
A inteligência artificial (IA) está a mudar a forma como a investigação científica é feita, especialmente com modelos de linguagem que ajudam os investigadores a processar e analisar grandes quantidades de informação. Na IA, modelos linguísticos de grande escala (LLMs) são amplamente utilizados em tarefas como recuperação de literatura, resumo e detecção de conflitos. Essas ferramentas são projetadas para acelerar a velocidade da pesquisa e permitir que os cientistas se envolvam profundamente com a literatura científica complexa sem examinar manualmente todas as informações.
Um dos principais desafios da pesquisa científica hoje é navegar pelo vasto volume de trabalhos publicados. À medida que mais pesquisas são conduzidas e publicadas, os pesquisadores precisam de ajuda para identificar informações relevantes, verificar a precisão de suas descobertas e encontrar inconsistências na literatura. Estas tarefas são demoradas e muitas vezes requerem conhecimento especializado. Embora tenham sido introduzidas ferramentas de IA para ajudar em algumas destas tarefas, muitas vezes requerem a precisão e a fiabilidade de um estudo científico rigoroso. Por conseguinte, é necessária uma solução para colmatar esta lacuna e apoiar eficazmente os investigadores.
Atualmente diversas ferramentas são utilizadas para auxiliar pesquisadores na revisão de literatura e síntese de dados, mas apresentam limitações. Os sistemas de geração aumentada de recuperação (RAG) são o método mais amplamente utilizado neste espaço. Esses programas extraem os documentos relevantes e criam resumos com base nas informações fornecidas. No entanto, muitas vezes têm dificuldade em lidar com toda a literatura científica e podem não conseguir fornecer respostas precisas e detalhadas. Além disso, muitas ferramentas concentram-se na recuperação em nível abstrato, o que não fornece as informações profundas necessárias para questões científicas complexas. Estas limitações impedem todo o potencial da IA na investigação científica.
Pesquisadores da FutureHouse Inc., uma empresa de pesquisa com sede em São Francisco, da Universidade de Rochester e do Instituto Francis Crick introduziram uma nova ferramenta chamada PaperQA2. Este agente de modelagem de linguagem foi desenvolvido para melhorar a validade e eficiência da pesquisa de literatura científica. O PaperQA2 foi projetado para se destacar em três tarefas específicas: recuperação de literatura, resumo de artigos científicos e descoberta de contradições entre estudos publicados. Usando um benchmark rigoroso chamado LitQA2, a ferramenta foi otimizada para funcionar no nível humano ou acima dele, especialmente em áreas onde os sistemas de IA existentes falham.
A metodologia por trás do PaperQA2 envolve um processo de várias etapas que melhora significativamente a precisão e a profundidade das informações obtidas. Começa com a ferramenta “Paper Search”, que transforma a consulta do usuário em uma busca por palavras-chave para encontrar artigos científicos relevantes. Os documentos são então divididos em pedaços menores e legíveis por máquina usando um algoritmo avançado de análise de documentos conhecido como Grobid. Esses fragmentos são calculados com base na correlação usando uma ferramenta chamada “Coletar Evidências”. O sistema então usa uma etapa avançada de “Recuperação e Sumarização de Conteúdo” (RCS) para garantir que apenas as informações mais relevantes sejam retidas para análise. Ao contrário dos sistemas RAG tradicionais, o processo RCS do PaperQA2 converte o texto retornado em resumos claros que são usados posteriormente na fase de geração de resposta. Este método melhora a exatidão e precisão do modelo, permitindo-lhe lidar com questões científicas complexas. A ferramenta “Citation Traversal” permite que o modelo rastreie e inclua fontes relevantes, melhorando sua recuperação de literatura e desempenho de análise.
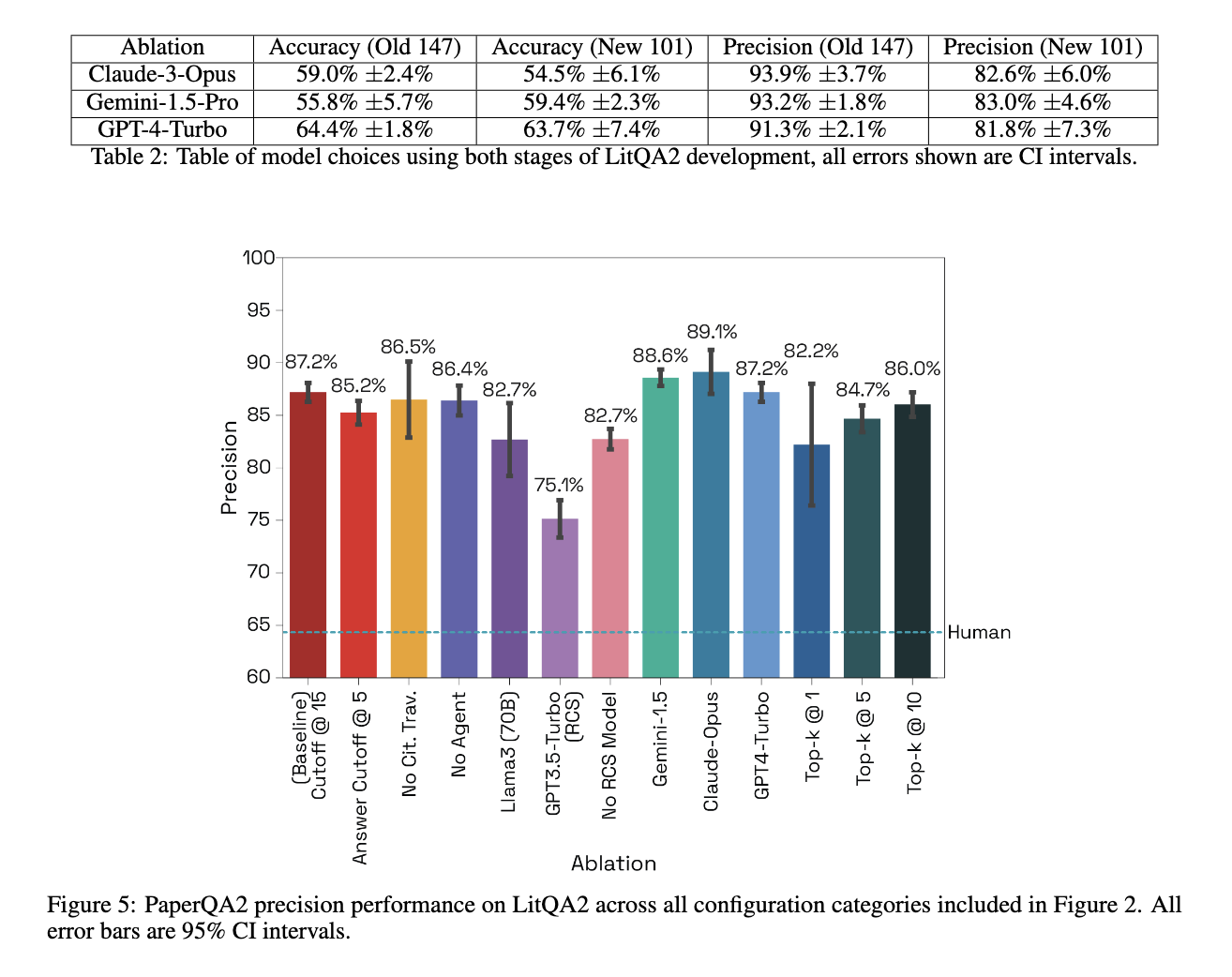
Em termos de desempenho, o PaperQA2 apresentou resultados impressionantes em uma ampla gama de tarefas. Em testes abrangentes usando LitQA2, a ferramenta alcançou uma taxa de precisão de 85,2% e uma taxa de precisão de 66%. Além disso, o PaperQA2 foi capaz de detectar contradições em artigos científicos, identificando uma média de 2,34 contradições por artigo de biologia. Também classificou uma média de 14,5 artigos por consulta durante suas atividades de busca bibliográfica. Outro resultado notável do estudo é a capacidade da ferramenta de identificar contradições com precisão de 70%, confirmada por especialistas humanos. Em comparação com o desempenho humano, o PaperQA2 excedeu a precisão dos especialistas em tarefas de recuperação, demonstrando a sua capacidade de lidar com grandes revisões de literatura de forma mais eficaz do que os métodos convencionais baseados em humanos.
A capacidade da ferramenta de produzir resumos que superam os artigos da Wikipédia de autoria humana com precisão factual é outra conquista importante. O PaperQA2 foi usado para resumir artigos científicos, e os resumos resultantes foram classificados como mais precisos do que o conteúdo existente gerado por humanos. A capacidade avançada do modelo para escrever resumos de citações com base em uma variedade de publicações científicas destaca o seu potencial para apoiar futuros esforços de investigação de uma forma mais confiável. Além disso, o PaperQA2 pode realizar todas essas tarefas em uma fração do tempo e do custo dos pesquisadores humanos, demonstrando os benefícios significativos de economia de tempo da integração de tais ferramentas de IA no processo de pesquisa.
Concluindo, o PaperQA2 representa um grande passo em frente na utilização da IA para apoiar a investigação científica. Esta ferramenta fornece aos pesquisadores uma maneira poderosa de navegar no crescente corpo de conhecimento científico, abordando os principais desafios de recuperação de literatura, resumo e descoberta de contradições. Desenvolvido pela FutureHouse Inc., em colaboração com instituições académicas, o PaperQA2 demonstra que a IA pode superar o desempenho humano em tarefas críticas de investigação, fornecendo uma solução escalável e altamente eficiente para o futuro da descoberta científica. O desempenho do sistema em resumir e encontrar contradições mostra-se muito promissor para expandir o papel da IA na investigação, o que poderá mudar a forma como os cientistas interagem com dados complexos nos próximos anos.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima.
📨 Se você gosta do nosso trabalho, vai gostar do nosso Boletim informativo..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
👨💻 HyperAgent: agentes genéricos de engenharia de software para resolver tarefas de codificação em escala.

 usando um modelo de linguagem pura sem adaptadores externos")
