")
O surgimento do aprendizado de máquina trouxe melhorias significativas nos modelos de linguagem, que são a base de tarefas como geração de texto e resposta a consultas. Entre estes, os modelos de transformadores e de espaço de estados (SSMs) são importantes, porém sua eficiência ao lidar com sequências longas tem causado desafios. À medida que o comprimento da sequência aumenta, os transformadores tradicionais sofrem de complexidade quadrática, levando a requisitos proibitivos de memória e computacionais. Para resolver estas questões, investigadores e organizações exploraram outras arquiteturas, como a Mamba, um modelo de espaço de estados com complexidade linear que fornece medição e eficiência para operações de conteúdo de longo alcance.
Grandes modelos de linguagem muitas vezes enfrentam desafios no controle de custos computacionais, especialmente porque atingem milhões de parâmetros. Por exemplo, embora o Mamba ofereça vantagens complexas, o seu tamanho aumentado resulta num maior consumo de energia e custos de formação, dificultando a implantação. Estas limitações são agravadas pelos elevados requisitos de recursos de modelos como estruturas baseadas em GPT, que são tradicionalmente treinadas e assumidas com precisão absoluta (por exemplo, FP16 ou BF16). Além disso, à medida que cresce a procura por IA eficiente e escalável, testar métodos de escalabilidade extrema tornou-se essencial para garantir uma implementação eficaz em ambientes com recursos limitados.
Os pesquisadores exploraram técnicas como poda, quantização de baixo bit e otimização de cache de valor-chave para mitigar esses desafios. A quantização, que reduz a faixa mínima de pesos dos modelos, tem mostrado resultados promissores na compactação de modelos sem degradação significativa de desempenho. No entanto, a maioria desses esforços concentrou-se em modelos baseados em transformadores. O comportamento dos SSMs, especialmente do Mamba, sob medições extremas ainda precisa ser estudado, criando uma lacuna no desenvolvimento de modelos de paisagem escaláveis e eficientes para aplicações do mundo real.
Pesquisadores da Universidade de Inteligência Artificial Mohamed bin Zayed e da Universidade Carnegie Mellon apresentaram Bi Mambaarquitetura escalonável Mamba de 1 bit projetada para ambientes com pouca memória e alto desempenho. Esta abordagem inovadora utiliza treinamento de reconhecimento de binarização na estrutura geoespacial Mamba, que permite computação redundante enquanto mantém o desempenho competitivo. O Bi-Mamba foi desenvolvido com tamanhos de modelo de 780 milhões, 1,3 bilhão e 2,7 bilhões de parâmetros e treinado do zero usando perda de destilação autorregressiva. O modelo usa modelos de professores altamente precisos, como o LLaMA2-7B, para orientar o treinamento, garantindo um forte desempenho.
O design do Bi-Mamba utiliza uma seleção binária de seus módulos lineares enquanto mantém outros componentes com precisão absoluta para equilibrar eficiência e desempenho. A entrada e a saída são implementadas duplamente usando módulos FBI-Linear, que incluem escala legível e recursos dinâmicos para representação do peso total. Isso garante que os dois parâmetros correspondam perfeitamente aos seus equivalentes de precisão total. O treinamento do modelo usou 32 GPUs NVIDIA A100 para processar grandes conjuntos de dados, incluindo 1,26 bilhão de tokens de fontes como RefinedWeb e StarCoder.
Testes extensivos mostraram que o Bi-Mamba é competitivo com os modelos existentes. Para conjuntos de dados como Wiki2, PTB e C4, o Bi-Mamba alcançou uma pontuação de confusão de 14,2, 34,4 e 15,0, o que é mais eficaz do que outros métodos como GPTQ e Bi-LLM, que mostraram uma confusão de até 10× mais. Além disso, o Bi-Mamba alcançou uma precisão de tiro zero de 44,5% para o modelo 780M, 49,3% para o modelo 2.7B e 46,7% para a variante 1.3B nas seguintes tarefas, como BoolQ e HellaSwag. Isto comprovou a sua robustez em várias tarefas e conjuntos de dados, mantendo ao mesmo tempo um desempenho com eficiência energética.
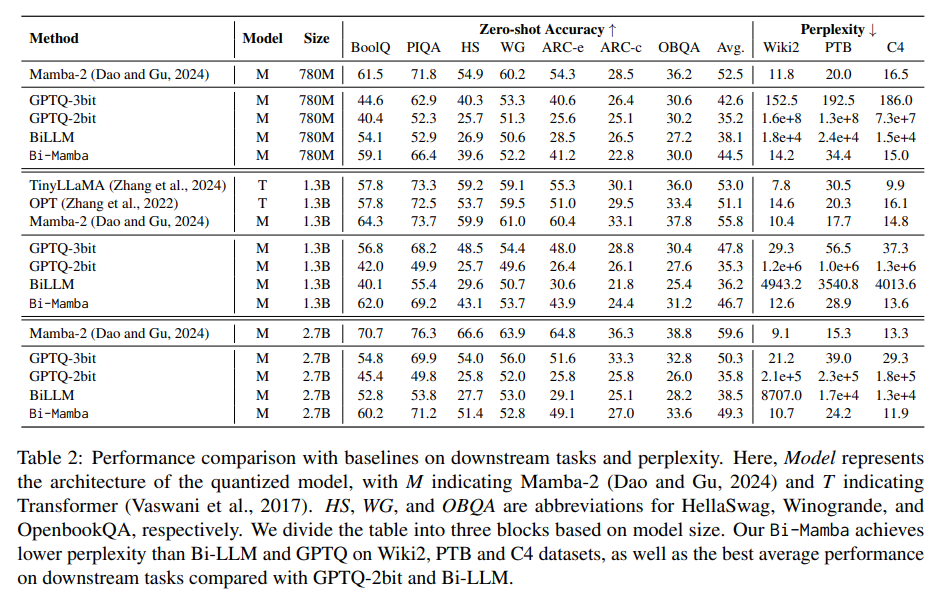
As conclusões deste estudo destacam várias conclusões importantes:
- Eficiência de benefícios: O Bi-Mamba atinge mais de 80% de compactação de armazenamento em comparação com modelos de precisão total, reduzindo o tamanho do armazenamento de 5,03 GB para 0,55 GB no modelo de 2,7B.
- Consistência de desempenho: O modelo mantém desempenho semelhante ao de seus equivalentes de precisão total, com requisitos de memória significativamente reduzidos.
- Escalabilidade: As estruturas Bi-Mamba permitem um treinamento eficaz para todos os modelos de múltiplos tamanhos, com resultados competitivos mesmo para a maior variedade.
- Robustez à binarização: Ao selecionar seletivamente dois módulos lineares, o Bi-Mamba evita a degradação do desempenho frequentemente associada aos métodos básicos de síntese binária.

Em conclusão, o Bi-Mamba representa um importante passo em frente na abordagem dos desafios duplos de medição e eficiência em grandes variedades linguísticas. Ao utilizar o treinamento de reconhecimento de binarização e focar em melhorias estruturais críticas, os pesquisadores mostraram que os modelos de espaço de estados podem alcançar alto desempenho em simulações extremas. Esta inovação melhora a eficiência energética, reduz o consumo de recursos e prepara o terreno para desenvolvimentos futuros em sistemas de IA de baixo nível, abrindo caminho para a implantação de modelos de grande escala em ambientes eficientes e com recursos limitados. Os fortes resultados do Bi-Mamba sublinham o seu potencial como uma tecnologia revolucionária de IA sustentável e eficiente.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Conferência Virtual GenAI gratuita com. Meta, Mistral, Salesforce, Harvey AI e mais. Junte-se a nós em 11 de dezembro para este evento de visualização gratuito para aprender o que é necessário para construir grande com pequenos modelos de pioneiros em IA como Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face e muito mais.
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre o público.
🐝🐝 Leia este relatório de pesquisa de IA da Kili Technology 'Avaliação de vulnerabilidade de um modelo de linguagem grande: uma análise comparativa de métodos de passagem vermelha'


