
As funções de adição, envolvendo provas de números sustentáveis, depende tradicionalmente das cabeças do número como parâmeta gaussiano ou tensor de tensores. Essas maneiras tradicionais têm fortes requisitos de distribuição, requerem mais dados instalados e geralmente quebram quando podem seduzir números avançados. Novas pesquisas sobre grandes modelos de idiomas lança diferentes formas – representando números como conflitos de tokens discretos e usando deterioração automática da predeterminação. Essa mudança, no entanto, vem com vários desafios críticos, incluindo o requisito da forma de coisas boas, o direito de perder a precisão limitada, a necessidade de manter o treinamento estável e a necessidade de superar a falta de simplicidade. A superação desses desafios levará a uma estrutura mais poderosa, eficiente e imutável, usando assim o uso de modelos de aprendizado profundo que excedem as formas tradicionais do que as formas tradicionais excedem as formas tradicionais.
Os modelos tradicionais dependem do número de números ou cabeças afrika ham'thitulith, como um modelo gaussiano. Embora essas maneiras comuns estejam cheias, elas também têm vários problemas. Os modelos baseados em Gaussiano têm desvantagem para obter os resultados mais comumente distribuídos, limitando a capacidade de exibir a distribuição mais avançada, multimodais. Chefes de pontos de restauração estão lutando contra relacionamentos não linear ou não compreensivos, o que proíbe seus poderes gerais em diferentes conjuntos de dados. Modelos mais altos têm circunstâncias mais altas, como a distribuição de histograma baseada em histograma e o Data-Broad e, portanto, não estão funcionando. Além disso, muitos métodos indígenas requerem esclarecimentos ou saída claros, adicione uma camada adicional de dificuldade e ungodia. Embora o trabalho geral tenha tentado recrutar o texto em realização usando grandes modelos de idiomas, realizou um pequeno trabalho formal em “qualquer texto do texto” a ser introduzido no novo paradegam dos preços.
Os investigadores do Google DeepMind sugerem outra maneira de reintegração, redirecionando os números como uma ordem cronológica de ordem padrão. Em vez de produzir diretamente os preços do Scalcar, esse método inclui números como sequência de token e usa constipação obrigatória para produzir saída. A instalação dos valores dos valores da seguinte forma o consecutivo do token faz com que essa abordagem seja ajustada ao simbolizar informações em tempo real. Diferentemente dos métodos baseados em Gaussiano, esse método não inclui uma sólida consideração de distribuição sobre dados, tornando-o um fator perfeito nas atividades do mundo real com padrões de heterogenenos. O modelo usa modelos precisos de modelos multimodais, distribuição complexa, desenvolvendo sua operação na estimativa das funções de Dendis e Restauração. Ao instalar os benefícios do AutoReGrone Concher, beneficia o progresso mais recente do idioma, enquanto armazena operações competitivas relacionadas ao número normal. Essa construção produz uma estrutura forte e variável que pode indicar uma variedade de números no número de números, oferece oportunidades ilegais eficazes para a procrastinação comum.
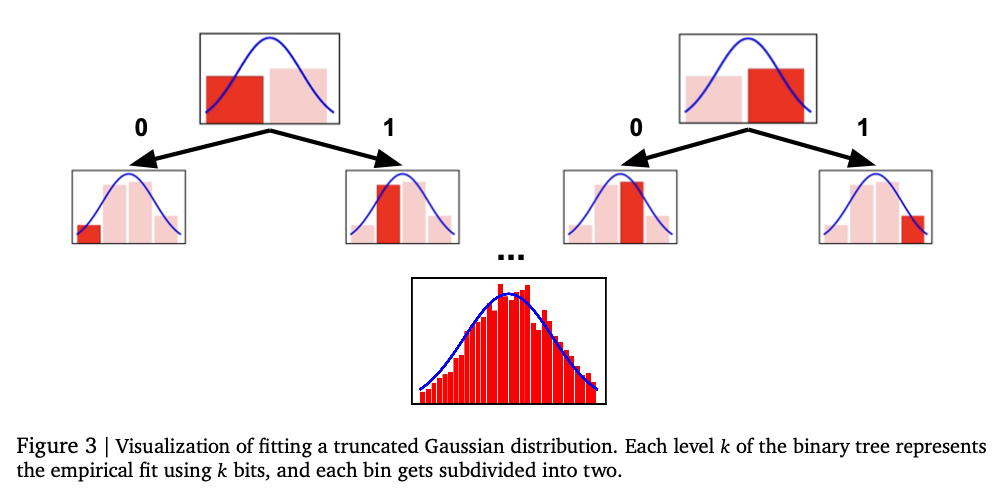
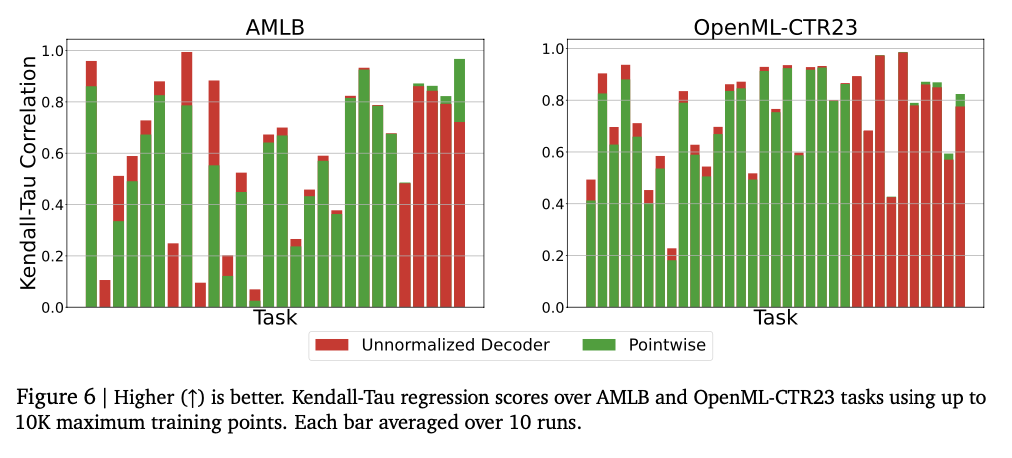
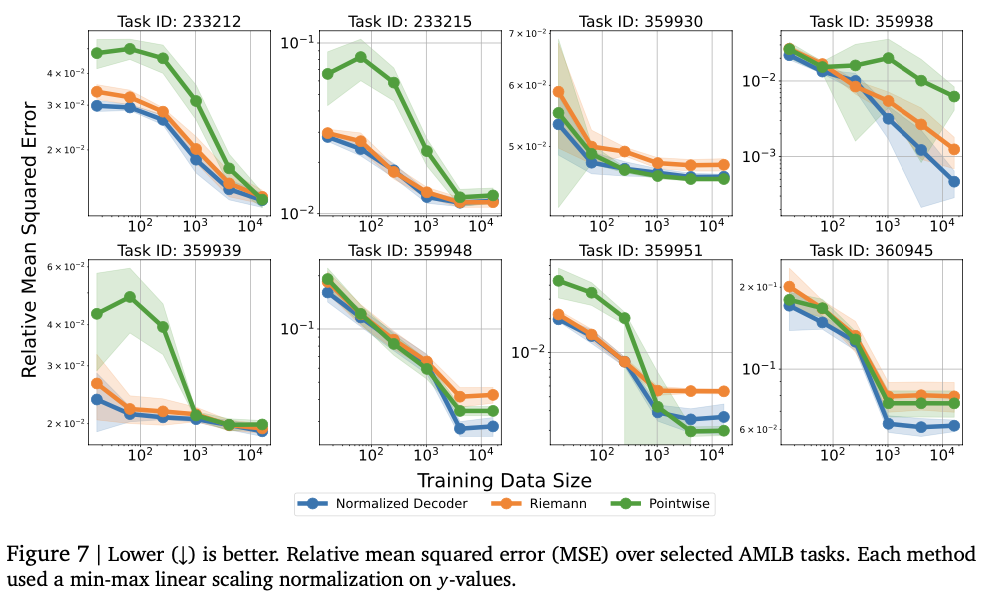
Este método usa dois tipos de números para números: Tokouday Normal e ancestrais únicos. Os números normais de tokenzação incluem números de nível moderado com base B para expandir para fornecer precisão com o comprimento subordinado. A Cothenzation exclusiva transmite a mesma idéia de números extensos com as melhores moedas de IEEEEE-754 sem um requisito de esclarecimento claro. O Modelo Auto-Regressivo do Transformmer produz um token numérico em termos de questões para fornecer sequência válida. O modelo é treinado usando uma perda de entropia cruzada sobre a ordem do token para fornecer uma representação precisa dos números. Em vez de prever diretamente uma disposição escalar, o sistema token do token e usa medições matemáticas, como palavrões ou integração final, previsões finais. A análise é feita no banco de dados de regressão tabular dos benchmarks OpenML-CTR23 e dos benchmarks AMLB e comparado à mistura gaussiana, restauração do histograma e pós-graduadores padrão. O ajuste do hyperparâmetro é feito em todas as várias configurações do decodificador, como variações pelo preço das camadas, unidades ocultas e os nomes da convenção, fornecendo desempenho bem executado.
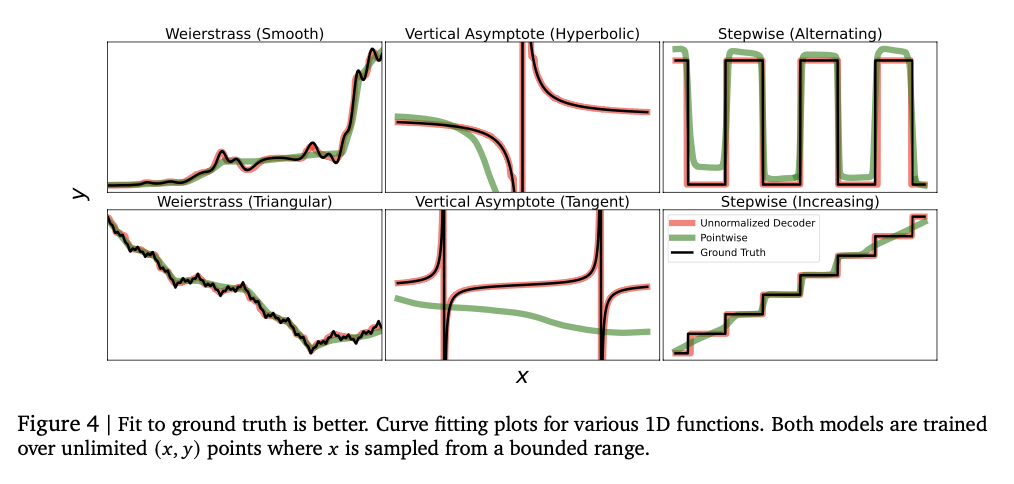
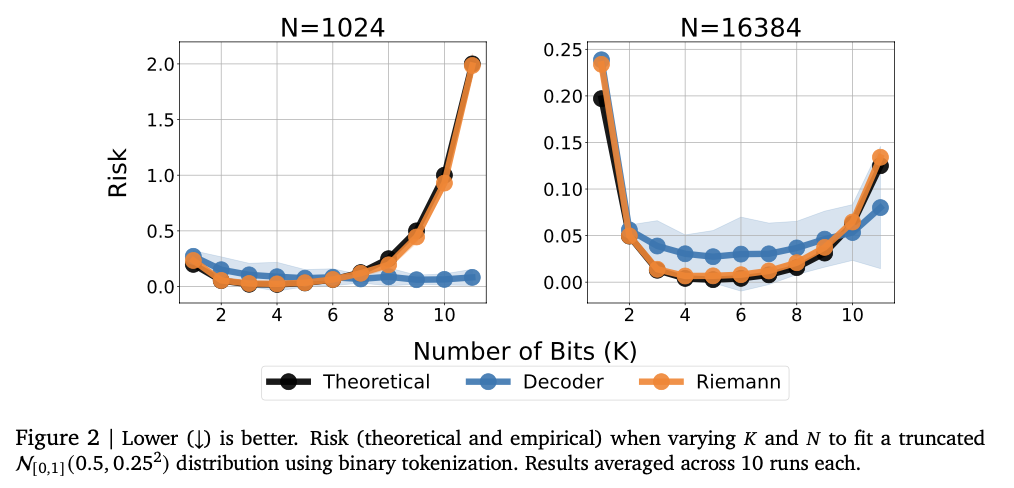
O teste mostra que o modelo inclui com sucesso relacionamentos numéricos complexos, alcançando um forte desempenho em várias atividades de reciclagem. Encontra as pontuações do ensino médio de Kendalall-Tau, geralmente os modelos básicos são altos, especialmente em configurações de dados baixos, onde a intensidade numérica é importante. Essa abordagem também é melhor em dificuldades, capturando com sucesso a distribuição complexa e a mistura da mistura baseada em Gierunn gaussiana em testes de teste desagradáveis. O arranjo do tamanho do modelo melhora originalmente a operação, destacando a causa da superlotação excessiva. A intensidade numérica é altamente desenvolvida reparando erros como reforço e votação, reduzindo o risco para os vendedores. Esses efeitos tornam essa estrutura de uma estrutura de repressão em uma sólida e variável de maneiras tradicionais, reflete seus poderes que efetivamente efetivamente para todas as várias atividades de informação e modelagem.
Este trabalho apresenta o número de romances para os predeterminados com Independent e Padrão engraçado. Ao substituir as cabeças nativas para adiar o fone de ouvido com base no token, a estrutura melhora a variabilidade no fabricante das informações permitidas reais. Ele atinge o desempenho competitivo em vários retornos de retorno, especialmente na dificuldade de medir o tabar, enquanto fornece teoria da sugestão síria. Ele emite maneiras tradicionais de comprometer conflitos significativos, especialmente na série de distribuição complexa e dados escassos. Trabalhos futuros incluem melhores estádios para melhor precisão e fluxos, despesas de saída e previsões mais altas e investiga aplicativos de aprendizado e saldos. Esses resultados usam a restauração de números com base nos outros métodos tradicionais de Registro de Refland, aumentam o número de funções nas quais os modelos de idiomas podem ser efetivamente resolvidos.
Enquete Página e papel do github. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 O Marktechpost está gritando para as empresas / inicialização / grupos cooperarem com as próximas revistas da IA a seguinte 'fonte AI em produção' e 'e' Agentic AI '.
Aswin AK é consultor em Marktechpost. Ele persegue seus dois títulos no Instituto Indiano de Tecnologia, Kharagpur. Você está interessado na leitura científica e científica e de máquinas, que traz uma forte formação e experiências educacionais para resolver os desafios reais de desenvolvimento de fundo.
✅ [Recommended] Junte -se ao nosso canal de telégrafo


