
Os modelos de recuperação de informação (IR) enfrentam grandes desafios na entrega de experiências de pesquisa transparentes e intuitivas. Os métodos atuais dependem principalmente de um único resultado de similaridade semântica para combinar consultas e passagens, levando a uma experiência de usuário fortemente ambígua. Esse método geralmente exige que os usuários se envolvam em um processo complexo de localização de palavras-chave específicas, apliquem vários filtros em configurações de pesquisa avançada e refinem iterativamente suas consultas com base em resultados de pesquisa anteriores. A necessidade de os usuários fazerem a consulta “certa” para encontrar os versículos que desejam destaca as limitações dos sistemas de RI existentes no fornecimento de recursos de pesquisa eficazes e fáceis de usar.
Avanços recentes nos modelos de RI introduziram o uso de instrução, indo além do treinamento denso de retiros para se concentrar em tarefas de correspondência, como correspondência em nível de frase. Os primeiros esforços, como TART e Instructor, incluíam iniciadores de tarefas simples durante o treinamento. Modelos mais recentes, como E5-Mistral, GritLM e NV-Retriever, expandiram essa abordagem aumentando o tamanho do conjunto de dados e do modelo. Estes novos modelos geralmente aceitam as instruções do E5-Mistral. No entanto, embora estes desenvolvimentos representem um progresso neste campo, ainda dependem fortemente de um único conjunto de instruções e não abordam totalmente os desafios de fornecer aos utilizadores uma experiência de pesquisa mais transparente e flexível.
Pesquisadores da Universidade Johns Hopkins e Samaya AI introduziram o Prompttriever, um método exclusivo de recuperação de informações que permite o controle usando informações em linguagem natural. Este modelo permite que os usuários ajustem dinamicamente os critérios de compatibilidade usando definições de diálogo, eliminando a necessidade de múltiplas pesquisas ou filtros complexos. Por exemplo, ao pesquisar filmes de James Cameron, os usuários podem simplesmente especificar critérios como “Documentos elegíveis não dirigidos e criados antes de 2022”. O Prompttriever é construído em uma arquitetura de recuperação de dois codificadores, usando grandes modelos de linguagem, como LLaMA-2 7B, como núcleo. Embora os modelos de linguagem pré-treinados possam se adaptar ao ensino de linguagem natural, o treinamento tradicional de RI muitas vezes compromete essa capacidade, concentrando-se apenas na melhoria da pontuação de similaridade semântica da consulta. O Promptriever resolve essa limitação, mantendo a capacidade de seguir instruções após IR.
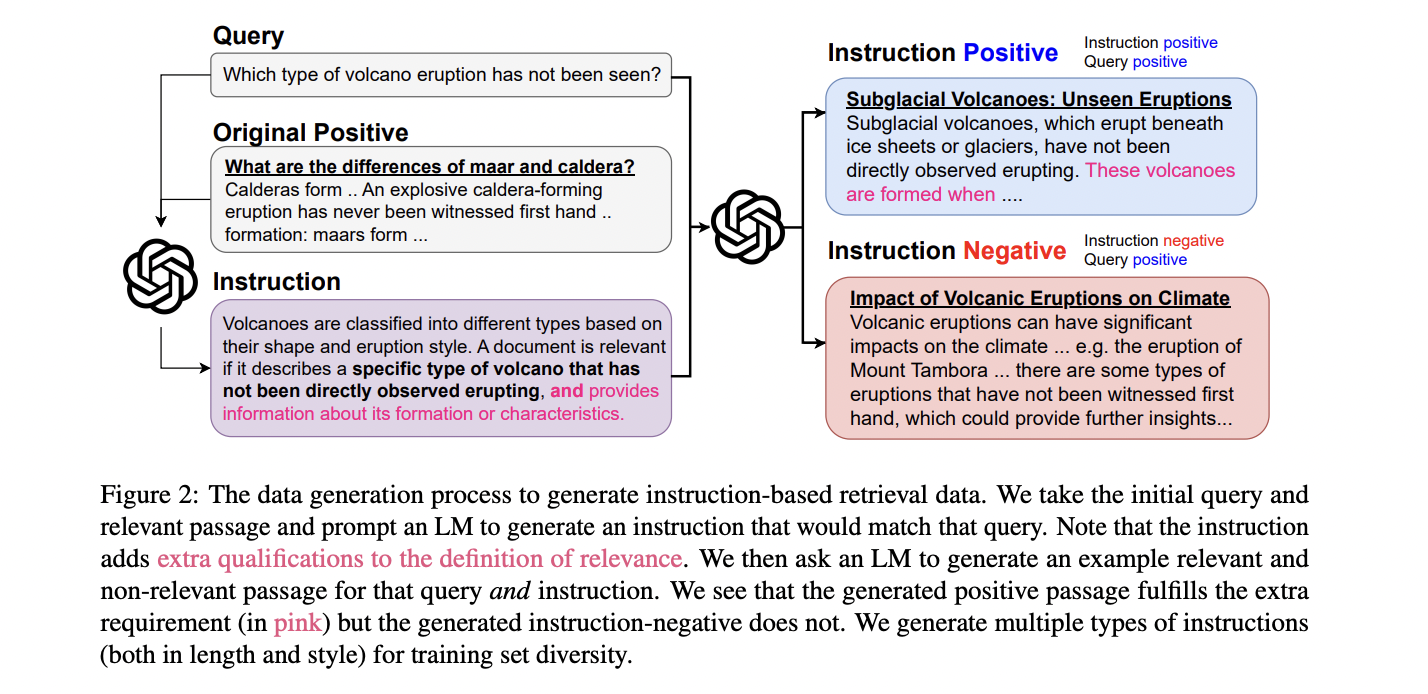
Prompttriever usa um processo de geração de dados em duas partes para treinar seu codificador binário para recuperação baseada em comando. O modelo baseia-se no conjunto de dados MS MARCO, usando a versão tevatron-msmarco-aug com fortes negativos. A primeira etapa envolve a geração de instruções, onde Llama-3-70B-Instruct cria diversas instruções específicas para cada questão, variando em extensão e estilo. Estas instruções acompanham os bons versos originais, conforme confirmado por FollowIR-7B.
A segunda etapa, minas não instrucionais, apresenta passagens com perguntas, mas sem instruções. Este processo incentiva o modelo a considerar tanto a consulta quanto as instruções durante o treinamento. O GPT-4 gera esses versos, que são então filtrados usando FollowIR-7B para garantir a precisão. A validação humana confirma a eficiência deste processo de filtragem, a concordância modelo-humano chega a 84%.
Esta abordagem abrangente para aumento de dados permite que o Promptriever adapte suas condições de correspondência dinamicamente com base em comandos de linguagem natural, melhorando significativamente suas capacidades de recuperação em comparação com modelos IR tradicionais.
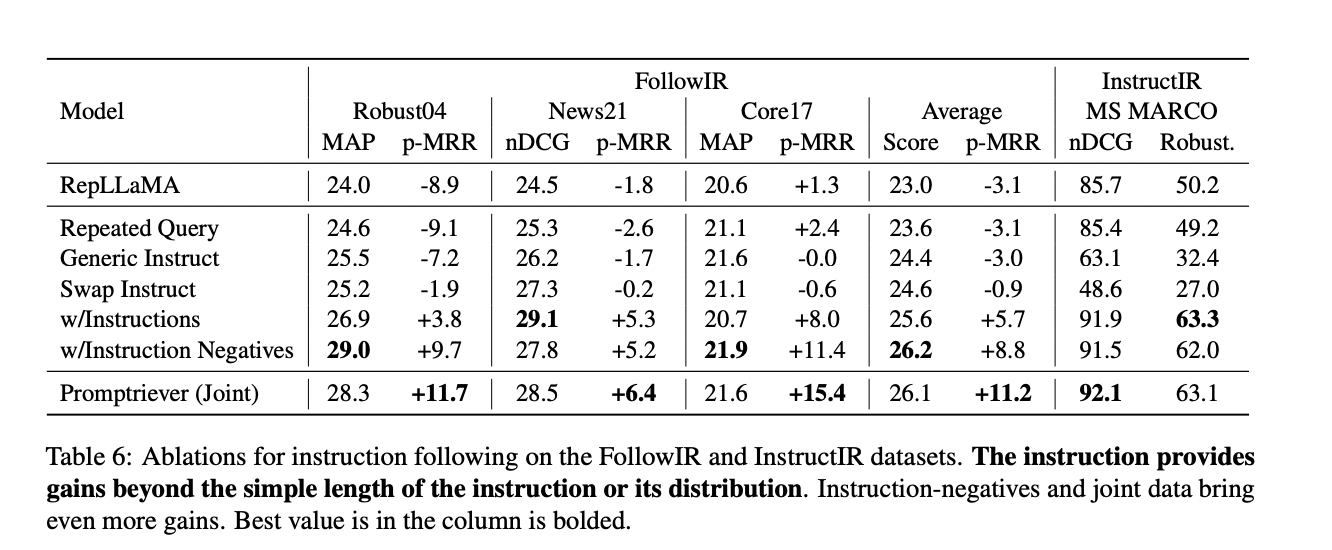
O Prompttriever mostra alto desempenho no aprendizado subsequente, ao mesmo tempo em que mantém fortes habilidades gerais de recuperação. Supera o RepLLaMA original por uma margem significativa, com uma melhoria de +14,3 p-MRR e +3,1 em nDCG/MAP, tornando-o o candidato mais eficaz disponível. Embora os modelos de codificador cruzado obtenham melhores resultados devido à sua vantagem computacional, o desempenho do Promptriever como modelo de dois codificadores é comparável e mais eficiente.
Para operações de recuperação padrão sem comandos, o Promptriever executa de acordo com RepLLaMA para operações dentro do domínio (MS MARCO) e operações fora do domínio (BEIR). Além disso, o Promptriever apresenta 44% menos variabilidade nas informações em comparação com o RepLLaMA e 77% menos que o BM25, indicando uma maior robustez à variabilidade de entrada. Esses resultados enfatizam a eficácia do método Prompttriever baseado em comando para melhorar a precisão da recuperação e a adaptabilidade a uma variedade de consultas.
Este estudo apresenta o Promptriever, um avanço significativo na recuperação de informações, introduzindo o primeiro prompt zero retriever. Desenvolvido usando um conjunto de dados exclusivo baseado em comandos disponível no MS MARCO, este modelo apresenta alto desempenho tanto em tarefas de recuperação padrão quanto em comandos seguintes. Ao ajustar dinamicamente seus critérios de relevância com base nas instruções de cada consulta, o Prompttriever demonstra o uso bem-sucedido de técnicas de prompts, desde modelos de linguagem até recuperação densa. Esta inovação abre caminho para sistemas de recuperação de informação flexíveis e fáceis de usar, preenchendo a lacuna entre o processamento de linguagem natural e capacidades de pesquisa eficientes.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso SubReddit de 52k + ML
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.


