
Grandes modelos de linguagem (LLMS) se desenvolveram além do processo de linguagem básica para lidar com problemas com problemas. Embora o tamanho do modelo, os dados e a computação permitissem o desenvolvimento de sugestões e habilidades internas avançadas aparecem em grandes modelos, os desafios importantes residem em seu respectivo poder. As maneiras atuais que se esforçam para manter a unidade em todos os problemas de solução, especialmente nos princípios que exigem pensamento planejado. Existem dificuldades em fazer bem em pensar em cadeia de tempos e garantir um desempenho consistente em vários empregos, especialmente para desafiar questões matemáticas. Embora o progresso recente tenha sido demonstrado, os pesquisadores enfrentam o desafio contínuo do bom uso de recursos computacionais para melhorar as habilidades de autodisciplina. Melhorar os sistemas que podem melhorar formalmente os problemas de resolução, enquanto a preservação da escalabilidade continua sendo um grande problema no desenvolvimento de habilidades da LLM.
Os investigadores testaram vários métodos para melhorar a consulta sobre o LLMS. A dedução do período do estudo investiga que os modelos estão inclinados a roubar ou reduzir, avaliar as etapas, inserção e falhas padrão. O trabalho passado se concentra na construção de pensamentos estatísticos sobre claridade e imaginação durante a fase de aprendizado e sua análise durante a aprovação. Embora esses métodos mostrem melhorias nos bancos, as perguntas ainda continuam a funcionar com o modelo de poder internacional e as relações entre consulta e funcional. Essas questões são importantes para entender a maneira de compor os sistemas mais eficazes.
Este estudo usa o conjunto de dados omni-math em um banco de pensamento que reflete diferentes variações de modelos. Esses dados fornecem uma estrutura de alívio difícil nas Olimpíadas, abordando as restrições dos benchmarks existentes, como GSM8K e estatísticas, onde os LLMs recebem o preço mais alto. Omni-Math encontrado em 33 domínios em todos os 10 níveis difíceis, permitindo um exame de compreensão das habilidades matemáticas. O Omni-Juil Access ajuda a análise padrão das respostas produzidas de maneira preparada. Enquanto outros bancos, consulta e GPQAs mostram diferentes origens e bancos de código destacam a importância dos modelos de recompensa clara, a estrutura da Omni-Math nos torna muito prontos para analisar a relação entre a capacidade de consultar.
Este estudo avaliou o funcionamento do modelo usando a referência omnon-math, que inclui 4.428 problemas matemáticos no nível da Olimpíada Seis domésticos e quatro tigres pesados. Os resultados mostram administradores claros entre os modelos pesquisados: o GPT-4O recebeu 20 a 30% de precisão em várias linhas, está muito cheio de modelos. O1-mini chegou a 40-60%; O3-mini (M) alcançou pelo menos 50% de todas as seções; e O3-mini (H) desenvolveu cerca de 4% acima de O3-mini (M), mais de 80% da álgebra e cálculo. A análise da Telekkela revelou que o uso de token relacionado está aumentando com dificuldades de problemas em todos os modelos, e as estatísticas insatisfiadas têm grande tamanho. Importante, o O3-mini (M) não usa mais consultas que o O1-Mini para obter alto desempenho, aumentando o pensamento eficaz. Also, accuracy declines for all models, and the powerful effect of O1-mini (3.16% decrease in 1000 tokens) and reduce the O3-mini (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (h). Isso mostra que, embora o O3-mini (H) seja um melhor desempenho de linhas, tem alto custo de computação.
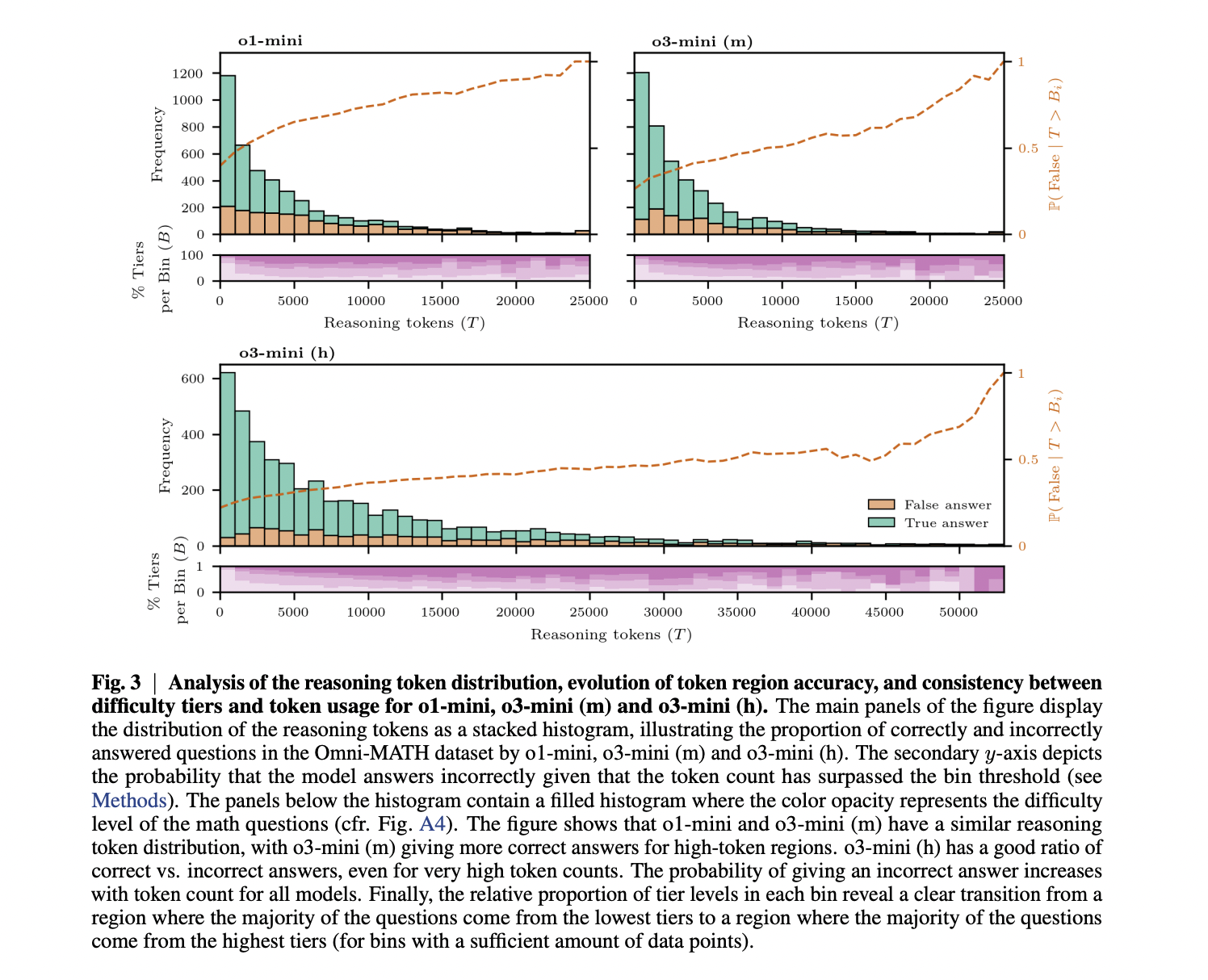
Estudos mostram mais descobertas sobre consultoria em modelos de linguagem. Primeiro, os modelos qualificados não exigem necessariamente cadeias de longo prazo para obter alta precisão, como mostrado em comparação entre O1-mini e O3-mini (M). Segundo, enquanto a precisão está diminuindo em processos de cadeias de tigras de longa data reduzem os modelos avançados, enfatizando que “pensamento difícil” é diferente “para o pensamento de mente longa. Essa diminuição líder é possível porque os modelos estão inclinados a pensar nos problemas que eles se esforçam para resolver para resolver, ou porque mostrando oportunidades que aumentam a energia. Os achados têm os efeitos ativos do modelo, sugerindo que o comprimento estressante é significativamente benéfico para os modelos de pensamento fraco, em vez de mais fortes, pois eventualmente mantém uma precisão razoável, mesmo com adultério. Trabalhos futuros podem se beneficiar dos metais das estatísticas matemáticas para continuar testando essas dinâmicas.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, fique à vontade para segui -lo Sane E não se esqueça de se juntar ao nosso 80k + ml subreddit.
🚨 Pesquisa recomendada recomendada para nexo
Asjad é o consultor de estudo na região de Marktechpost. Ele convida o B.Tech em Meshher Engineering para o Instituto Indiano de Tecnologia, Kharagpur. Mecanismo de leitura de Asjad e leituras profundas do aluno que continua fazendo pesquisas para aplicações de aprendizado de máquinas nos cuidados de saúde.
🚨 Plataforma de IA de código aberto recomendado: 'Interestagente Sistema de código aberto com várias fontes para testar o sistema de IA difícil (promovido)


: melhorando a precisão e a personalização com técnicas de aprendizado profundo")