
A Arquitetura do Transformer permitiu que modelos linguísticos em larga escala (LLMs) executassem tarefas complexas de compreensão e criação de linguagem natural. No centro do Transformer está um mecanismo de atenção projetado para atribuir valores a vários tokens em sequência. No entanto, este processo distribui a atenção de forma desigual, muitas vezes dando foco a situações sem importância. Este fenômeno, conhecido como “ruído de atenção”, dificulta a capacidade do modelo de identificar e usar com precisão informações importantes de sequências de longo alcance. Torna-se especialmente problemático em aplicações como resposta a perguntas, resumos e leitura contextual, onde uma compreensão clara e precisa do contexto é importante.
Um dos principais desafios enfrentados pelos investigadores é garantir que estas amostras possam ver claramente e concentrar-se nas partes mais relevantes do texto sem se distrairem com o contexto circundante. Esse problema se torna mais pronunciado ao dimensionar os modelos em relação ao tamanho e aos tokens de treinamento. O ruído atencional interfere na aquisição de informações importantes e leva a problemas como alucinações, em que os modelos produzem informações factuais incorretas ou não seguem a coerência lógica. À medida que os modelos crescem, estes problemas tornam-se mais difíceis de resolver, tornando importante o desenvolvimento de novos métodos para eliminar ou reduzir o ruído atencional.
Os métodos anteriores de lidar com o ruído de atenção incluíram modificação estrutural, tipo de treinamento ou técnicas de adaptação. No entanto, estas soluções têm frequentemente um compromisso em termos de aumento da complexidade ou diminuição da eficiência dos modelos. Por exemplo, algumas estratégias de desempenho baseiam-se em mecanismos de atenção adaptativos que ajustam o foco com base no contexto, mas esforçam-se por manter um desempenho consistente em condições de contexto de longo prazo. Outros incluem técnicas avançadas de normalização, mas acrescentam sobrecarga e complexidade computacional. Como resultado, os investigadores têm procurado formas simples mas eficazes de melhorar o desempenho dos LLMs sem comprometer a escalabilidade ou a eficiência.
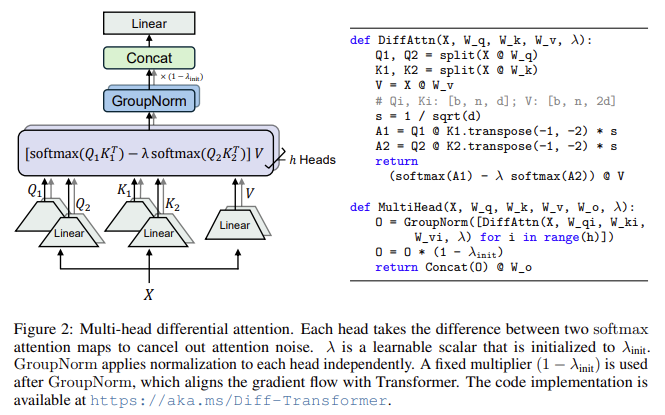
Pesquisadores da Microsoft Research e da Universidade de Tsinghua introduziram uma nova estrutura chamada i Transformador Diferencial (Transformador DIFF). Esta nova arquitetura aborda o problema do ruído atencional, introduzindo uma abordagem de atenção segmentada que filtra efetivamente o contexto irrelevante e, ao mesmo tempo, maximiza a atenção a segmentos significativos. O método de atenção diferencial funciona dividindo os vetores de consulta e chave em dois grupos e combinando dois mapas de atenção softmax diferentes. A diferença entre esses mapas atua como um efeito final de atenção, cancelando o ruído de modo comum e permitindo que o modelo gire com mais precisão para as informações do alvo. Este método é inspirado em conceitos da engenharia elétrica, como amplificadores diferenciais, onde o ruído comum é cancelado pela diferença entre dois sinais.
O Transformador DIFF consiste em várias camadas que contêm um módulo de atenção diferencial e uma rede feed-forward. Mantém a macroestrutura do Transformer original, garantindo a compatibilidade com as estruturas existentes ao mesmo tempo que introduz novas funcionalidades a um nível micro. O modelo inclui melhorias como pré-RMSNorm e SwiGLU, emprestados do design LLaMA, que contribuem para a melhoria da robustez e eficiência durante o treinamento.
O Transformador DIFF supera os Transformadores tradicionais em diversas áreas importantes. Por exemplo, ele alcança desempenho comparável de modelagem de linguagem usando apenas 65% do tamanho dos modelos e tokens de treinamento exigidos pelos Transformers convencionais. Isto se traduz em uma redução de 38% no número de parâmetros e em uma redução de 36% no número de tokens de treinamento necessários, levando diretamente a um modelo mais eficiente em termos de recursos. Quando ampliado, o Transformador DIFF com 7,8 bilhões de parâmetros atinge a mesma perda de modelagem linguística que o Transformador de 13,1 bilhões de parâmetros, igualando assim o desempenho e usando 59,5% menos parâmetros. Isso mostra a robustez do Transformador DIFF, que permite o tratamento eficiente de grandes operações de PNL com baixíssimo custo computacional.
Em uma série de testes, o DIFF Transformer mostrou uma capacidade notável de encontrar informações importantes, superando o Transformer padrão em até 76% em tarefas onde informações importantes foram incorporadas na primeira metade de um longo contexto. No experimento “Needle-In-A-Haystack”, onde as respostas corretas foram colocadas em diferentes posições em condições de até 64.000 tokens, o Transformador DIFF manteve uma precisão consistentemente alta, mesmo na presença de distratores. O Transformer tradicional, em comparação, viu um declínio constante na precisão à medida que o comprimento do contexto aumentava, destacando a capacidade superior do DIFF Transformer de manter o foco no conteúdo apropriado.
O Transformador DIFF reduziu significativamente os níveis de alucinações em comparação com os modelos convencionais. Em análises detalhadas usando conjuntos de dados de resposta a consultas, como Qasper, HotpotQA e 2WikiMultihopQA, o DIFF Transformer alcançou uma precisão 13% maior na resposta a consultas de texto único e uma melhoria de 21% na resposta a consultas multitexto. Alcançou uma taxa média de precisão de 19% em tarefas de resumo de texto, reduzindo efetivamente a geração de resumos incorretos ou enganosos. Estes resultados enfatizam a robustez do Transformador DIFF em diferentes aplicações de PNL.
O método de atenção diferencial também melhora a estabilidade do DIFF Transformer ao trabalhar com permissões principais do sistema. Ao mesmo tempo, os Transformers tradicionais apresentam alta variação no desempenho quando a ordem do conteúdo muda. O Transformador DIFF apresentou pouca flutuação no desempenho, indicando um alto grau de ordenação de sensibilidade. Numa análise comparativa, o desvio padrão da precisão do Transformador DIFF para todas as permutações multiordem foi inferior a 2%, enquanto o desvio padrão do Transformador foi superior a 10%. Esta estabilidade torna o DIFF Transformer particularmente adequado para aplicações que envolvem aprendizagem in-context, onde a capacidade do modelo de utilizar informações de um contexto dinâmico é importante.


Concluindo, DIFF Transformer apresenta a primeira abordagem para lidar com ruído de atenção em grandes modelos de linguagem. Utilizando uma abordagem atencional diferente, o modelo pode atingir alta precisão e robustez com poucos recursos, posicionando-o como uma solução promissora para pesquisas acadêmicas e aplicações no mundo real.
Confira Papel de novo Usando o código. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – Conferência de recuperação de dados GenAI (promovida)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.


