
O Modelo de Língua Principal (LLM) concentra -se na avaliação de modelos e no aumento do poder da primeira fase de treinamento. Inclui a boa direção de boas estruturas (SFT) e a validade de modelos de modelos para preferências pessoais e requisitos específicos. A geração de dados é importante, permite que os investigadores verifiquem e melhorem as estratégias de aprendizado em segundo plano. No entanto, um estudo aberto sobre esse domínio está em seu primeiro nível, enfrenta a disponibilidade de dados e as limitações de escala. Sem informações de alta qualidade, é difícil analisar o desempenho de diferentes estratégias de conversão e avaliar sua funcionalidade com os aplicativos de propriedade reais.
Um dos principais desafios do campo não é uma escala em larga escala, é encontrada em informações contábeis públicas nos detalhes pós-treinamento do LLM. Os investigadores devem acessar vários lãs de bate -papo para fazer estratégias de alinhamento comparativas e em desenvolvimento de significado. A falta de conjuntos de dados padrão limita a capacidade de avaliação pós-treinamento em diferentes modelos. Além disso, o principal custo da geração das necessidades de capital e racial é impedido de muitas instituições educacionais. Esses itens criam barreiras para melhorar a eficiência do modelo e garantir que LLMs bem organizados sejam comuns nas atividades e interação do usuário.
Os métodos existentes para o Código de Dados para o Código de Treinamento LLM depende da combinação de modelos gerados e dos detalhes do celeiro. Conjuntos de dados, como WillDChat-1M de Allen AI Nelsys-Chat-1M, fornecem um entendimento importante no uso de dados de dados. No entanto, eles geralmente são limitados à diversidade de taxas e modelo. Os investigadores desenvolvem várias estratégias para avaliar a qualidade dos dados, incluindo a avaliação do LLM e o desempenho elétrico eficiente para operar a operação e o uso do VRAM. Apesar desses esforços, o território ainda não possui o conjunto de dados completo e acessível à comunidade que permite um ótimo exame e métodos de treinamento eficazes em segundo plano.
Os investigadores da Universidade de Nova York (NYU) introduziram o WildChat-50M, um amplo conjunto de dados projetado para facilitar o treinamento pós-operatório. Os dados estão criando uma coleção selvagem e o estende para incluir respostas de modelos abertos. Esses modelos variam de 0,5 a 104 bilhões de parâmetros, tornando publicamente o WildChat-50m dos maiores e muito diferentes dados de comunicação. Os dados estão permitindo comparações mais amplas de modelos de geração de dados e são o básico para o desenvolvimento das estratégias de treinamento em segundo plano. Ao tornar o WildChat-50m acessível, um grupo de pesquisadores pretende fechar a lacuna entre o treinamento industrial e a pesquisa educacional.
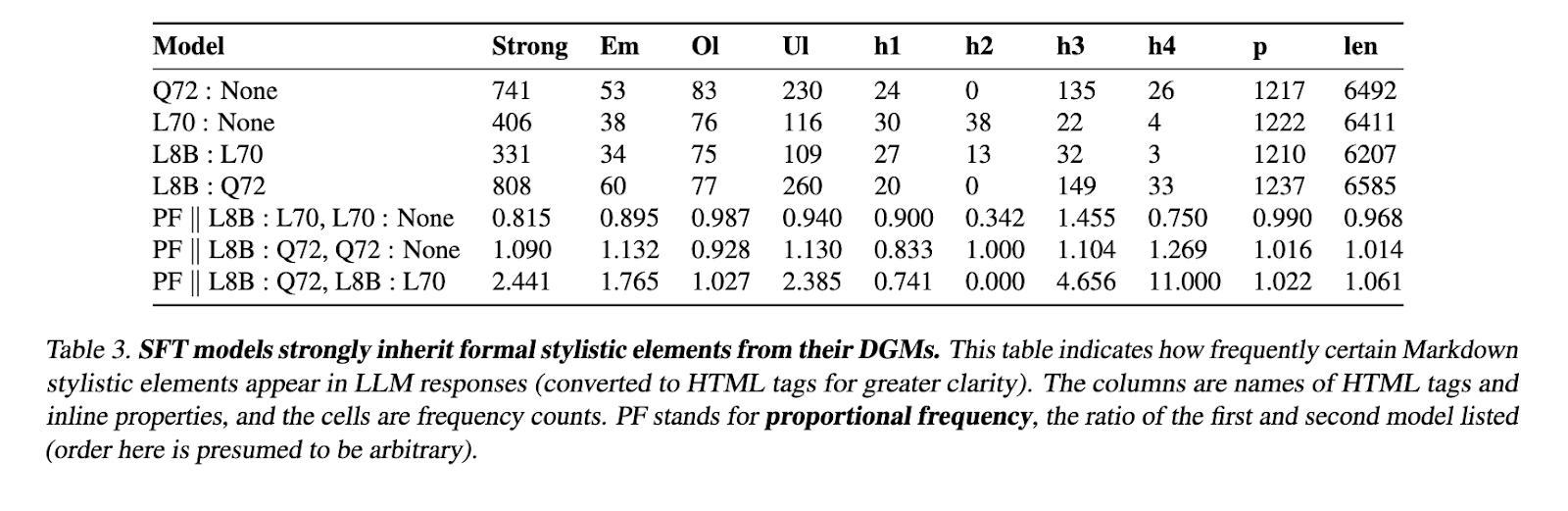
Os dados são desenvolvidos comparando os textos de escrita de muitos modelos, cada um participando de mais de um milhão de conversas. Os dados contêm aproximadamente 125 milhões de conversas, fornece um evento que já estava disponível anteriormente. O processo de coleta de dados ocorre durante dois meses usando um cluster de pesquisa compartilhado de GPU 12 × 8 H100. Essa configuração é permitida que os pesquisadores façam bom uso do tempo de trabalho e assegurem respostas diferentes. O conjunto de dados também atua como uma fundação re-wild, o destaque da mistura de ajuste fina (SFT) desenvolve a eficiência do LLM. Dessa forma, os pesquisadores demonstraram com sucesso o WildChat-50m para preparar o uso de dados, mantendo o desempenho funcional de alto eficácia.
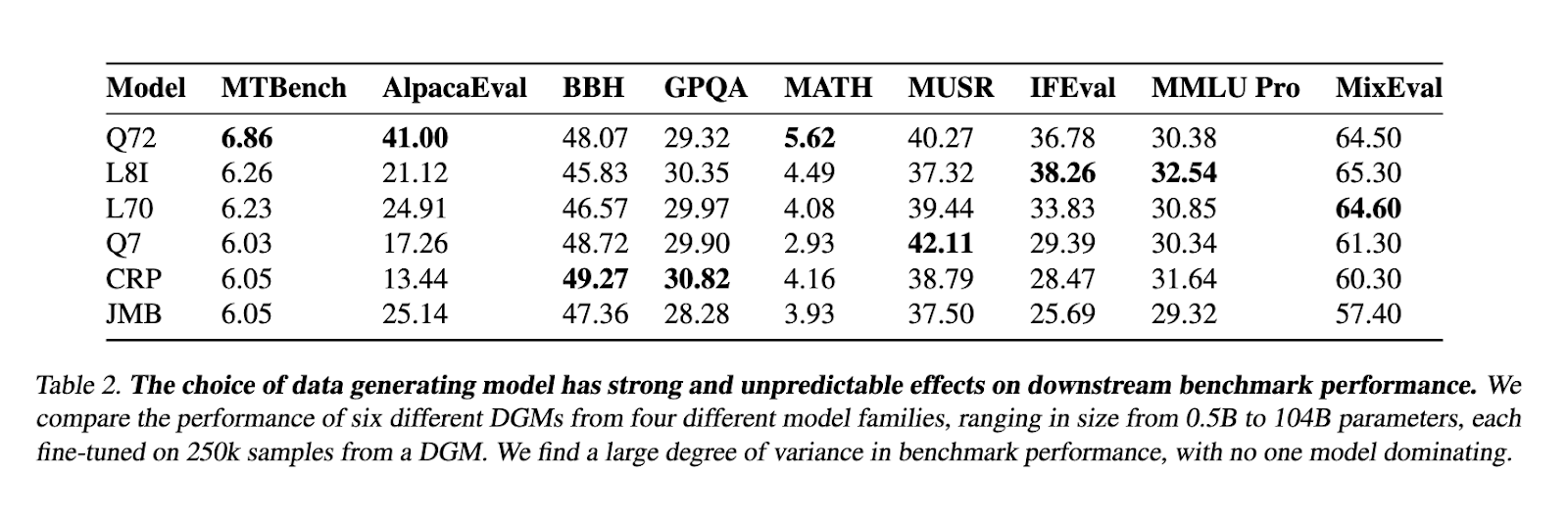
A operação WildChat-50M foi confirmada por uma série de bancos duros. O método SALD ST-WILD, baseado no WILLDCHAT-50M, a combinação sobrecarregada de Tulu-3 SFT desenvolvida por Allen AI enquanto utiliza 40% do tamanho dos dados. O teste inclui várias operações, para o desenvolvimento de algo em resposta, alinhando o modelo e a precisão da medição. Detalhes do desenvolvimento de dados do desenvolvimento de dados durante o processo de trabalho também foram destacados, em troca de trocas de análise que ilustram uma maior melhoria na velocidade do token. Além disso, modelos bem organizados usam WildChat-50m para indicar aprimoramentos importantes nas habilidades após o treinamento e as habilidades de desempenho para discutir todos os vários bancos de teste.
Este estudo enfatiza a importância dos dados mais altos da execução no LLM pós-treinamento e produz WildChat-50m como uma fonte importante para ajustar o alinhamento do modelo. Ao fornecer grandes dados disponíveis ao público, os pesquisadores permitiram desenvolvimento adicional na direção de bons métodos de planejamento. A análise comparativa deste estudo fornece a principal compreensão da eficiência dos modelos que geram diferentes dados e estratégias de aprendizado. MOVIMENTO, espera-se que a introdução do WildChat-50M seja financiada para investigar declarações em declarações e indústrias de pesquisa, incluindo eventualmente idiomas qualificados e flexíveis.
Enquete Papel, conjunto de dados no rosto e github. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 O Marktechpost está gritando para as empresas / inicialização / grupos cooperarem com as próximas revistas da IA a seguinte 'fonte AI em produção' e 'e' Agentic AI '.
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
✅ [Recommended] Junte -se ao nosso canal de telégrafo


