem ser interpretadas na linguagem dominante do modelo usando a técnica log lens; e terceiro, conduzir experiências de intervenção para demonstrar que este espaço representacional partilhado tem uma influência mais forte no comportamento modelado do que a produção passiva de formação. Ao contrário das abordagens anteriores que se concentram na compreensão de modelos treinados separadamente, esta abordagem examina como um único modelo cresce naturalmente e explora um espaço de representação unificado sem exigir métodos de alinhamento explícitos.
A estrutura para testar a hipótese do hub semântico usa uma arquitetura matemática complexa construída em funções específicas de domínio e espaços de representação. Para qualquer tipo de dados z no conjunto de modelos suportados Z, a estrutura define um domínio Xz (como tokens do idioma chinês ou valores RGB para imagens) e duas funções principais: Mz, que representa a sequência de entrada na representação semântica Sz, e Vz , que converte essas representações de volta ao formato de tipo de dados original. O método de avaliação examina duas estatísticas importantes: primeiro, para comparar a similaridade entre entradas semanticamente relacionadas de diferentes tipos de dados usando medidas de similaridade de cosseno dos estados ocultos, e segundo, para avaliar a relação entre esta representação e a linguagem dominante do modelo usando o técnica de lentes de penetração. Esta técnica analisa os estados ocultos nas camadas intermediárias usando uma matriz de incorporação de tokens, gerando uma distribuição de probabilidade para revelar o processamento interno do modelo. As construções foram rigorosamente testadas em muitos tipos de dados, incluindo diversas linguagens, expressões matemáticas, código, estruturas semânticas e entrada multimodal, demonstrando consistentemente a existência de um espaço de representação semântica unificado.

O estudo fornece resultados convincentes de testes de intervenção que confirmam o impacto causal do centro semântico no comportamento do modelo. Num estudo multilíngue utilizando o método de Ativação Aditiva, a intervenção no espaço representacional inglês moderou com sucesso os resultados do modelo mesmo no processamento de textos em espanhol e chinês. Examinando 1.000 iniciais do conjunto de dados InterTASS (espanhol) e do corpus multilíngue de revisão da Amazon (chinês), o estudo comparou os resultados do modelo com e sem intervenção usando palavras emocionais específicas do idioma (Bom/Mau, Bueno/Malo,好/坏). Esta experiência mostrou que uma intervenção baseada em inglês alcançou efeitos instrucionais comparáveis a uma intervenção utilizando uma língua escrita nativa, mantendo a fluência e a coerência da produção. Os pesquisadores avaliaram a qualidade do texto produzido por meio de três métricas principais: alinhamento emocional com a direção pretendida, fluência do texto produzido e relevância para a premissa original. Os resultados apoiam fortemente a ideia de que o hub semântico não é simplesmente um produto que surge sem treinamento, mas que influencia significativamente a capacidade do modelo de processar múltiplas linguagens.
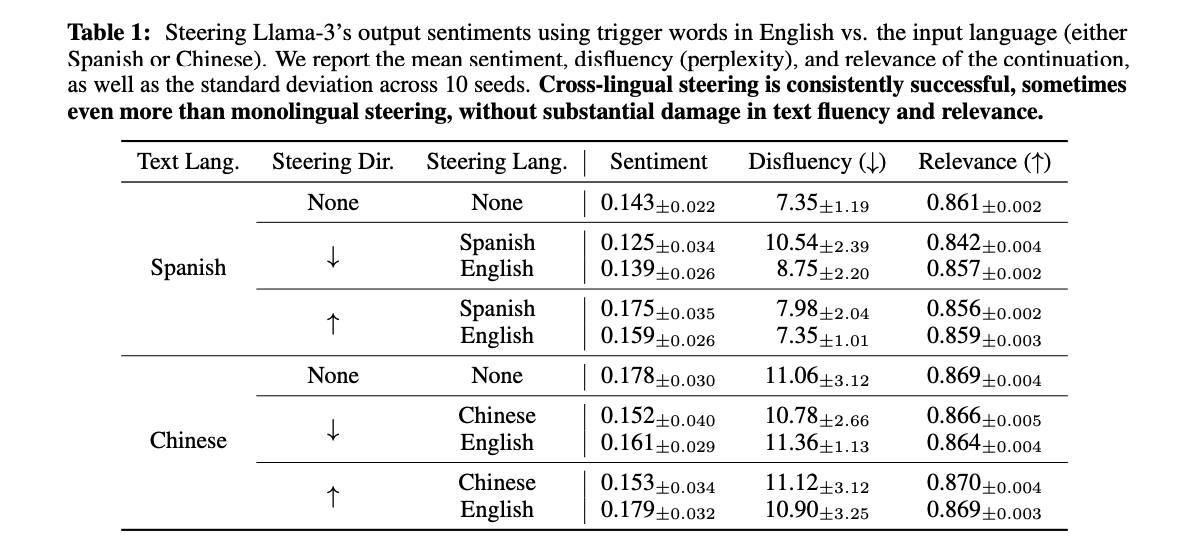
A pesquisa melhora a compreensão de como os modelos de linguagem processam diferentes tipos de dados por meio de um centro semântico integrado. A investigação mostra claramente que os modelos desenvolvem naturalmente um espaço representacional partilhado quando os inputs semanticamente relacionados se juntam, independentemente da sua forma original. Esta descoberta, confirmada em modelos e tipos de dados, abre novas possibilidades para interpretação e controle de modelos através de intervenções direcionadas em espaços linguísticos superiores.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[AI Magazine/Report] Leia nosso último relatório sobre 'MODELOS DE TERRENO PEQUENOS'
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️
: um novo paradigma de avaliação para avaliar respostas de VLM a perguntas abertas")

