 lança Molmo: uma família de modelos de linguagem multimodal de código aberto")
Os modelos multimodais representam um avanço significativo na inteligência artificial, permitindo que os sistemas processem e compreendam dados de múltiplas fontes, como textos e imagens. Esses modelos são importantes para aplicações como legendagem de imagens, resposta a perguntas visuais e assistência a robôs, onde a compreensão da entrada visual e linguística é importante. Com o desenvolvimento de modelos de linguagem visual (VLMs), os sistemas de IA podem gerar narrativas descritivas de imagens, responder perguntas baseadas em informações visuais e realizar tarefas como reconhecimento de objetos. No entanto, muitos dos modelos mais eficazes atualmente são construídos utilizando dados proprietários, o que limita a sua acessibilidade à comunidade científica mais ampla e impede a inovação na investigação em IA de acesso aberto.
Uma das questões críticas enfrentadas pelo desenvolvimento de modelos multimodais abertos é a sua dependência de dados gerados por sistemas proprietários. Sistemas fechados, como GPT-4V e Claude 3.5, criaram dados sintéticos de alta qualidade que ajudam os modelos a alcançar resultados excelentes, mas esses dados não estão disponíveis para todos. Como resultado, os investigadores enfrentam obstáculos quando tentam replicar ou melhorar estes modelos, e a comunidade científica necessita de uma base para construir tais modelos a partir do zero, utilizando conjuntos de dados totalmente abertos. Este problema impediu o progresso da investigação aberta no domínio da IA, uma vez que os investigadores não conseguem aceder aos principais componentes necessários para construir modelos multimodais de alta qualidade de forma independente.
Os métodos comumente usados para treinar modelos multimodais dependem fortemente da destilação de sistemas proprietários. Muitos modelos de percepção de linguagem, por exemplo, utilizam dados como o ShareGPT4V, produzido pelo GPT-4V, para treinar seus sistemas. Embora muito eficientes, estes dados sintéticos mantêm estes modelos dependentes de sistemas fechados. Os modelos de peso aberto são aprimorados, mas geralmente apresentam desempenho pior do que seus equivalentes proprietários. Além disso, estes modelos são dificultados pelo seu acesso limitado a conjuntos de dados de alta qualidade, tornando difícil colmatar a lacuna de desempenho com sistemas fechados. Assim, os modelos abertos são muitas vezes deixados para trás em comparação com modelos mais avançados de empresas que têm acesso a dados proprietários.
Pesquisadores do Allen Institute for AI e da Universidade de Washington apresentam o Molmo uma família de modelos de linguagem conceitual. Esta nova família de modelos representa um avanço no campo, fornecendo uma solução de dados e peso totalmente aberta. Molmo não depende de dados sintéticos de programas proprietários, o que o torna uma ferramenta totalmente acessível para a comunidade de pesquisa em IA. Os pesquisadores criaram um novo conjunto de dados, PixMocontendo legendas de imagens detalhadas feitas inteiramente por anotadores humanos. Este conjunto de dados permite que os modelos Molmo sejam treinados em dados naturais e de alta qualidade, tornando-os competitivos com os melhores modelos da área.
A primeira versão inclui vários componentes principais:
- MolmoE-1B: Ele foi desenvolvido usando a combinação de código aberto OLMoE-1B-7B de especialistas em modelos de linguagem grande (LLM).
- Molmo-7B-O: Ele usa o OLMo-7B-1024 LLM de código totalmente aberto, com lançamento previsto para o início de outubro de 2024, com lançamento público completo planejado para mais tarde.
- Molmo-7B-D: Este modelo de demonstração usa um Qwen2 7B LLM de peso aberto.
- Molmo-72B: Modelo mais eficiente da família, utiliza o Openweight Qwen2 72B LLM.
Os modelos Molmo são treinados usando um pipeline simples, mas poderoso, que combina um codificador de visão pré-treinado com um modelo de linguagem. O codificador de visão é baseado no modelo ViT-L/14 CLIP da OpenAI, que fornece tokens de imagem confiáveis. O conjunto de dados PixMo da Molmo, que contém mais de 712.000 imagens e quase 1,3 milhão de legendas, é a base para modelos de treinamento para criar descrições de imagens densas e detalhadas. Ao contrário dos métodos anteriores que solicitavam aos anotadores que escrevessem legendas, o conjunto de dados PixMo depende de descrições faladas. Os anotadores foram instruídos a descrever todos os detalhes da imagem em 60 a 90 segundos. Esta abordagem inovadora permitiu a coleta de dados mais detalhados em menos tempo e proporcionou anotações de imagens de alta qualidade, evitando a dependência de dados artificiais de VLMs fechados.
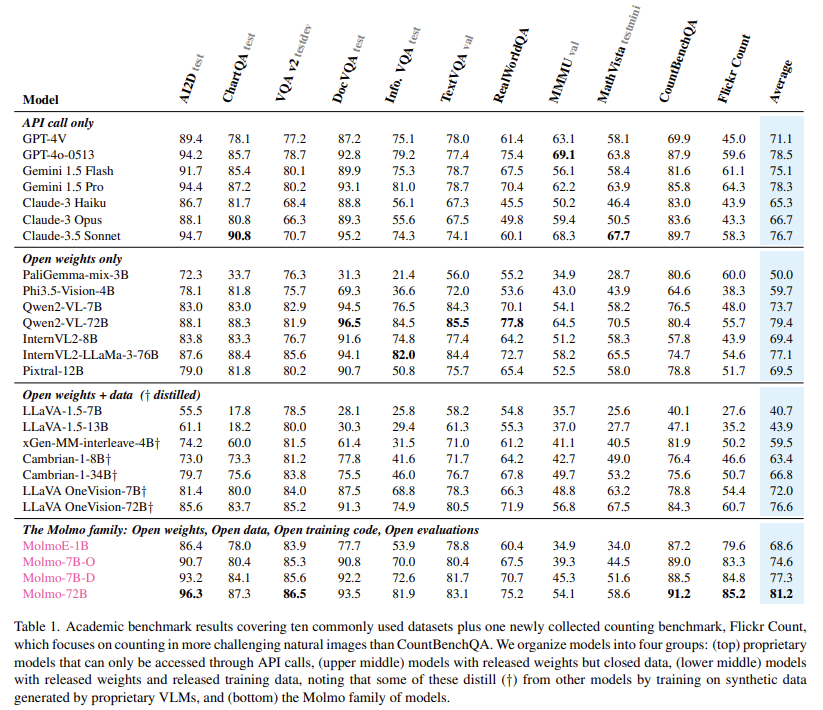
O modelo Molmo-72B, o mais avançado da família, superou vários sistemas proprietários líderes, incluindo Gemini 1.5 e Claude 3.5 Sonnet, em 11 benchmarks acadêmicos. Ele também ficou em segundo lugar em testes em humanos, com 15.000 pares imagem-texto, atrás apenas do GPT-4o. O modelo obteve alta pontuação em benchmarks como o AndroidControl, onde alcançou 88,7% de precisão para tarefas de baixo nível e 69,0% para tarefas de alto nível. O modelo MolmoE-1B, outro da família, conseguiu se aproximar do desempenho do GPT-4V, tornando-o um modelo de peso aberto muito eficiente e competitivo. O amplo sucesso dos modelos Molmo em testes acadêmicos e de usuários demonstra o potencial do VLM aberto para competir e até mesmo superar sistemas proprietários.
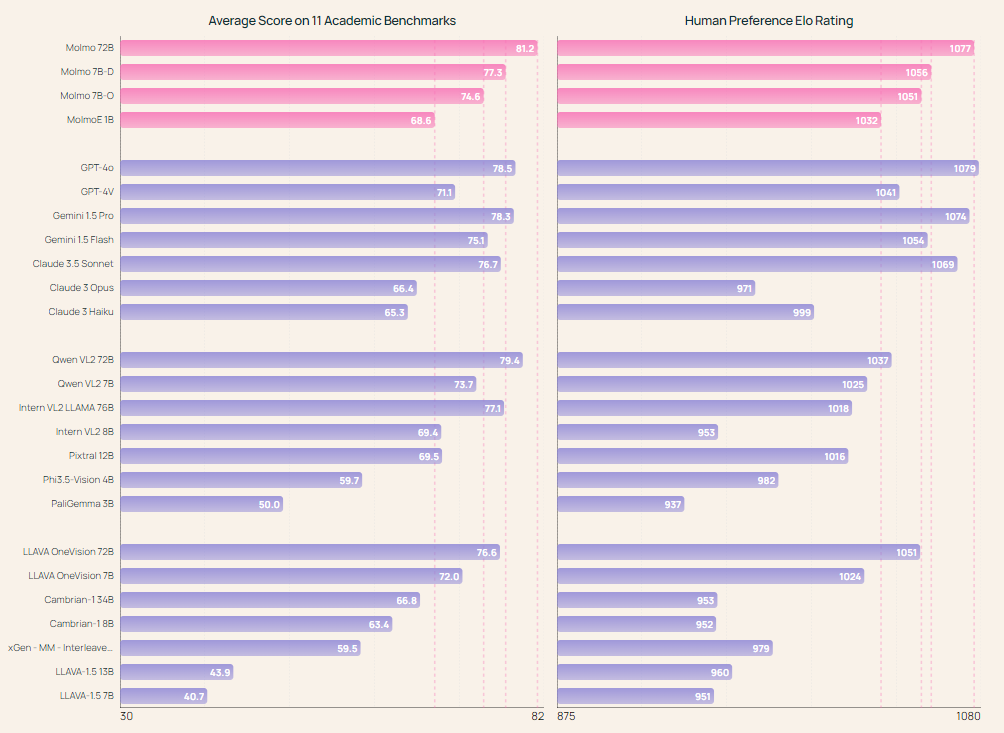

Concluindo, o desenvolvimento da família Molmo fornece à comunidade de pesquisa uma alternativa poderosa e aberta aos sistemas fechados, oferecendo pesos, conjuntos de dados e código-fonte totalmente abertos. Ao introduzir novas técnicas de coleta de dados e otimizar a arquitetura do modelo, os pesquisadores do Allen Institute for AI criaram com sucesso uma família de modelos que funcionam no mesmo nível e, em alguns casos, superam os gigantes da área. O lançamento destes modelos, juntamente com os conjuntos de dados PixMo associados, abre caminho para a inovação e colaboração no desenvolvimento de modelos de linguagem visual, garantindo que a comunidade científica mais ampla tenha as ferramentas necessárias para continuar a ultrapassar os limites da IA.
Confira Modelos na página HF, Demonstraçãode novo Detalhes. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso SubReddit de 52k + ML
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.


