
Um grande desafio nos sistemas de conversão de texto em fala (TTS) são as ineficiências computacionais do algoritmo Monotonic Alignment Search (MAS), responsável por estimar o alinhamento entre sequências de texto e fala. O MAS enfrenta grandes dificuldades de tempo, especialmente quando se trata de grandes insumos. A complexidade é O(T×S), onde T é o comprimento do texto e S é o comprimento da representação da expressão. À medida que o tamanho da entrada aumenta, a carga computacional torna-se incontrolável, especialmente se o algoritmo for executado sequencialmente sem processamento paralelo. Essa ineficiência prejudica seu desempenho em aplicações de tempo real e de larga escala em modelos TTS. Portanto, abordar esta questão é importante para melhorar a escalabilidade e o desempenho dos sistemas TTS, permitindo o rápido treinamento e interpretação de todas as tarefas de IA que requerem alinhamento de sequência.
As implementações atuais do MAS são baseadas em CPU e usam Cython para acompanhar os tamanhos de heap. No entanto, esses métodos usam loops aninhados para cálculos de alinhamento, o que aumenta bastante a carga computacional de grandes conjuntos de dados. Além disso, a necessidade de transferências de memória entre dispositivos entre a CPU e a GPU introduz latência adicional, tornando esses métodos ineficientes para aplicações em larga escala ou em tempo real. Além disso, o max_neg_val usado nos métodos tradicionais é definido como -1e9, o que é insuficiente para evitar incompatibilidade de alinhamento, especialmente nas áreas diagonais superiores da matriz de alinhamento. A incapacidade de explorar totalmente a compatibilidade da GPU é outra limitação importante, já que os métodos atuais são frequentemente limitados pelas restrições de processamento das CPUs, resultando em tempos de execução mais lentos à medida que o tamanho da entrada aumenta.
Uma equipe de pesquisadores da Universidade Johns Hopkins e da Supertone Inc. eles propõem Super-MAS, uma solução inovadora que usa scripts Triton e scripts PyTorch JIT para otimizar o MAS para execução de GPU, eliminando loops de entrada e transferências de memória entre dispositivos. Ao combinar o comprimento máximo do texto, este método reduz bastante a complexidade computacional. A introdução de um max_neg_val maior (-1e32) reduz a incompatibilidade de alinhamento, melhorando a precisão geral. Além disso, o cálculo local dos valores de ocorrência do log reduz a alocação de memória, simplificando ainda mais o processo. Essa melhoria torna o algoritmo mais eficiente e escalável, especialmente para aplicações TTS em tempo real ou outras tarefas de IA que exigem alinhamento de sequência em grande escala.
Super-MAS é implementado vetorizando o tamanho do texto usando kernels Triton, em contraste com os métodos convencionais de tamanho de cluster com Cython. Esse rearranjo elimina os loops aninhados que anteriormente retardavam o cálculo. Uma matriz de log-verossimilhança é inicializada e os alinhamentos são calculados usando programação dinâmica, com loops de avanço e retrocesso que iteram sobre a matriz para calcular e reconstruir caminhos de alinhamento. Todo o processo é implementado na GPU, evitando ineficiências causadas pela transferência de dispositivos entre CPU e GPU. Uma série de testes foi realizada usando estimadores de log-verossimilhança com tamanho de lote B=32, comprimento de texto T e comprimento de fala S=4T.
O Super-MAS alcança uma melhoria significativa na velocidade de execução, com o kernel Triton executando de 19 a 72 vezes mais rápido do que o Cython, dependendo do tamanho da entrada. Por exemplo, com um comprimento de texto de 1.024, o Super-MAS completa sua tarefa em 19,77 milissegundos, em comparação com 1.299,56 milissegundos do Cython. Essa aceleração é especialmente perceptível à medida que o tamanho da entrada aumenta, o que garante que o Super-MAS seja altamente escalável e eficiente para lidar com grandes conjuntos de dados. Também é mais eficiente que as versões PyTorch JIT, especialmente para entradas grandes, tornando-o uma boa escolha para aplicações em tempo real em programas TTS ou outras tarefas que requerem alinhamento de sequência eficiente.
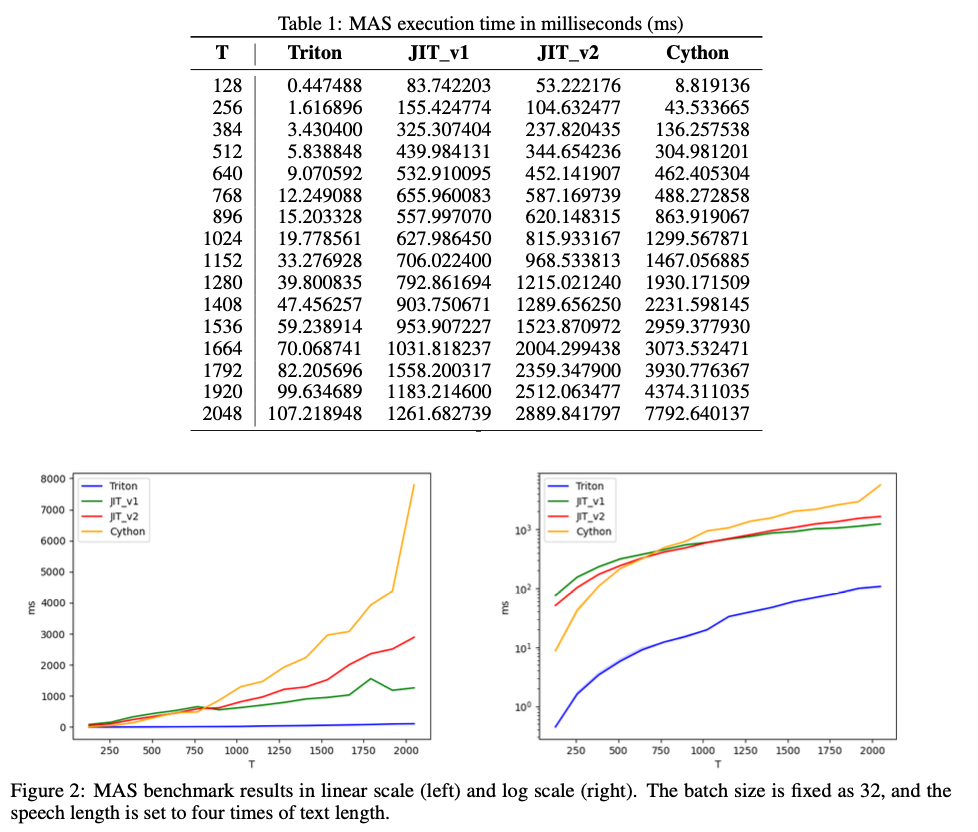
Concluindo, o Super-MAS apresenta uma solução aprimorada para os desafios computacionais da Pesquisa de Alinhamento Monotônico em aplicações TTS, que alcança uma redução significativa na complexidade do tempo através do paralelismo da GPU e otimização da memória. Ao eliminar a necessidade de loops aninhados e relés de dispositivos intermediários, ele oferece um método altamente eficiente e escalonável para operações de alinhamento sequencial, oferecendo uma aceleração de até 72 vezes em comparação aos métodos existentes. Essa inovação permite um processamento mais rápido e preciso, tornando-o útil para aplicações de IA em tempo real, como TTS e muito mais.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


