
A integração do Knowledge Graph (KG) beneficia a pesquisa de inteligência artificial porque pode criar representações de conhecimento estruturadas a partir de dados textuais extensos e não estruturados. Esses gráficos estruturados têm aplicações importantes em áreas que exigem recuperação e raciocínio de informações, como resposta a consultas, resumo complexo de dados e geração avançada de recuperação (RAG). Os KGs conectam e organizam informações, permitindo que os modelos processem e respondam questões complexas com mais precisão. Apesar destas vantagens, a criação de KGs de alta qualidade a partir de grandes conjuntos de dados continua a ser um desafio devido à necessidade de inclusão e eficiência, que se tornam mais difíceis de manter com métodos tradicionais ao lidar com grandes quantidades de dados.
Um dos principais problemas na integração do KG é reduzir ineficiências na produção de gráficos completos, principalmente em grandes empresas que necessitam de apresentações complexas de informações. As técnicas existentes de extração de KG normalmente usam modelos linguísticos de grande escala (LLMs) que são capazes de processamento avançado, mas também podem ser computacionalmente proibitivos. Esses métodos geralmente usam métodos baseados em zero shot ou poucos disparos para construir KGs, que geralmente envolvem extensas chamadas de API e altos custos. Esses métodos precisam ser atualizados para lidar com documentos totalmente longos, levando a problemas como representação incompleta de dados e perda significativa de informações. Isto cria uma lacuna entre a necessidade crescente de métodos eficientes de integração de dados e as ferramentas de construção de KG disponíveis, que requerem mais experiência para avaliação e medição de KG livres de ontologias.
Na prática atual, os métodos tradicionais de construção de KG dependem fortemente do LLM, que incentiva a aquisição de conhecimentos triplos. Este estudo de conteúdo de etapa única apresenta diversas limitações. Por exemplo, a demanda computacional aumenta à medida que o corpus cresce, e cada chamada adicional de API para processar os dados aumenta o custo. Além disso, é necessário haver um conjunto de dados comum ou uma métrica de avaliação para avaliar a qualidade dos documentos, KGs que não possuem uma ontologia, criando desafios adicionais para os pesquisadores que pretendem medir a eficácia dos seus modelos. Com aplicações em larga escala em mente, há uma necessidade urgente de modelos que possam lidar com o processamento de documentos detalhados de forma eficiente, sem comprometer a qualidade dos dados.
Pesquisadores da Salesforce e Intel Labs apresentaram SynthKGfluxo de trabalho de construção de KG em várias etapas para melhorar a cobertura e a eficiência. SynthKG divide o processamento de documentos em segmentos gerenciáveis, garantindo que as informações permaneçam intactas, agrupando documentos e processando cada segmento para identificar associações, relacionamentos e proposições relevantes. Modelo destilado, Distill-SynthKGtambém foi melhorado com o ajuste fino de um pequeno LLM usando KGs gerados a partir do SynthKG. Essa destilação reduz o fluxo de trabalho de várias etapas a uma única etapa, reduzindo bastante os requisitos computacionais. Com o Distill-SynthKG, a necessidade de dados LLM repetidos é reduzida, permitindo a geração de KG de alta qualidade com uma fração dos recursos exigidos pelos métodos convencionais.
O fluxo de trabalho SynthKG envolve segmentação de documentos, que divide cada documento de entrada em partes independentes e matematicamente completas. Durante este processo de agregação, a segmentação de entidade é usada para manter uma referência consistente a cada entidade entre segmentos. Por exemplo, se uma pessoa for apresentada pelo seu nome completo de uma só vez, todas as menções futuras serão revisadas para garantir a precisão do conteúdo. Esta abordagem melhora a integração de cada componente, ao mesmo tempo que evita a perda de relacionamentos importantes entre negócios. A próxima fase envolve a extração relacional, onde as entidades e seus tipos são identificados e vinculados com base em tópicos previamente definidos. Cada componente KG é desenvolvido em formato quádruplo, fornecendo uma unidade central identificável para melhor precisão de recuperação. Ao programar cada componente de forma independente, o SynthKG evita redundância e mantém a integridade dos dados de alta qualidade durante todo o processo de construção do KG.
Distill-SynthKG mostrou uma melhoria significativa em relação aos modelos básicos nas configurações de teste. Por exemplo, o modelo produziu uma cobertura melhor de 46,9% no MuSiQue e 58,2% no 2WikiMultiHopQA em termos de cobertura tripla, superando os modelos maiores por uma margem de até 6,26% em termos absolutos nos vários conjuntos de dados de teste. Para tarefas de recuperação e resposta a consultas, o Distill-SynthKG supera consistentemente modelos maiores em oito vezes, reduzindo o custo computacional e melhorando a precisão da recuperação. Essa eficiência é evidente no localizador Graph+LLM, onde o modelo KG mostrou uma melhoria geral de 15,2% no desempenho de recuperação, especialmente ao responder a consultas de raciocínio multi-hop. Estes resultados confirmam a eficácia da abordagem sistemática em múltiplas etapas no aumento da cobertura KG e na melhoria da precisão sem depender de LLMs muito grandes.
Os resultados experimentais destacam o sucesso do Distill-SynthKG no fornecimento de síntese KG de alto desempenho com baixa demanda computacional. Ao treinar pequenos modelos em pares de documentos KG de alta qualidade do SynthKG, os pesquisadores alcançaram maior precisão semântica, resultando em uma densidade relativa triplicada em documentos de comprimentos variados. Além disso, o modelo SynthKG produziu KGs com alta densidade de trigêmeos, que permaneceram estáveis em documentos de até 1.200 palavras, indicando a robustez do fluxo de trabalho. Testado em todos os benchmarks, como MuSiQue e HotpotQA, a melhoria do modelo foi verificada usando as novas métricas de cobertura KG, que incluem cobertura tripla de proxy e pontuações de similaridade semântica. Essas métricas também confirmaram a adequação do modelo para tarefas KG grandes e livres de ontologias, pois integrou com sucesso KGs detalhados que suportam recuperação de alta qualidade e tarefas de resposta a consultas multi-hop.
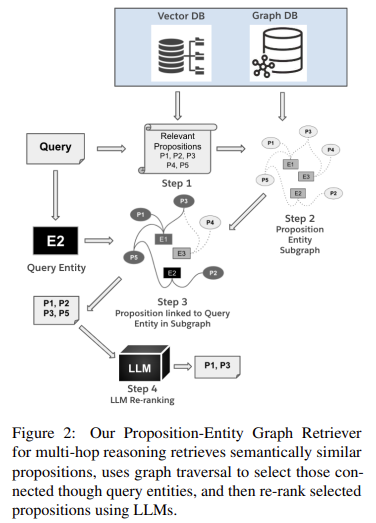
Principais conclusões do estudo:
- Eficiência: O Distill-SynthKG reduz a necessidade de chamadas LLM repetidas, consolidando a construção do KG em um modelo de uma etapa, reduzindo custos computacionais.
- Instalação avançada: Alcançou uma cobertura tripla de 46,9% no MuSiQue e 58,2% no 2WikiMultiHopQA, tornando os modelos 6,26% maiores em média em todos os conjuntos de dados.
- Precisão de recuperação aprimorada: Melhoria de 15,2% na precisão da recuperação de consultas multi-hop com detecção Graph+LLM.
- Escalabilidade: Uma densidade constante de três foi mantida para todos os documentos de vários comprimentos, indicando adequação para grandes conjuntos de dados.
- Amplas aplicações: O modelo suporta a geração eficiente de KG para vários domínios, desde saúde até finanças, incorporando com precisão KGs livres de ontologias.

Concluindo, os resultados do estudo enfatizam o impacto de um processo de implementação de KG bem projetado que prioriza cobertura, precisão e eficiência computacional. Distill-SynthKG não apenas estabelece uma nova referência para a geração KG, mas também apresenta uma solução inovadora que permite uma variedade de domínios, permitindo estruturas de recuperação e consulta altamente eficientes. Esta abordagem poderá ter implicações de longo alcance para melhorar a capacidade da IA de gerar e organizar representações de conhecimento em escala, melhorando, em última análise, a qualidade das aplicações baseadas no conhecimento em todos os domínios.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


