
Os avanços na inteligência artificial dependem da disponibilidade e da qualidade dos dados de treinamento, especialmente à medida que os modelos multiobjetivos crescem em destaque. Esses modelos dependem de diversos conjuntos de dados, incluindo texto, fala e vídeo, para permitir tarefas de processamento de linguagem, reconhecimento de fala e geração de conteúdo de vídeo. No entanto, a falta de transparência sobre as origens e atributos dos conjuntos de dados cria obstáculos significativos. A utilização de dados de formação distorcidos geográfica e linguisticamente, licenciados de forma inconsistente ou mal documentados apresenta desafios éticos, legais e técnicos. Compreender as lacunas na utilização de dados é fundamental para o desenvolvimento de tecnologias de IA responsáveis e inclusivas.
Os sistemas de IA enfrentam um problema crítico na representação e rastreabilidade de conjuntos de dados, o que limita o desenvolvimento de tecnologias imparciais e juridicamente sólidas. Os conjuntos de dados atuais muitas vezes dependem fortemente de algumas fontes baseadas na Web ou geradas automaticamente. Isso inclui plataformas como o YouTube, que hospeda uma grande parte dos conjuntos de dados de fala e vídeo, e a Wikipedia, que domina os dados textuais. Essa dependência faz com que os conjuntos de dados não consigam representar adequadamente idiomas e regiões sub-representadas. Além disso, procedimentos de licenciamento pouco claros para muitos conjuntos de dados criam ambiguidade jurídica, uma vez que mais de 80% dos conjuntos de dados amplamente utilizados contêm alguma forma de restrições não escritas ou pouco claras, apesar de apenas 33% serem explicitamente licenciados para utilização não comercial.
As tentativas de enfrentar estes desafios têm-se centrado tradicionalmente em aspectos restritos da selecção de dados, tais como a remoção de conteúdos nocivos ou a redução de distorções em conjuntos de dados textuais. No entanto, tais esforços são muitas vezes limitados a métodos únicos e carecem de uma estrutura abrangente para examinar conjuntos de dados em todos os métodos, como fala e vídeo. As plataformas que hospedam esses conjuntos de dados, como HuggingFace ou OpenSLR, muitas vezes não possuem mecanismos para garantir a precisão dos metadados ou impor práticas de autoria consistentes. Esta abordagem diversificada sublinha a necessidade urgente de avaliação sistemática de conjuntos de dados multiobjetos que considerem plenamente a sua disponibilidade, licenciamento e representação.
Para fechar esta lacuna, pesquisadores da Data Provenance Initiative conduziram o maior estudo longitudinal de conjuntos de dados multiobjetos, examinando quase 4.000 conjuntos de dados públicos criados entre 1990 e 2024. A pesquisa envolveu 659 organizações de 67 países, abrangendo 608 idiomas e quase 1,9 milhão de horas de dados de fala e vídeo. Esta análise extensiva revelou que os sites de web crawling e de redes sociais têm agora uma grande quantidade de informações de formação, com os recursos de formação também a crescerem rapidamente. O estudo destacou que, embora apenas 25% dos conjuntos de dados de texto tenham licenças explicitamente restritivas, quase todo o conteúdo de plataformas como YouTube ou OpenAI tem restrições não comerciais claras, levantando questões sobre conformidade legal e uso ético.
Os pesquisadores usaram um método cuidadoso para descrever os conjuntos de dados, rastreando seu inventário até as fontes. Este processo encontrou inconsistências significativas na forma como os dados são licenciados e documentados. Por exemplo, embora 96% dos conjuntos de dados textuais incluam licenças comerciais, mais de 80% do material de origem estabelece restrições não progressivas aos documentos dos conjuntos de dados. Da mesma forma, os conjuntos de dados de vídeo dependem fortemente de redes sociais proprietárias ou limitadas, com 71% dos conjuntos de dados de vídeo provenientes apenas do YouTube. Estas descobertas sublinham os desafios que os profissionais enfrentam no acesso responsável aos dados, especialmente quando os conjuntos de dados são reempacotados ou licenciados sem preservar os seus termos originais.
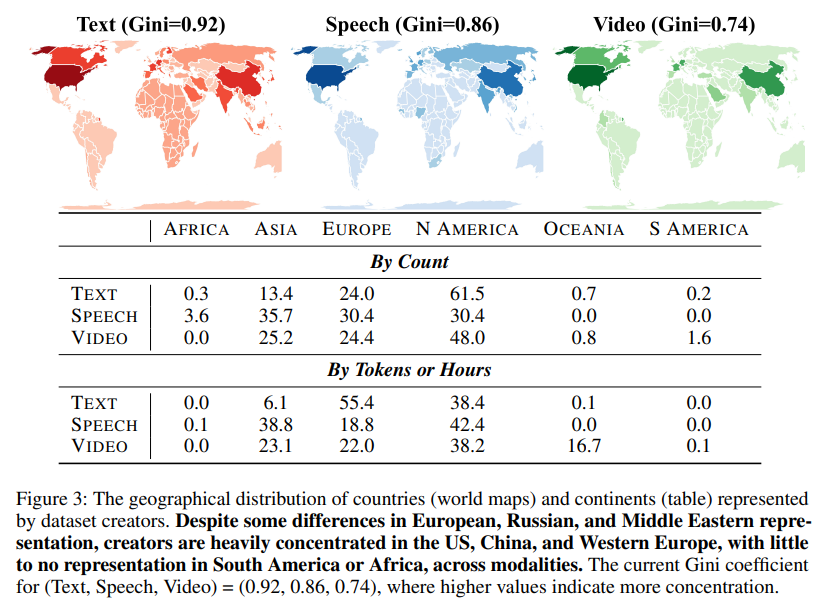
As descobertas notáveis do estudo incluem o domínio dos dados da web, especialmente em fala e vídeo. O YouTube emergiu como a fonte mais importante, dedicando quase 1 milhão de horas a cada palestra e conteúdo de vídeo, superando outras fontes, como audiolivros ou filmes. Os conjuntos de dados sintéticos, embora ainda representem uma pequena parte do conjunto de dados geral, cresceram rapidamente, com modelos como o GPT-4 contribuindo significativamente. A auditoria revelou também desequilíbrios geográficos. As organizações na América do Norte e na Europa geraram 93% dos dados de texto, 61% dos dados de fala e 60% dos dados de vídeo. Em comparação, regiões como a África e a América do Sul representam juntas menos de 0,2% de todas as medidas.
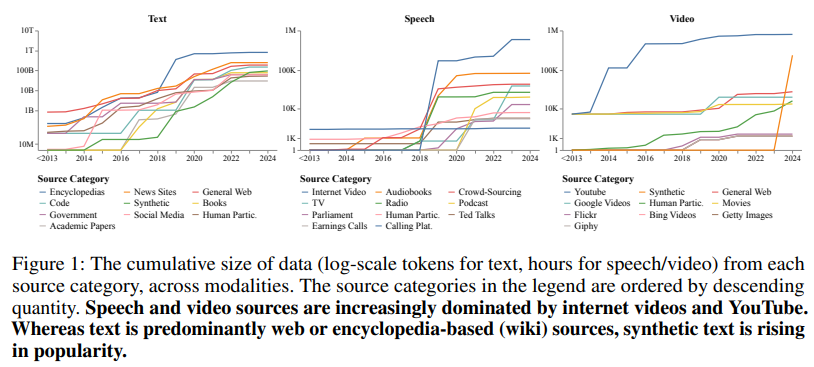
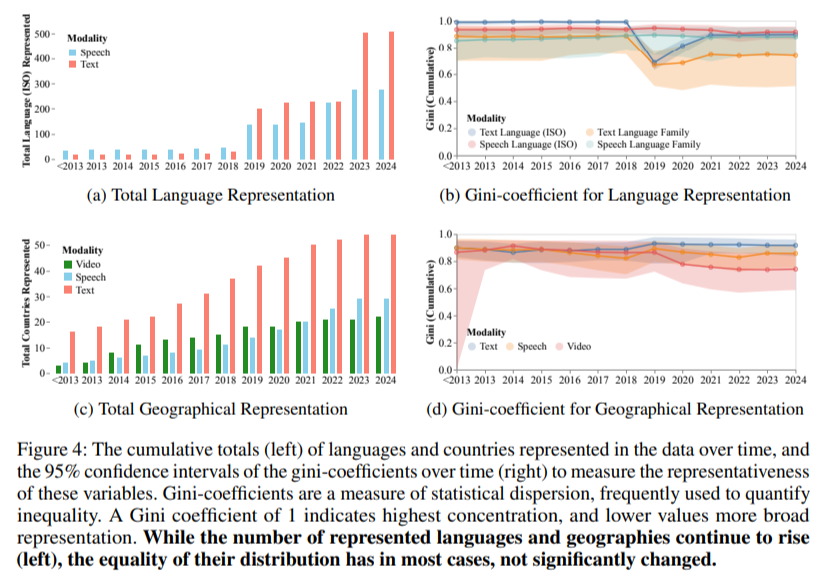
A representação geográfica e linguística continua a ser um desafio constante, apesar do pequeno aumento da diversidade. Ao longo da última década, o número de línguas representadas no conjunto de dados de formação cresceu para mais de 600, mas as medidas de igualdade na representação não mostraram melhorias significativas. O coeficiente de Gini, que mede a desigualdade, permanece acima de 0,7 para a distribuição geográfica e acima de 0,8 para a representação linguística em conjuntos de dados de texto, destacando a concentração desproporcional de contribuições dos países ocidentais. Nos conjuntos de dados de fala, embora a representação de países asiáticos como a China e a Índia tenha melhorado, as organizações africanas e sul-americanas continuam muito atrás.
O estudo oferece algumas conclusões importantes, que fornecem informações importantes para desenvolvedores e formuladores de políticas:
- Mais de 70% dos conjuntos de dados de voz e vídeo são encontrados em redes sociais como o YouTube, enquanto as fontes sintéticas são cada vez mais populares, representando cerca de 10% de todos os tokens de dados de texto.
- Embora apenas 33% dos conjuntos de dados não sejam comerciais, mais de 80% do conteúdo de origem é restrito. Esta disparidade dificulta a conformidade e a aplicação ética.
- As organizações norte-americanas e europeias dominam a criação do conjunto de dados, com contribuições africanas e sul-americanas inferiores a 0,2%. A diversidade linguística aumentou até certo ponto, mas permanece concentrada em muitas línguas dominantes.
- GPT-4, ChatGPT e outros modelos contribuíram enormemente para o crescimento de conjuntos de dados artificiais, que agora representam uma parcela crescente de dados de treinamento, especialmente para tarefas criativas e produtivas.
- A falta de transparência e a persistência do preconceito centrado no Ocidente exigem auditorias rigorosas e procedimentos equitativos na compilação de conjuntos de dados.
Para concluir, esta revisão abrangente esclarece a crescente dependência de dados artificiais e rastreados na Web, o desequilíbrio contínuo na representação e a dificuldade de licenciar conjuntos de dados multiobjetos. Ao identificar estes desafios, os investigadores fornecem orientações para a criação de sistemas de IA transparentes, equitativos e responsáveis. O seu trabalho sublinha a necessidade de monitorização e medidas contínuas para garantir que a IA serve diversas comunidades de forma eficaz e eficiente. Este estudo é um apelo à ação para que profissionais, decisores políticos e investigadores resolvam os desequilíbrios estruturais no ecossistema de dados de IA e priorizem a transparência na utilização de dados.
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research lança EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem comandos incomparáveis de próxima geração e insights de conteúdo de longo prazo para liderança global em excelência em IA generativa….
Sana Hassan, estagiária de consultoria na Marktechpost e estudante de pós-graduação dupla no IIT Madras, é apaixonada pelo uso de tecnologia e IA para enfrentar desafios do mundo real. Com um profundo interesse em resolver problemas do mundo real, ele traz uma nova perspectiva para a interseção entre IA e soluções da vida real.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


