
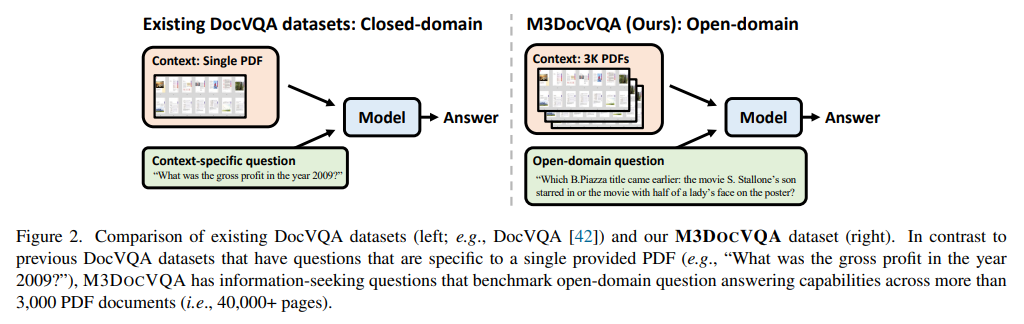
Document Visual Question Answering (DocVQA) representa um campo em rápido desenvolvimento que visa melhorar a capacidade da IA de interpretar, analisar e responder perguntas com base em documentos complexos que incluem texto, imagens, tabelas e outros elementos visuais. Esta habilidade é cada vez mais importante em ambientes financeiros, de saúde e jurídicos, pois pode reverter e apoiar processos de tomada de decisão que dependem da compreensão de informações densas e detalhadas. Os métodos tradicionais de processamento de documentos, no entanto, muitas vezes precisam ser adaptados a estes tipos de documentos, destacando a necessidade de sistemas complexos e multidimensionais que possam interpretar informações espalhadas por diferentes páginas e em diferentes formatos.
Um grande desafio no DocVQA é recuperar e traduzir com precisão informações que abrangem várias páginas ou documentos. Os modelos convencionais tendem a se concentrar em documentos de uma única página ou a extrair texto simples, o que pode ignorar informações visuais confidenciais, como imagens, gráficos e estruturas complexas. Tais limitações dificultam a capacidade da IA de compreender completamente os documentos em situações do mundo real, onde informações importantes são frequentemente incorporadas em vários formatos em várias páginas. Essas limitações exigem técnicas avançadas que combinem efetivamente dados visuais e textuais em diversas páginas de um documento.
Os métodos DocVQA existentes incluem resposta visual de consulta (VQA) de uma página e sistemas de geração aumentada de recuperação (RAG) que usam reconhecimento óptico de caracteres (OCR) para extrair e traduzir texto. No entanto, estes métodos ainda não estão totalmente equipados para lidar com as necessidades multimodais de compreensão de textos detalhados. Os pipelines RAG baseados em texto, embora eficazes, muitas vezes não conseguem capturar nuances visuais, o que pode levar a respostas incompletas. Esta lacuna no desempenho destaca a necessidade de desenvolver uma abordagem multimodal que possa processar documentos grandes sem sacrificar a precisão ou a velocidade.
Pesquisadores da UNC Chapel Hill e Bloomberg apresentaram M3DocRAGuma estrutura básica projetada para aproveitar o poder da IA para tornar as consultas em nível de documento responsivas em configurações multimodais, de várias páginas e de vários documentos. Esta estrutura inclui um sistema RAG multimodal que integra efetivamente texto e elementos visuais, permitindo compreensão intuitiva e resposta a perguntas em uma variedade de tipos de texto. O design do M3DocRAG permitirá que ele funcione bem tanto em condições abertas quanto fechadas, tornando-o adaptável a todos os campos e múltiplas aplicações.
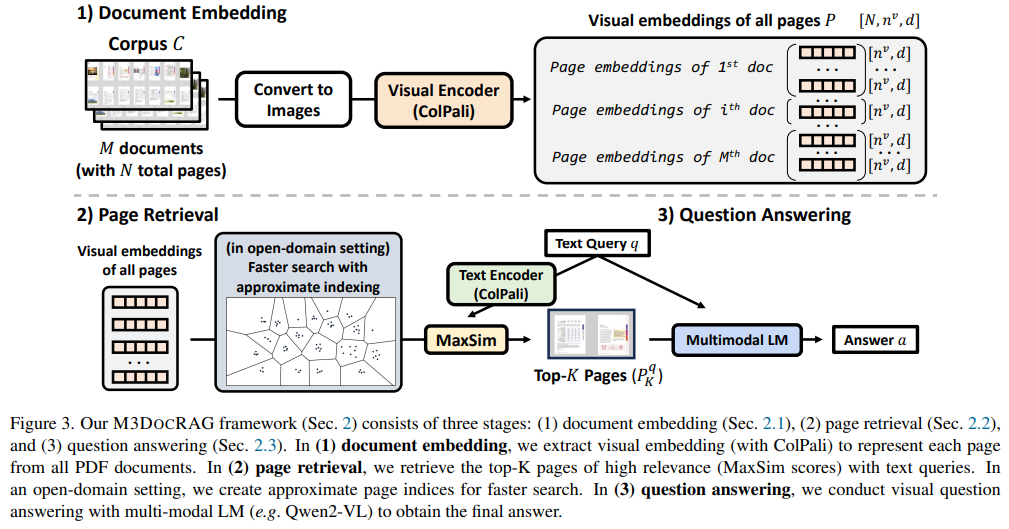
A estrutura M3DocRAG opera em três fases principais. Primeiro, ele converte todas as páginas do documento em imagens e utiliza incorporação visual para combinar os dados da página, garantindo que as características visuais e textuais sejam preservadas. Em segundo lugar, utiliza modelos de recuperação multivariada para identificar as páginas mais relevantes do corpus documental, utilizando métodos avançados de indexação para melhorar a velocidade e a relevância da pesquisa. Finalmente, um modelo de linguagem multimodal processa essas páginas retornadas para gerar respostas precisas às consultas dos usuários. A incorporação visual garante que informações importantes sejam retidas em várias páginas, abordando as principais limitações dos sistemas RAG somente de texto. M3DocRAG pode funcionar em grandes conjuntos de documentos, lidando com até 40.000 páginas espalhadas por 3.368 documentos PDF com latência de recuperação reduzida para menos de 2 segundos por consulta, dependendo do método de indexação.
Os resultados dos testes técnicos mostram o forte desempenho do M3DocRAG em três importantes benchmarks DocVQA: M3D OC VQA, MMLongBench-Doc e MP-DocVQA. Esses benchmarks simulam desafios do mundo real, como raciocínio de várias páginas e resposta a consultas de código aberto. M3DocRAG obteve uma pontuação de 36,5% F1 no M3D OC VQA de código aberto e desempenho de última geração no MP-DocVQA, que requer uma única resposta de pergunta. A capacidade do sistema de encontrar respostas com precisão em todas as formas de evidência (texto, tabelas, imagens) apoia o seu forte desempenho. A flexibilidade do M3DocRAG se estende ao tratamento de situações complexas onde as respostas dependem de evidências de várias páginas ou de conteúdo não textual.
As principais conclusões deste estudo destacam as vantagens do sistema M3DocRAG sobre os métodos existentes em diversas áreas principais:
- Eficiência: M3DocRAG reduz a latência de recuperação para menos de 2 segundos por consulta para grandes conjuntos de documentos usando indexação otimizada, permitindo tempos de resposta mais rápidos.
- Precisão: O sistema mantém alta precisão em vários formatos e comprimentos de documentos, combinando recuperação multiespécies e modelagem de linguagem, alcançando altos resultados em benchmarks como M3D OC VQA e MP-DocVQA.
- Escalabilidade: M3DocRAG gerencia com sucesso a resposta de código aberto para grandes conjuntos de dados, lidando com até 3.368 documentos ou mais de 40.000 páginas, estabelecendo uma nova referência em DocVQA.
- Interoperabilidade: Este sistema integra várias configurações de documentos em um domínio fechado (um documento) ou em um domínio aberto (múltiplos documentos) e recebe com sucesso respostas a todos os tipos de evidências diferentes.

Concluindo, o M3DocRAG destaca-se como uma nova solução na área de DocVQA, desenhada para superar as limitações comuns dos modelos de reconhecimento de documentos. Ele traz a capacidade de multimodal, de várias páginas e de vários documentos para responder a perguntas com base em IA, melhorando o campo ao apoiar a recuperação eficiente e precisa em situações complexas de documentos. Ao combinar recursos textuais e visuais, o M3DocRAG preenche uma lacuna crítica na compreensão de documentos, fornecendo uma solução escalável e flexível que pode impactar muitos campos onde a análise de documentos é crítica. Este trabalho incentiva experimentos futuros em recuperação e geração multimétodos, estabelecendo uma referência para aplicações DocVQA robustas, escaláveis e do mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[AI Magazine/Report] Leia nosso último relatório sobre 'MODELOS DE TERRENO PEQUENOS'
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


