
Grandes modelos de linguagem (LINMS), como GPT, Gêmeos e Claude, usaram grandes informações de treinamento e estruturas complexas para produzir respostas de alta qualidade. No entanto, indo bem, a combinação de seu período de telefone é sempre desafiadora, pois o tamanho crescente do modelo leva a um alto custo de integração. Os alunos continuam avaliando as estratégias que aumentam a eficiência, mantendo ou melhorando o modelo.
Uma maneira que foi amplamente alcançada no desenvolvimento do desenvolvimento da LLM, onde muitos modelos estão sendo incluídos para produzir a última saída. O Mixture-of-Off-Agents (MOA) é um método famoso que inclui um caminho que inclui as respostas de diferentes LLMs para compilar uma resposta de maior qualidade. No entanto, esse método introduz o comércio básico entre diversidade e qualidade. Embora inclua vários modelos pode fornecer benefícios, também pode levar a um desempenho menos temporário devido ao envio de respostas de baixa qualidade. Os investigadores pretendem medir esses itens para garantir a eficiência sem comprometer a qualidade da resposta.
A estrutura tradicional do MOA trabalha com o início dos vários modelos Pusar para produzir as respostas. Modelo agregado e inclui essas respostas para a última resposta. A operação desse método depende da imaginação de que as diferenças entre os modelos do Proaser levam a um melhor desempenho. No entanto, o pensamento não está mudando a degeneração de uma possível qualidade causada por modelos mais fracos na mistura. O estudo anterior concentra -se em aumentar a diversidade, em vez de reparar a qualidade do modelo, o que resulta em mau desempenho.
Um grupo de pesquisadores da Universidade Introdutória, o romance de como combinar a necessidade de vários modelos, combinando vários efeitos eficazes. Diferentemente do MOA tradicional, que inclui LLMs diferentes, os benefícios do serviço independente no modelo com uma amostragem repetitiva. Esse método garante que apenas respostas de alta qualidade forneçam saídas finais, para abordar a qualidade da qualidade da qualidade – configuração mista gerenciada.
A auto-moa funciona produzindo muitas respostas de um modelo ativo e inclui trabalhar na última verificação. Isso elimina isso a necessidade de colocar modelos de baixa qualidade, melhorando assim a qualidade de reações extensas. Promover o avanço, os pesquisadores apresentados ao MOA-seq, as variações consecutivas processando muitas respostas com iterativamente. Isso permite uma integração eficaz de resultados, mesmo em crimes em que o processo dos processos é forçado. Os processos auto-Seq usam processos de fluido de janela, para garantir que os problemas de conteúdo curtos ainda sejam capazes de alcançar sem comprometer a operação sem comprometer o desempenho.
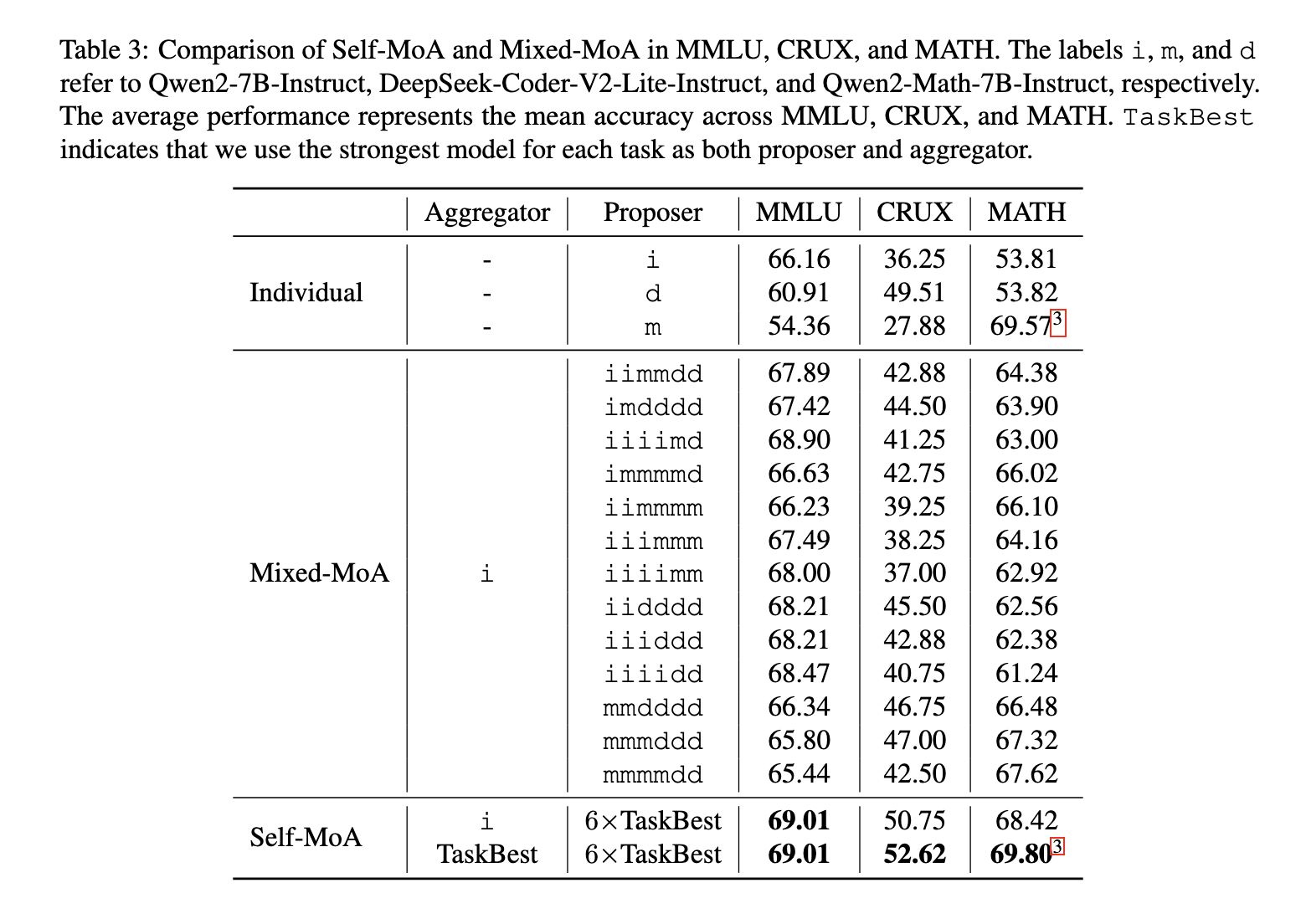
O teste mostrou que o autocontrole – MOA é uma mistura muito diferente em todos os bancos diferentes. Na referência do AlpacaEval 2.0, o treinamento recebeu 6,6% dos desenvolvimentos sobre o MOA tradicional. Quando testado em muitas informações, incluindo MMLU, Crux e Statistics, o auto-MA indicou o desenvolvimento entre 3,8% em relação aos métodos mistos. Quando usado em um dos modelos da mais alta qualidade no Alpacaeeval 2.0, treinando para estabelecer o novo recorde do Novo Mundo, garantindo sua funcionalidade. Além disso, os exercícios MOA-seq foram um sucesso como integrado ao mesmo tempo, considerando as limitações definidas pelos problemas do comprimento do modelo.
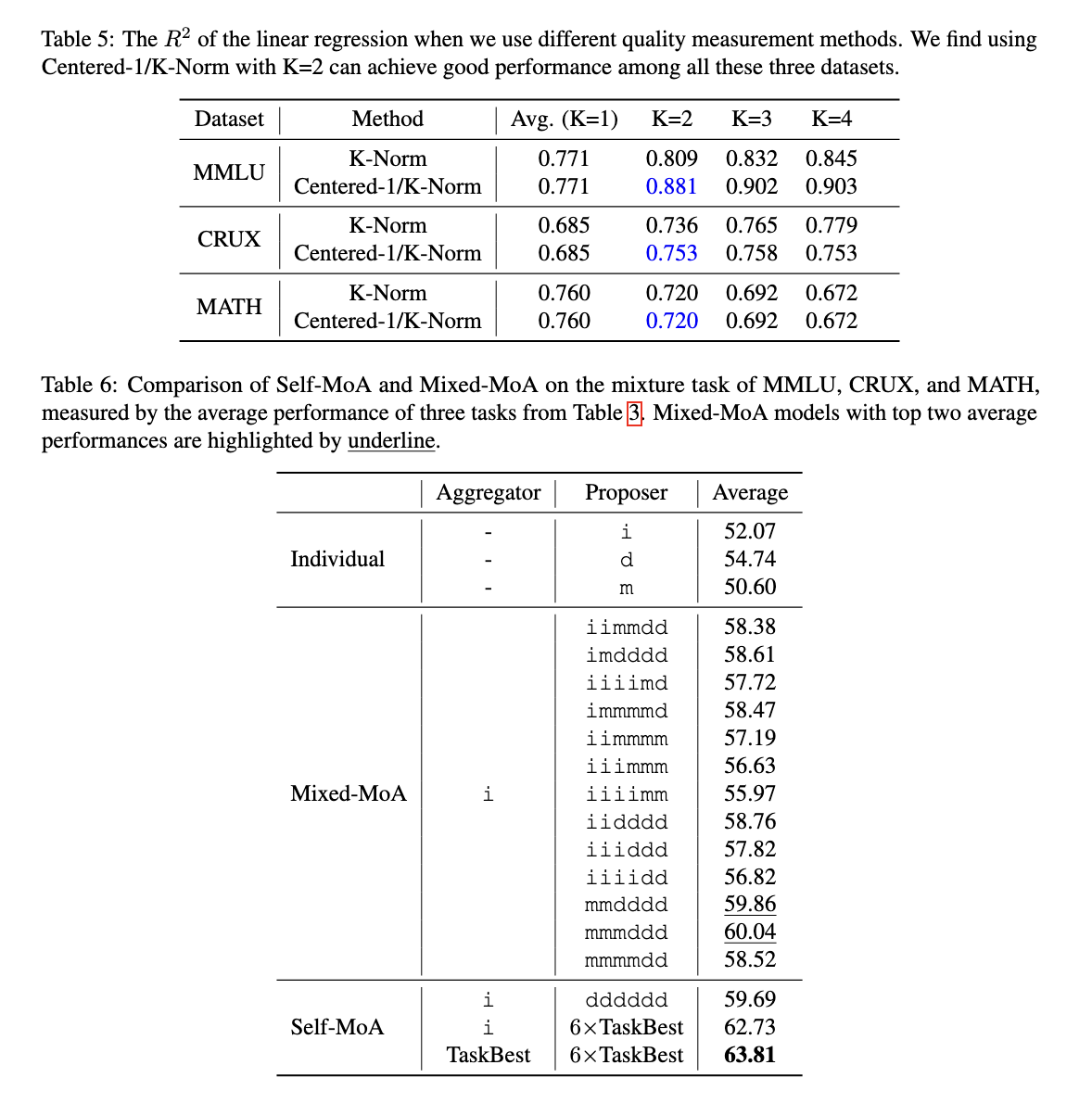
A descoberta da pesquisa enfatiza o importante entendimento do acordo de planejamento do MAA é muito sensível à qualidade da proposta. Os resultados garantem que a inclusão de vários modelos nem sempre esteja levando a alto desempenho. Em vez disso, as respostas em série de um modelo de alta qualidade produz melhores resultados. Os investigadores são realizados mais de 200 ensaios para analisar a negociação entre qualidade e diversidade, concluíram que o MAA se exercita de maneira diferente exclusiva do modelo.
Este estudo desafia o pensamento que se mistura com diferentes LLMs leva a melhores resultados. Ao mostrar a altura da independência, produz uma nova idéia se preparando para a consolidação do LLM. As descobertas indicam que o foco em modelos mais altos, e não nas variáveis aumentadas, podem melhorar o desempenho completo. À medida que o estudo da LLM continua a aparecer, o treinamento MOA fornece uma maneira promissora de maneiras tradicionais, fornece tecnologia de desenvolvimento econômico e eficaz.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Registre a plataforma de IA de código aberto: 'Sistema de código aberto interestagente com muitas fontes para testar o programa difícil' (Atualizado)
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
✅ [Recommended] Junte -se ao nosso canal de telégrafo


