
Imagine que você tem um laudo de raio-x e precisa entender quais lesões possui. Outra opção é que você pode visitar o médico que deveria, mas por algum motivo, se não puder, você pode usar Modelos Multimodais de Grande Linguagem (MLLMs) que processarão seu raio-x e informarão exatamente qual lesão você tem no digitalizar.
Em palavras simples, MLLMs nada mais são do que uma combinação de vários modelos como texto, imagem, voz, vídeos, etc. ele pode processar não apenas uma pergunta de texto padrão, mas também pode processar perguntas de várias maneiras, como imagens e sons.
Portanto, neste artigo, explicaremos o que são MLLMs, como funcionam e quais são os principais MMLMs que você pode usar.
O que são LLMs multimodais?
Ao contrário dos LLMs tradicionais, que só podem funcionar com um tipo de dados – normalmente texto ou imagem, esses LLMs de vários tipos podem funcionar com vários tipos de dados, como a forma como os humanos podem processar visão, voz e texto de uma só vez.
Basicamente, a IA multimodal utiliza vários tipos de dados, como texto, imagens, áudio, vídeo e dados de sensores, para fornecer insights e interações mais ricas e complexas. Considere um sistema de IA que não apenas olhe para uma imagem, mas também possa descrevê-la, compreender o contexto, responder perguntas sobre ela e gerar conteúdo relacionado com base em vários tipos de entrada.
Agora, vamos pegar o mesmo exemplo de relatório de raio-x com contexto de como um LLM multimodal entenderá seu contexto. Aqui está uma animação simples que explica como processar uma imagem primeiro com um codificador de imagem para converter a imagem em vetores e depois usar um LLM treinado em dados médicos para responder à pergunta.
Fonte: IA médica multimodal do Google
Como funcionam os LLMs multimodais?
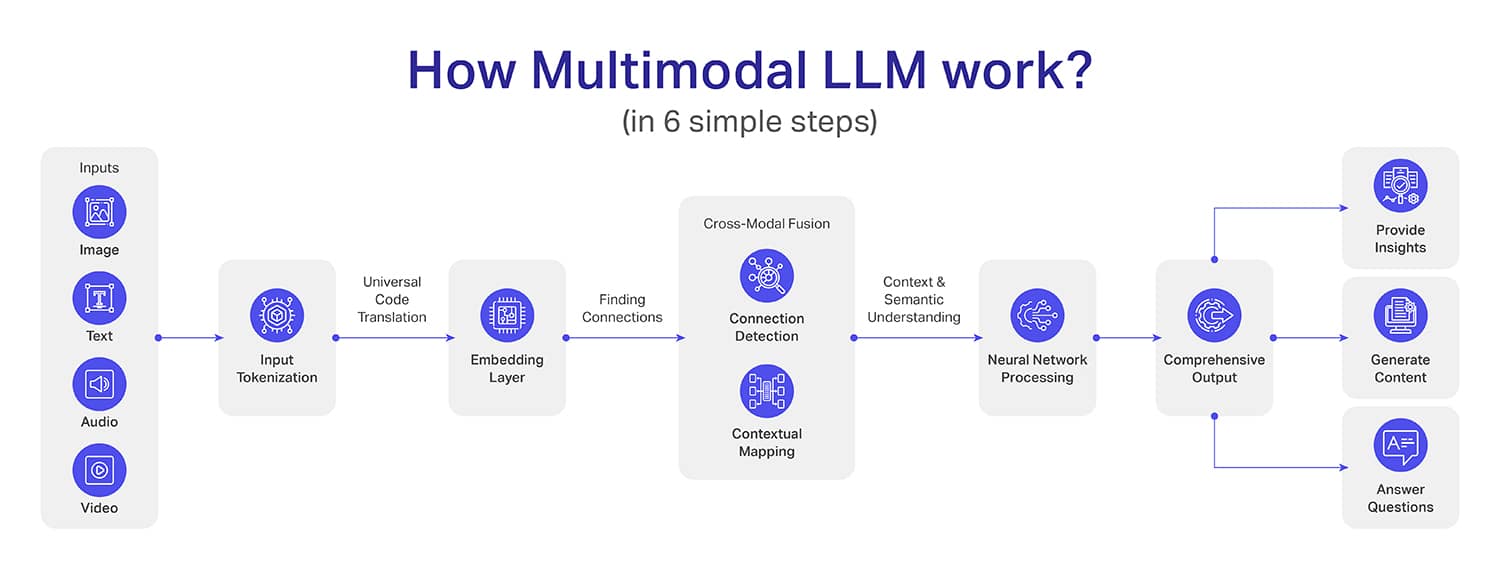
Embora o funcionamento interno dos LLMs multimodais seja complexo (mais do que os LLMs), tentamos dividi-los em seis etapas simples:
Etapa 1: coleta de instalação – Esta é a primeira etapa onde os dados são coletados e processados pela primeira vez. Por exemplo, as imagens são transformadas em pixels geralmente usando arquiteturas de redes neurais convolucionais (CNN).
A entrada de texto é convertida em tokens usando algoritmos como BytePair Encoding (BPE) ou SentencePiece. Por outro lado, os sinais de áudio são convertidos em espectrogramas ou coeficientes cepstrais de frequência mel (MFCCs). Os dados de vídeo são, no entanto, divididos quadro a quadro de maneira sequencial.
Etapa 2: Tokenização – A ideia por trás da tokenização é converter os dados em um formato padrão para que uma máquina possa compreender seu contexto. Por exemplo, para converter texto em tokens, é usado o processamento de linguagem natural (PNL).
Para tokenização de imagens, o sistema usa redes neurais pré-treinadas semelhantes às arquiteturas ResNet ou Vision Transformer (ViT). Os sinais de áudio são convertidos em tokens usando técnicas de processamento de sinal para que as ondas de áudio sejam convertidas em expressões coerentes e lógicas.
Etapa 3: Camada de incorporação – Nesta etapa, os tokens (que obtivemos na etapa anterior) são transformados em vetores densos de forma que esses vetores possam capturar o contexto dos dados. O que devemos notar aqui é que cada método otimiza seus vetores de forma mais próxima dos outros.
Etapa 4: fusão intermodal – Até agora, os modelos conseguiram compreender os dados até o nível de cada modelo, mas a partir do passo 4 isso muda. Na integração intermodal, o sistema aprende a conectar os pontos entre múltiplas modalidades para relacionamentos contextuais profundos.
Um bom exemplo é combinar a imagem de uma praia, uma representação escrita de férias na praia e clipes sonoros de ondas, vento e uma multidão feliz. Desta forma, o LLM multimodal não apenas entende a entrada, mas também integra tudo como um só.
Etapa 5: Processamento de Rede Neural – O processamento da rede neural é a etapa na qual as informações coletadas na integração intermodal (etapa anterior) são transformadas em informações lógicas. Agora, o modelo usará aprendizagem profunda para analisar as interações complexas descobertas durante a integração intermodal.
Imagine a situação ao combinar relatórios de raios X, anotações do paciente e descrições de sintomas. Através do processamento de redes neurais, ele não apenas listará os fatos, mas também criará um entendimento abrangente que pode identificar potenciais riscos à saúde e sugerir possíveis diagnósticos.
Etapa 6 – Gerando Saída – Esta é a última etapa em que o MLM irá gerar resultados precisos para você. Ao contrário dos modelos tradicionais que muitas vezes são limitados ao contexto, o resultado do MLM terá profundidade e compreensão do contexto.
Além disso, a saída pode estar em mais de um formato, como a criação de um conjunto de dados, a criação de uma representação visual de uma situação ou até mesmo a saída de áudio ou vídeo de um evento específico.
Quais são as aplicações de exemplos de linguagem multimodal?
Embora MLLM seja um termo recém-criado, existem centenas de aplicações onde você encontrará melhorias dramáticas em comparação aos métodos tradicionais, tudo graças ao MLLM. Aqui estão algumas aplicações importantes de MLM:


