
Progresso em Inteligência multimodal Para praticar e entender fotos e vídeos. As imagens podem produzir cenas estáticas, fornecendo informações sobre os detalhes como objetos, texto e relacionamentos locais. No entanto, isso tem o custo de ser um grande desafio. O entendimento do vídeo inclui o rastreamento de mudanças ao longo do tempo, entre outras atividades, ao verificar o consenso, requer poderoso gerenciamento de conteúdo e relacionamentos temporários. Essas atividades são fortes porque a coleta e a descrição dos detalhes de texto em vídeo são difíceis em comparação com os dados de texto de dados.
Maneiras tradicionais de Grandes modelos da grande linguagem (MLMS) Lidar com os desafios da compreensão do vídeo. Ele se aproxima de independente e as imagens usadas pelas fotografias não instalam com êxito dependência temporária de conteúdo forte. As coletas de Tocken e expandidas pelo contexto que o Windows lutou com uma longa dificuldade em vídeo, enquanto combinando a instalação de áudio e visual geralmente não possui comunicação sólida. Os esforços para a visualização em tempo real e as habilidades de modelo permanecem desempregadas, e as estruturas existentes são projetadas para responder a longas atividades em vídeo.
Lidar com os desafios da compreensão de vídeo, pesquisadores de Grupo Alaba proposto Videolama3 Contorno. Este quadro inclui Reparo de qualquer memória (AVT) incluindo Podador de quadro diferente (difffp). A AVT está se desenvolvendo na tokenização tradicional tradicional, permitindo que os codificadores de deving processem a volatilidade, reduza a perda de informações. Isso está disponível em e-mails baseados em sincronização com corda 2D para posição flexível. Mantendo informações importantes, vários acordos com tokens de vídeo refrescantes e alitando os quadros que têm variações pequenas diferentes, como tirada uma distância de uma ordem ordinária entre os clipes. A hospedagem de uma forte decisão, em combinação com a redução de token eficaz, promove a representação e reduz os custos.
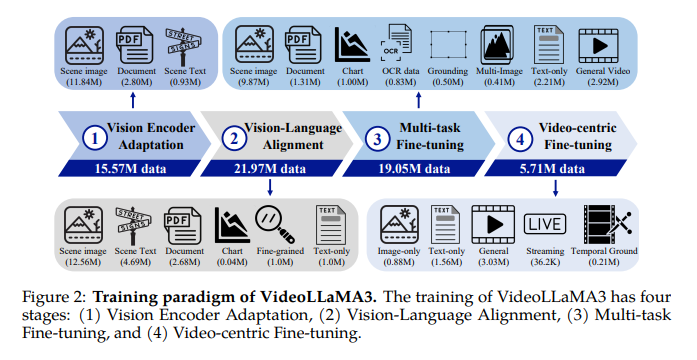
O modelo contém um Encoder de visão, compressor de vídeo, projetor, incluindo Modelo maior da linguagem (LLM)Inicia o codificador de visão usando o modelo do siglip anteriormente treinado. A emissão de tokens visíveis, enquanto o vídeo compressa reduz a representação do token de vídeo. O projeto coordena a visão do codificador no LLM e os modelos QWEN2.5 usados para o LLM. O treinamento ocorre em quatro seções: transformação do codificador do codificador, alinhamento, formulação de bom idioma, ordem de vídeo da vídeo-centrúica. As três primeiras categorias se concentram no entendimento das imagens, e a fase final melhora a compreensão do vídeo, inserindo informações temporárias. Esta página Codificador codificador codificador codificador Ele se concentra no bom planejamento da visão do codificador, contratado pela Siglip, nos principais dados da imagem, permitindo processar figuras em diferentes decisões. Esta página A seção de avaliação da visão da visão Informações das informações multimodais, tornando a visão de um LLM e o codificador acessível para combinar o entendimento e o entendimento dos idiomas. Em Um centro de educação de muitosO bom sistema de ensino é feito usando perguntas multimodais, incluindo perguntas de imagem e vídeo, aprimorando o poder do escritório de advocacia ambiental e processando informações temporárias. Esta página Pesquisa em estágio em vídeo-centrínico Define todos os parâmetros para desenvolver habilidades de compreensão do modelo. Os detalhes do treinamento aparecem em várias fontes, como cenas, documentos, gráficos, fotografia e dados de vídeo, confirmando a desconexão multimodal completa.
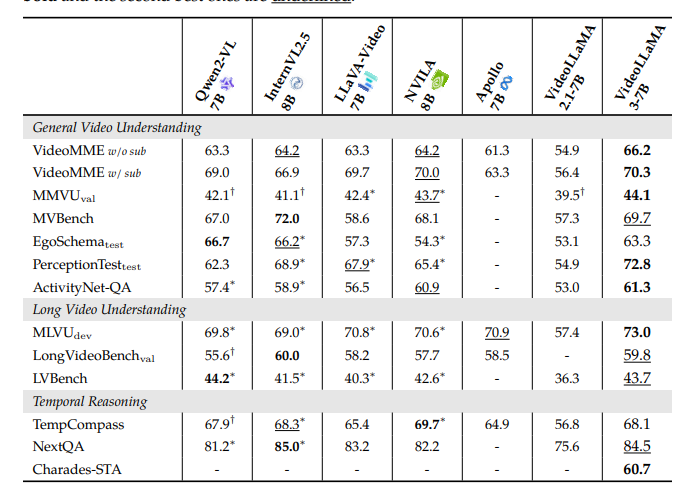
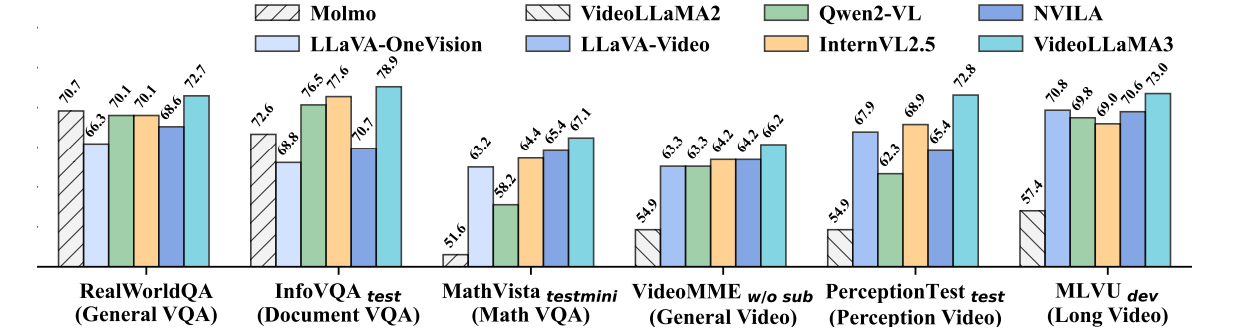
Os investigadores executam os exames de teste de desempenho de Videolama3 para atividades de imagem e vídeo. Com as atividades baseadas na ilustração, o modelo foi testado no entendimento do documento, pensamento matemático e multiplicação, onde os modelos anteriores passaram, mostrando o entendimento do gráfico e do país original do país. Para responder à pergunta (QA). Nas atividades baseadas em vídeo, o videotama3 é firmemente feito de bancos como Videileme incluindo MvbanchSer hábil com um entendimento geral de vídeo, compreensão de vídeo longo e pensamento temporário. Esta página 2SE incluindo 7 Os modelos são muito competitivos e 7 O modelo principal em muitas atividades em vídeo, enfatizando o funcionamento do modelo em atividades multimodais. Algumas áreas do relatório do OCR são relatadas pelo OCR, estatísticas de consulta, entendimento múltiplo e entendimento de vídeo de longo prazo.
Finalmente, a estrutura proposta está desenvolvendo o desenvolvimento de modelos multimodais e modelos modimodais multimodais, que fornecem um esboço sólido para entender fotos e vídeos. Usando o texto de texto de alto texto, ele lida com os desafios das gravações de vídeo e da energia temporária, eles alcançam fortes resultados em todos os bancos. No entanto, desafios como dados de vídeo. Pesquisas futuras podem melhorar as informações de texto em vídeo, fazer bem para realizar o desempenho real e combinar modificados adicionais, como som e falar. Este trabalho pode servir de base para o desenvolvimento futuro no entendimento multimral, para melhorar a eficiência, o comum e a integração.
Enquete Página e papel do github. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 70k + ml subreddit.
🚨 [Recommended Read] O Nebius AI Studio está aumentando em modelos de observatório, novos modelos de idiomas, incorporação e Lora (Atualizado)
Divyesh é um contato no MarkteachPost. Perseguindo a BTECH para engenheiros agrícolas e alimentares no Instituto Indiano de Tecnologia, Kharagpur. Ele é um amante científico científico e típico que deseja combinar essa tecnologia líder no histórico agrícola e resolver desafios.
'Multiate' Equipment ': uma ferramenta para gerenciar projetos privados (patrocinados)

 para PCs Intel")
