
Grandes Modelos de Linguagem (LLMs) baseados em transformadores enfrentam grandes desafios no processamento eficiente de sequências longas devido à complexidade quadrática do mecanismo de atenção. Isso aumentará drasticamente suas demandas computacionais e de memória com o comprimento da sequência, portanto, escalar esses modelos para aplicações práticas, como resumo de vários textos, raciocínio baseado em recuperação ou até mesmo análise de código bem analisado no nível do repositório, parece impossível. Os métodos atuais não conseguem lidar com sequências que se estendem a milhões de tokens sem computação massiva ou perda de precisão, o que cria um grande obstáculo ao seu uso bem-sucedido em vários casos de uso.
Diferentes estratégias têm sido propostas para lidar com esta ineficiência. Os vieses de atenção são projetados para reduzir o esforço computacional, mas muitas vezes não conseguem preservar as dependências globais mais importantes, levando a uma diminuição no desempenho da tarefa. Métodos para melhorar a eficiência da memória, como compactação de cache de chaves e escalonamento de baixo nível, reduzem o uso de recursos em detrimento da escalabilidade e da precisão. Sistemas distribuídos como Ring Attention melhoram a escalabilidade distribuindo estatísticas entre vários dispositivos. No entanto, estes métodos requerem comunicação significativa e, portanto, reduzem a sua eficácia em sequências muito longas. Tais limitações apontam para uma necessidade urgente de uma nova abordagem que possa medir a eficiência, a escala e a precisão.
Pesquisadores da NVIDIA apresentaram Star Attention, uma nova forma de atenção projetada para enfrentar esses desafios. Na verdade, o Star Attention divide a sequência de entrada em blocos menores, precedidos pelo que os pesquisadores chamam de “bloco âncora”, que armazena muitas informações ao redor do mundo. Em seguida, ele bloqueia o processamento de forma independente em vários hosts para reduzir drasticamente a complexidade computacional com a capacidade de capturar padrões globais. Os processos de inferência combinam os pontos de atenção de cada bloco usando um algoritmo softmax distribuído que permite uma atenção global eficiente enquanto minimiza a transmissão de dados. A integração do modelo com estruturas anteriores baseadas em Transformer não causa interrupções e a otimização não é obrigatória, tornando-a uma solução viável para gerenciar sequências longas em aplicações do mundo real. A base técnica do Star Attention é o processo de classificação. Na primeira etapa, codificação de contexto, cada bloco de entrada é complementado com um bloco âncora que garante que o modelo capture padrões de atenção globais. Após o processamento, os caches de valores-chave dos blocos percorridos são descartados para economizar memória. Na segunda etapa, codificação de consulta e geração de token, os pontos de atenção são calculados localmente para cada host e combinados com um softmax distribuído, permitindo que o modelo mantenha a eficiência computacional e a escalabilidade.
A atenção da estrela foi avaliada com benchmarks como o RULER, que combina tarefas de recuperação e raciocínio, e BABILong, que testa o raciocínio contextual de longo prazo. Para sequências com mais de 16.000 a 1 milhão de tokens, os modelos testados – Llama-3.1-8B e Llama-3.1-70B – são testados, usando HuggingFace Transformers e GPU A100, que aproveita a velocidade bfloat16 mais alta.
Star Attention oferece melhorias significativas em velocidade e precisão. Ele atinge uma execução até 11 vezes mais rápida em comparação com a linha de base, mantendo uma precisão de 95 a 100% em todas as tarefas. No benchmark RULER, ele brilha em tarefas de recuperação, mas sua precisão cai apenas 1-3% em situações de raciocínio mais complexas. O benchmark BABILong concentra-se em testar suposições em cenários longos, e os resultados estão sempre na faixa de 0-3% em comparação com a linha de base. Ele também pode crescer até 1 milhão de tokens, tornando-o um candidato robusto e flexível que se adapta bem a aplicações que dependem fortemente de sequenciamento.

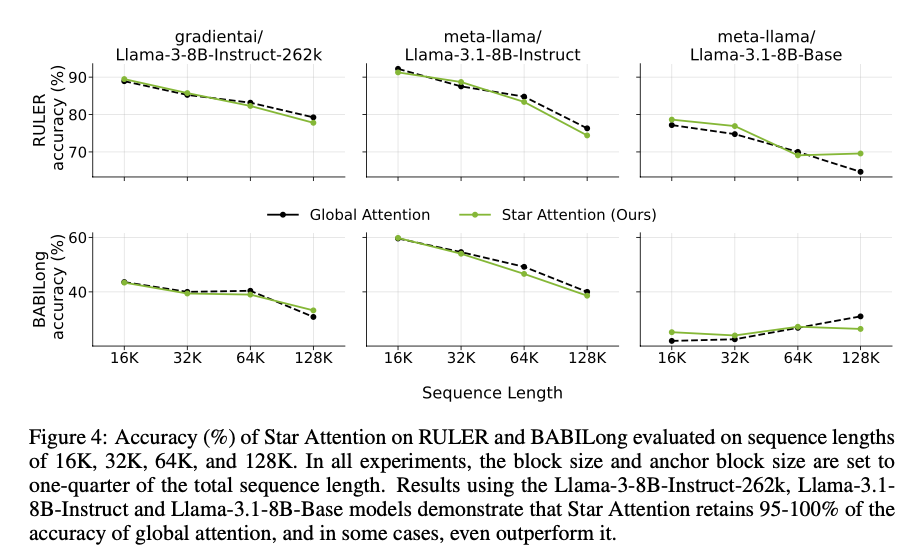
Star Attention estabelece uma estrutura transformadora para expressão funcional em LLMs baseados em Transformer, abordando as principais limitações no processamento de sequências longas. Algumas atenções e blocos de ancoragem afetam o equilíbrio certo entre eficiência e precisão computacional, permitindo aceleração com economias significativas de desempenho. Este avanço traz soluções simples e práticas para uma ampla gama de aplicações de IA: inferência, recuperação e resumo. O trabalho futuro incluirá refinamentos de design para fortalecer os mecanismos e melhorar o desempenho dos gargalos nas comunicações baseadas em bloco a bloco.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


