
Projetar agentes autônomos capazes de navegar em ambientes web complexos levanta muitos desafios, especialmente quando tais agentes integram informações textuais e visuais. Em grande medida, os agentes têm capacidades limitadas, uma vez que estão confinados a ambientes artificiais, baseados em scripts, com sinais de recompensa bem concebidos, limitando as suas aplicações às tarefas do mundo real de navegação na web. O principal desafio é que capacitar um agente capaz de interpretar conteúdo multimodal – incluindo entrada visual e textual – sem sinais de feedback claros continua sendo um dos problemas mais difíceis da IA. Estes agentes também necessitarão de aprender e adaptar-se dinamicamente ao mundo real de ambientes online em constante mudança, o que em muitos casos exigirá o seu desenvolvimento contínuo e auto-aperfeiçoamento de diversas interacções web e tarefas de navegação.
Os métodos de navegação na web existentes dependem de grandes modelos de linguagem, como GPT-4o ou outros modelos multimodais de código fechado. Embora funcionem bem em ambientes formais e somente de texto, sua robustez em um ambiente complexo do mundo real permanece baixa. Apenas alguns deles, como WebVoyager e VisualWebArena, estendem esses modelos para configurações multimodais considerando capturas de tela e documentos, mas ainda dependem de modelos de código fechado e configurações de treinamento sintético. Devido à perspectiva limitada de muitos métodos e à falta de uma base física para a representação subjacente, estes modelos não podem evoluir fora de um ambiente controlado. Outra limitação dos métodos existentes é a sua dependência de sinais de recompensa bem definidos, que faltam em grande parte nas tarefas do mundo real. Embora os modelos de linguagem de visão de código aberto sejam cada vez mais acessíveis, como BLIP-2-T5 e LLaVA, a sua profunda compreensão contextual torna-os inadequados para tarefas complexas de navegação na web. Eles são limitados desde a aplicação até o aprendizado não supervisionado em situações multimodais do mundo real.
Pesquisadores da Universidade de Zhejiang, do Tencent AI Lab e da Westlake University apresentam o OpenWebVoyager, uma estrutura de código aberto que incentiva ciclos contínuos de autoaprendizagem em ambientes da Web do mundo real. Construtores de habilidades locais qualificados utilizam o aprendizado de simulação (IL) em uma forma iterativa de feedback onde os agentes, ao simular interações com páginas da web, aprendem primeiro habilidades básicas de navegação, após o que seu desempenho pode ser continuamente melhorado testando novas tarefas e coletando feedback. e otimização baseada em trajetórias bem-sucedidas. Com o núcleo do modelo de linguagem de visão, Idefics2-8b-instruct, o OpenWebVoyager pode processar imagens e texto, permitindo compreender melhor situações do mundo real. A estrutura se auto-melhora em um ciclo de teste-feedback-otimização onde o GPT-4o avalia continuamente cada rota em relação à sua precisão, atualizando assim o agente iterativamente de acordo com seu desempenho. Portanto, isso permite o aprendizado e a otimização autônomos, impulsionando um passo à frente no crescimento e na adaptabilidade dos agentes web autônomos.
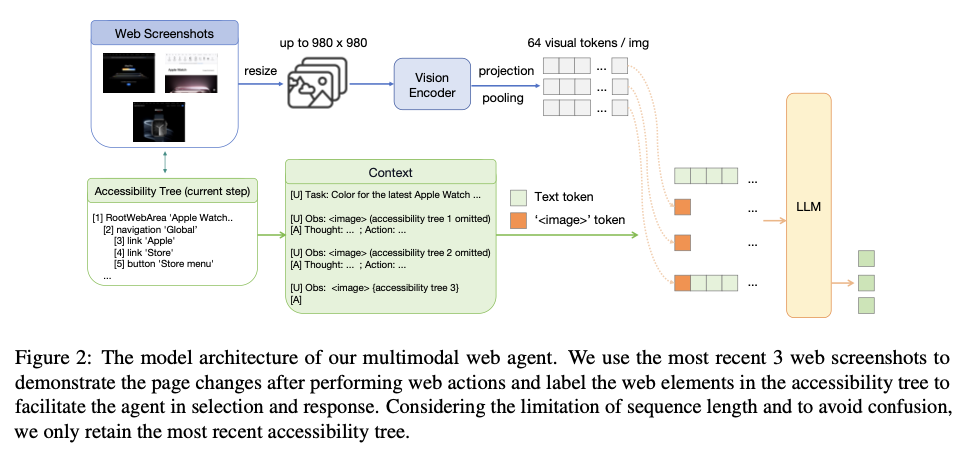
Para implementação, OpenWebVoyager usou Idefics2-8b-instruct, que é um modelo avançado para lidar com texto e dados visuais. Na primeira fase do estudo de simulação, foram recolhidos empregos em 48 websites relacionados com os diferentes domínios do comércio eletrónico, turismo e notícias, com 1516 perguntas específicas de empregos. Seus dados de treinamento consistem em trajetórias web multimodais com instruções operacionais básicas que orientam o agente. OpenWebVoyager usa a entrada correspondente de árvores de acessibilidade e capturas de tela de diferentes maneiras para implementar layouts de página complexos após passar por um ciclo de otimização iterativo. Cada iteração contém novos exemplos de perguntas, avaliação do sucesso da trajetória e retenção de trajetórias bem-sucedidas para melhorar o modelo. Essa abordagem de autoaprendizagem permite que o OpenWebVoyager acesse com eficiência todos os recursos visuais dinâmicos e tome decisões de desempenho com base nas características de uma página da web multimodal. Além disso, o modelo OpenWebVoyager processa até três capturas de tela para cada tarefa, garantindo um trabalho perfeito ao focar os recursos visuais na execução dessas tarefas com sucesso.
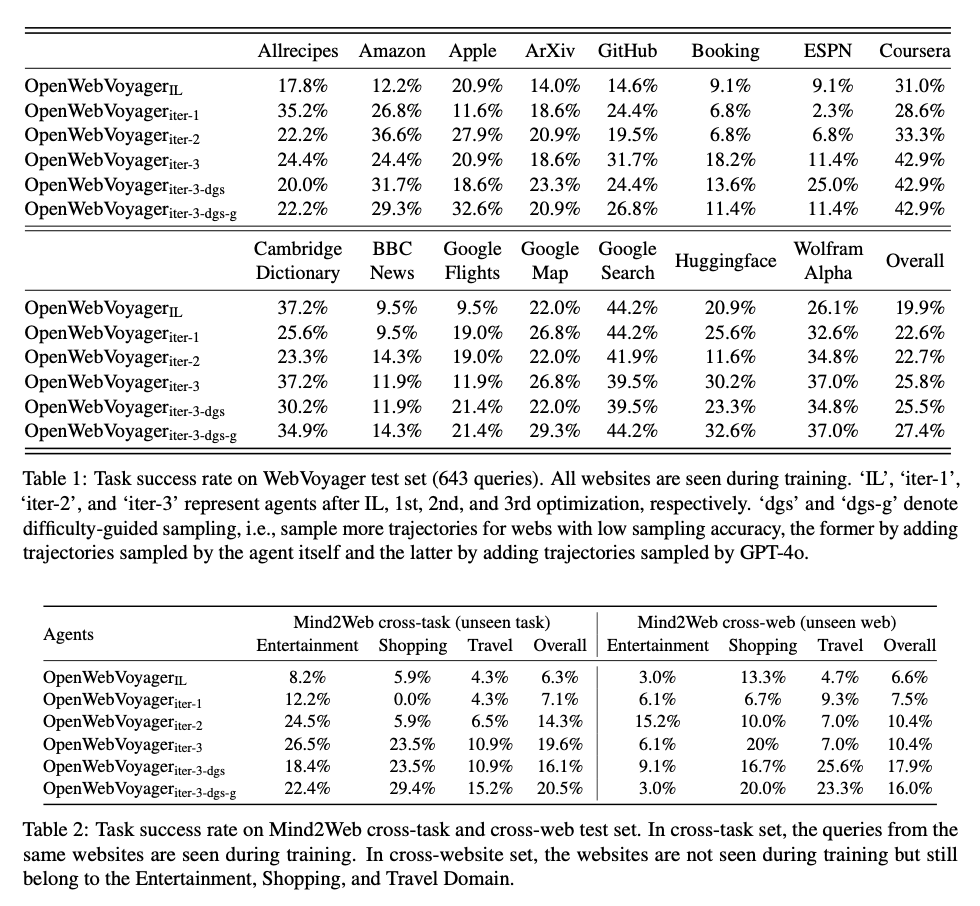
As enormes melhorias na taxa de sucesso feitas pelo OpenWebVoyager em benchmarks de navegação na web mostram um rápido crescimento com ciclos iterativos. Começando com uma taxa de sucesso de 19,9% após a fase de aprendizagem da simulação, o desempenho do agente aumentou para 25,8% após três ciclos de otimização no conjunto de testes WebVoyager. Durante o teste de tarefas e domínios abstratos com tarefas cruzadas e conjuntos de banco de dados Mind2Web, o agente melhora as taxas básicas de sucesso de 6,3% para 19,6% em domínios encontrados anteriormente, enquanto sua taxa de sucesso aumenta em cerca de 4% em sites novos. . São esses avanços, além dos princípios básicos, que sublinham a eficiência do método no OpenWebVoyager, onde o agente melhora suas habilidades de navegação na web com precisão e escalabilidade contínuas em vários ambientes da web.
Concluindo, o OpenWebVoyager representa um avanço na navegação web multimodal ao criar uma estrutura flexível e autoconfigurável que se aprimora em ciclos iterativos. Ao combinar simulação e aprendizagem experimental com feedback automatizado, a abordagem do OpenWebVoyager melhora o escopo de agentes web autônomos, permitindo escalabilidade em diferentes domínios sem amplo treinamento. Esta nova estrutura tem o potencial de melhorar a navegação na web no mundo real em áreas que vão desde o comércio eletrônico até a recuperação de informações, marcando um passo importante em direção a agentes de IA autônomos e multimodais nos ambientes dinâmicos da Internet.
Confira Papel de novo Página GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


