 de código aberto projetada para alinhamento estrutural de elementos visuais e de texto incorporados")
A inteligência artificial (IA) está mudando rapidamente, especialmente na aprendizagem multimodal. Os modelos multimodais visam integrar informações visuais e escritas para que as máquinas possam compreender e gerar conteúdo que requer informações de ambas as fontes. Essa capacidade é importante para tarefas como legendagem de imagens, resposta a perguntas visuais e criação de conteúdo, onde mais de um modo de dados é necessário. Embora muitos modelos tenham sido desenvolvidos para enfrentar estes desafios, apenas alguns conseguiram alinhar com sucesso as diferentes representações de dados visuais e textuais, resultando em ineficiências e desempenho limitado em aplicações do mundo real.
Um grande desafio na aprendizagem multimodal vem da forma como os dados de texto e imagem são escritos e representados. Os dados textuais geralmente são definidos usando embeddings de uma tabela de pesquisa, o que garante um formato estruturado e consistente. Em contraste, os dados visuais são codificados usando transformadores ópticos, que produzem incorporações aleatórias contínuas. Essa diversidade na representação torna mais fácil para os modelos multivariados existentes combinarem facilmente dados visuais e textuais. Por causa disso, os modelos lutam para interpretar relações complexas entre elementos visuais e texto, limitando seu poder a aplicações avançadas de IA que exigem compreensão coerente em vários fluxos de dados.
Tradicionalmente, os pesquisadores têm tentado mitigar esse problema usando um linker, como um perceptron multicamadas (MLP), para incorporar embeddings visuais em um espaço que pode ser alinhado com embeddings textuais. Embora funcione bem para tarefas multimodais gerais, esta estrutura deve resolver o importante mal-entendido entre a incorporação visual e textual. Modelos líderes como LLaVA e Mini-Gemini incorporam técnicas avançadas, como processos de atenção cruzada e codificadores de visão dupla para melhorar o desempenho. No entanto, ainda enfrentam limitações devido a diferenças inerentes nos tokens e nas técnicas de incorporação, destacando a necessidade de uma nova abordagem que aborde estas questões a um nível estrutural.
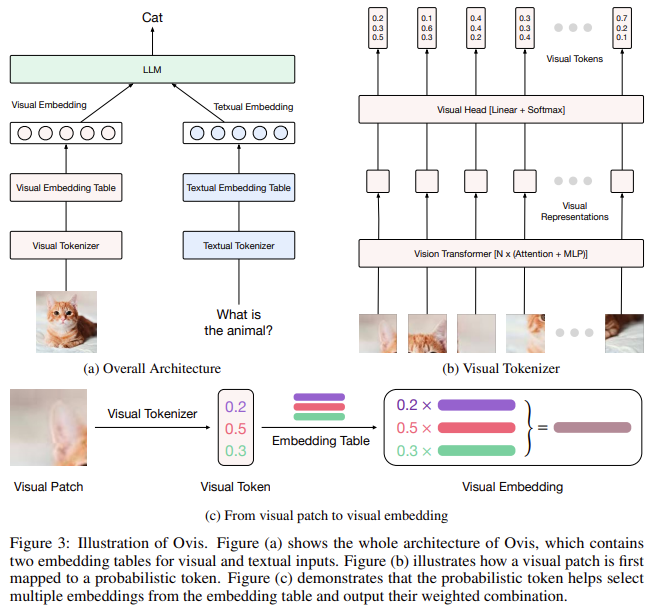
Uma equipe de pesquisadores do Grupo Alibaba e da Universidade de Nanjing apresentou uma nova versão do Ovis: Ovis 1.6 é um novo modelo de linguagem multimodal multimodal (MLLM) que alinha estruturalmente incorporações visuais e textuais para enfrentar esse desafio. Ovis usa uma tabela de pesquisa incorporada exclusiva, semelhante àquela usada para incorporação de texto, para criar representações visuais estruturadas. Esta tabela permite que o codificador visual gere embeddings compatíveis com embeddings textuais, resultando em integração eficiente de informações visuais e textuais. O modelo reutiliza os tokens de probabilidade de patches virtuais mapeados para a tabela de incorporação virtual várias vezes. Esta abordagem mostra uma representação estruturada aplicada a dados textuais, o que facilita uma combinação coerente de elementos visuais e textuais.
A inovação da Ovis reside no uso de uma tabela de incorporação visual que alinha os tokens visuais com suas contrapartes textuais. Um possível token representa cada patch de imagem e faz referência à tabela de incorporação virtual várias vezes para gerar a incorporação virtual final. Este processo captura a semântica rica de cada fragmento visual e resulta em incorporações, como tokens de texto. Em contraste com os métodos convencionais, que dependem de projeções lineares para mapear incorporações visuais em um espaço conjunto, Ovis usa uma abordagem probabilística para gerar incorporações visuais significativas. Esta abordagem permite à Ovis superar as limitações das arquiteturas baseadas em conectores e obter melhor desempenho em operações multimodais.
Testes poderosos do Ovis mostram sua superioridade sobre outros MLLMs de código aberto de tamanhos semelhantes. Por exemplo, no benchmark MathVista-Mini, a Ovis obteve uma pontuação de 1.808, significativamente superior à dos seus concorrentes. Da mesma forma, no benchmark RealWorldQA, a Ovis superou os principais modelos proprietários, como o GPT4V e o Qwen-VL-Plus, pontuando 2.230, em comparação com o 2038 do GPT4V. Esses resultados destacam a capacidade da Ovis de lidar com tarefas multimodais complexas, tornando-o um candidato promissor para desenvolvimento futuro. campo. Os pesquisadores também testaram o Ovis em uma série de benchmarks multimodais padrão, incluindo MMBench e MMStar, onde superou consistentemente modelos como Mini-Gemini-HD e Qwen-VL-Chat por uma margem de 7,8% a 14,1%, dependendo do específico. referência. .

Principais conclusões do estudo:
- Alinhamento Estrutural: Ovis apresenta uma nova tabela de incorporação visual que alinha estruturalmente as incorporações visuais e textuais, melhorando a capacidade do modelo de processar dados multimodais.
- Alto desempenho: Ovis supera modelos de código aberto de tamanhos semelhantes em vários benchmarks, alcançando uma melhoria de 14,1% em relação às arquiteturas baseadas em conectores.
- Habilidades de alta resolução: O modelo se destaca em tarefas que exigem percepção visual de imagens de alta resolução, como o benchmark RealWorldQA, onde obteve pontuação de 2.230, superando o GPT4V em 192 pontos.
- Escalabilidade: Ovis mostra desempenho consistente em todas as faixas de parâmetros (7B, 14B), tornando-o compatível com vários tamanhos de modelos e recursos computacionais.
- Aplicações aplicáveis: Com seus recursos multimodais avançados, o Ovis pode ser usado em situações complexas e desafiadoras do mundo real, incluindo a resposta a consultas visuais e legendas de imagens, onde os modelos existentes têm dificuldades.
Concluindo, os pesquisadores abordaram com sucesso o antigo mal-entendido entre a incorporação visual e textual. Ao introduzir uma estratégia de incorporação visual estruturada, a Ovis permite uma integração de dados multimodal altamente eficaz, melhorando o desempenho em uma variedade de tarefas. A capacidade do modelo de superar modelos proprietários e de código aberto para escalas de parâmetros semelhantes, como Qwen-VL-Max, sublinha seu potencial como um novo padrão em aprendizagem multimétodos. A abordagem da equipe de pesquisa fornece um passo importante no desenvolvimento de MLLMs, fornecendo novos caminhos para futuras pesquisas e aplicações.
Confira Papel, GitHubde novo Modelo de alta frequência. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso SubReddit de 52k + ML.
Convidamos startups, empresas e institutos de pesquisa que trabalham em modelos de microlinguagem para participar deste próximo projeto Revista/Relatório 'Modelos de Linguagem Pequena' Marketchpost.com. Esta revista/relatório será lançada no final de outubro/início de novembro de 2024. Clique aqui para agendar uma chamada!
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.


