
Os principais modelos de idiomas (LLMs) foram severamente removidos de vários remédios para corrigir o ambientalismo, incluindo interpretação de máquinas, resumo do texto e IA. No entanto, seu crescente stubit e tamanho levaram à eficiência da capacidade e dos desafios de usar a memória. À medida que esses modelos crescem, as necessidades precisam ser difíceis de se mover em áreas com habilidades associadas associadas limitadas.
O principal obstáculo e os LLMs estão em seus grandes processos. Treinamento e recreação Esses modelos incluem bilhões de parâmetros, fazendo -os usar recursos e reduzir seu acesso. Os eventos disponíveis para melhorar a eficiência, como o bom layout do parâmetro (PEFT), fornecem confiabilidade, mas muitas vezes comprometem. O desafio é encontrar a maneira que pode reduzir os requisitos computacionais, enquanto armazena a precisão do modelo e a eficiência das circunstâncias reais do mundo. Os investigadores examinam os métodos que permitem planejamento ativo eficaz sem precisar de grandes recursos do computador.
A Intel Labs e a Intel Corporation apresentaram o caminho que combina baixas estratégias (LORA) com a pesquisa neural da Architecure (NAS). Essa abordagem requer abordar os limites do resgate tradicional enquanto desenvolve eficiência e desempenho. O grupo de pesquisa cria uma estrutura que usa o uso de memória e velocidades computacionais de acordo com a menor submissão. Essa abordagem inclui uma rede de super compartilhamento de contrato de peso que se adequa à capacidade de melhorar o treinamento. Este combinado permite que o modelo seja bem organizado, mantendo a pegada de um pequeno computador.
O método da Intel Labs está focado em lasas (instalações de construção de baixa qualidade), que usam a adaptação elástica de Lora de um belo modelo. Ao contrário das maneiras comuns que exigem edição completa de LLMs completas, os Lones permitem o desempenho selecionado dos itens usados para modelos, reduz o declínio. O estabelecimento básico está na conversão de altos adaptadores, sincronicamente sincronizados nas necessidades do modelo. Este método é suportado pelas pesquisas de rede heuístas que continuam a transmitir um bom processo de ordem. Com foco nos parâmetros apropriados, o processo atinge o equilíbrio entre o computador e as operações operacionais. Esse processo é organizado para permitir o desempenho selecionado para estruturas de baixa qualidade, mantendo a velocidade máxima da infância.
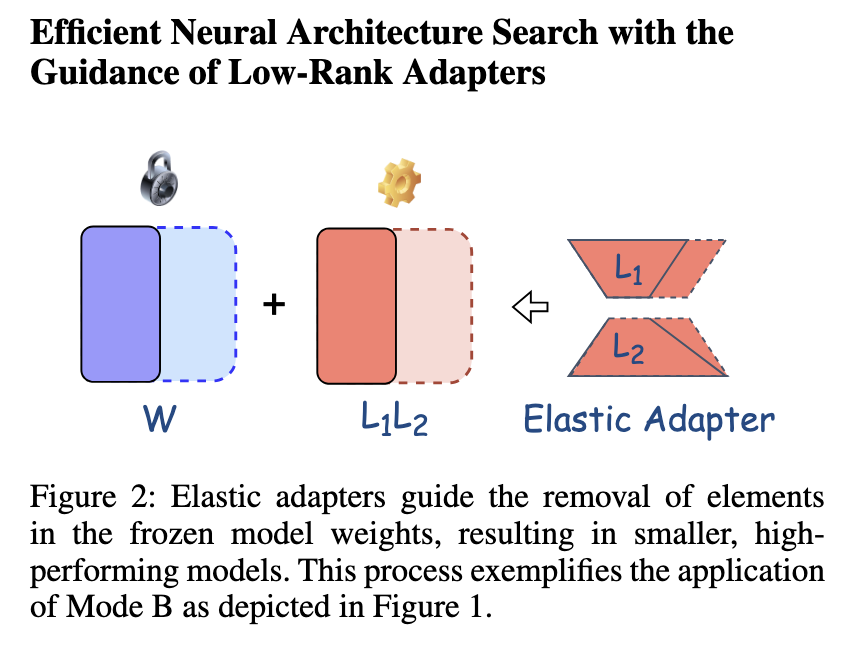
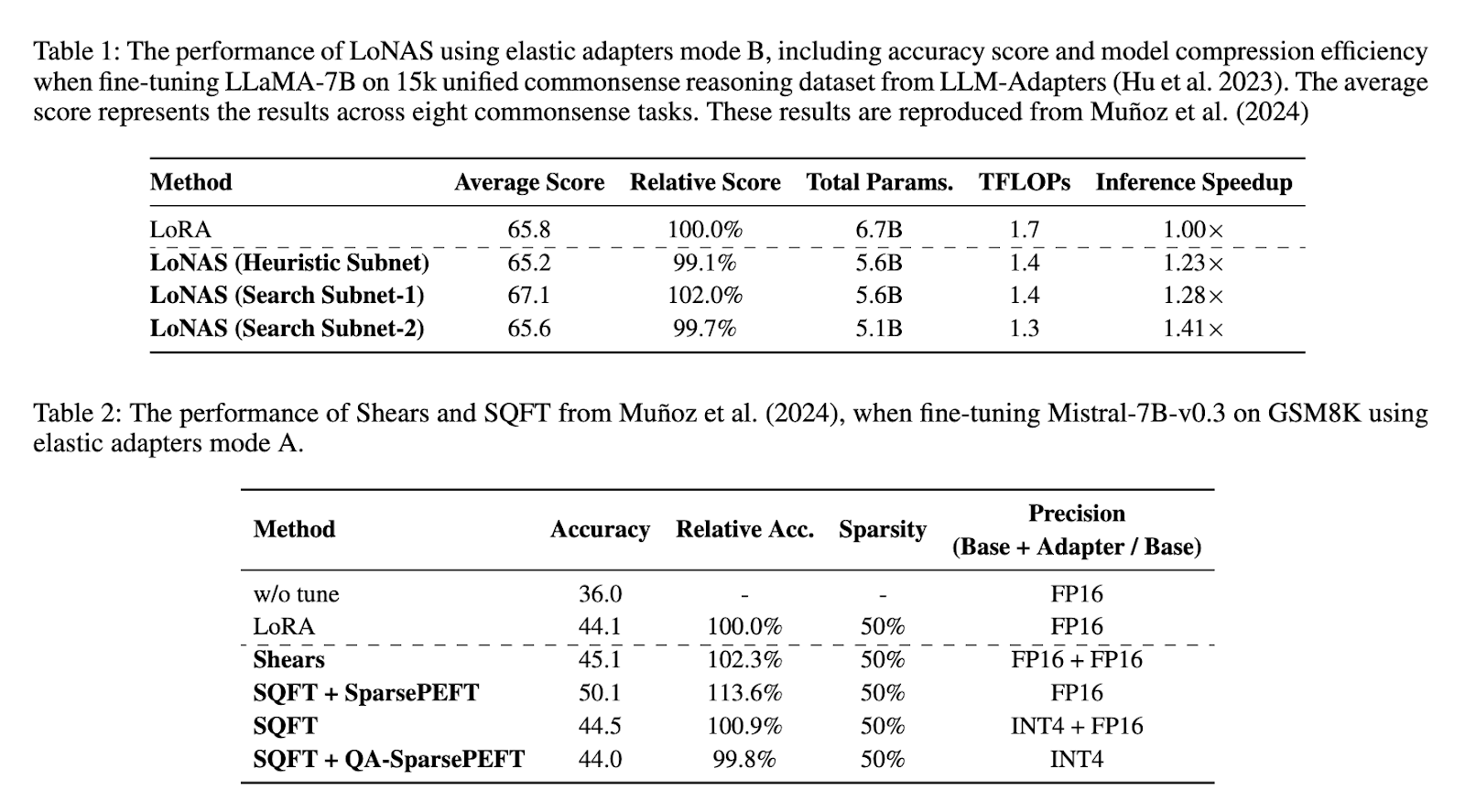
A avaliação funcional da metodologia proposta destaca sua importante melhoria nas estratégias padrão. Os resultados do teste indicam que o LON tem acesso mais rápido a 1,4x, reduzindo os parâmetros do modelo cerca de 80%. Quando usado no LLAMA-7B pronto para o banco de dados 15K 15K 15K, ossos indicaram um número limitado de 65,8%. O acumulativo diferente da lista diferente de Latas indicou que o desempenho da sub -rede heurístico foi obtido pela velocidade de 1,23x, enquanto a suspensão da sub -rede é permitida para 1,28x e 1,41x de velocidade. Além disso, o uso de osso-V0-V0.3 nas atividades GSM8K aumenta a precisão de 44,1% a 50,1%, para manter a eficiência em todos os tamanhos de modelo diferentes. Essas descobertas garantem que a metodologia proposta esteja aumentando muito o desempenho do LLMS enquanto reduz as necessidades do computador.
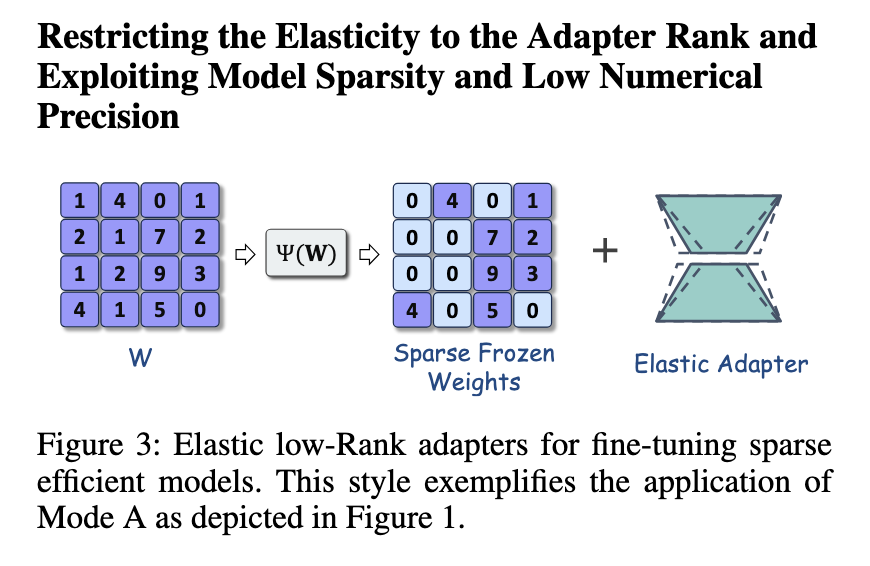
A estrutura excessiva envolve a introdução de Sheers, uma maneira avançada de controle regulatório em sol. A tesoura usa a menor pesquisa neural da opção está funcionando de tempos para o modelo básico usando métricas especificadas, para garantir que o bom planejamento permaneça eficaz. Essa estratégia é especialmente eficaz para manter a precisão do modelo, reduzindo o número de parâmetros ativos. Outra extensão, a SQFT, inclui a escassez e as taxas mais baixas dos preços para melhorar material humorístico. Técnicas de avaliação são usadas, o SQFT confirma que os modelos organizados podem organizar sem perder a eficiência. Essa reflexão destaca os contextos dos solas e sua oportunidade de repetir.
A consolidação Lora Namasa fornece uma mudança para a linguagem prejudicial. Ao arquivar as submissões de base baixa, o estudo mostra que o desempenho computacional pode ser altamente desenvolvido sem comprometer o desempenho. O Intel Labs confirma que a combinação dessas estratégias reduz o ônus da boa ordem e garantiu a integridade do modelo. Pesquisas futuras podem verificar o desempenho adicional, incluindo melhor seleção de rede e as melhores estratégias herusicas. Este método dá um exemplo de facilmente acessível ao LLMS e é usado em diferentes locais, expressando uma maneira bem eficaz da IA.
Enquete Página e papel do github. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 70k + ml subreddit.
🚨 Conheça o trabalho: um código aberto aberto com várias fontes para verificar o programa difícil AI (Atualizado)
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
✅ [Recommended] Junte -se ao nosso canal de telégrafo

")
