 para fornecer anotações bem caracterizadas de modelos de linguagem de grandes ideias")
Os Vision Language Models (VLMs) mostraram capacidades notáveis na produção de texto semelhante ao humano em resposta a imagens, com exemplos notáveis, incluindo os modelos GPT-4, Gemini, PaLiGemma, LLaVA e Llama 3 Vision. No entanto, estes modelos produzem frequentemente conteúdos com visualizações negativas que não têm base adequada nas imagens de referência, o que evidencia uma falha significativa na fiabilidade do resultado. O desafio de detectar e prevenir tais percepções exige que modelos de recompensa (MRs) eficazes sejam testados e desenvolvidos. Os RM atuais baseados na classificação binária fornecem apenas uma avaliação de um único ponto para todos os resultados, o que limita severamente a sua interpretabilidade e granularidade. Esse método de teste rigoroso obscurece o processo básico de tomada de decisão, tornando difícil para os desenvolvedores identificar áreas específicas de melhoria e aplicar melhorias direcionadas ao desempenho do VLM.
Esforços anteriores para melhorar o desempenho do VLM se concentraram no Reinforcement Learning from Human Feedback (RLHF), que desenvolveu com sucesso modelos de linguagem como ChatGPT e LLaMA 3. Esses métodos normalmente envolvem o treinamento de modelos de recompensa em dados semelhantes aos humanos e o uso de algoritmos como -Proximal Otimização de políticas. (PPO) ou Otimização Direta de Políticas (DPO) para aprendizagem de políticas. Embora algumas melhorias tenham sido feitas nos modelos de recompensa de processo e nos modelos de recompensa inteligentes, as soluções existentes para detectar falsos positivos são amplamente limitadas ao domínio linguístico e operam na granularidade do nível da frase. Outros métodos exploraram a geração artificial de dados e a mineração negativa pesada usando anotação humana, métodos baseados em heurística e métodos híbridos que incluem geração automatizada e validação manual. No entanto, estas abordagens não abordaram adequadamente o desafio central de representar e avaliar características visuais em VLMs, o que continua a ser um obstáculo significativo ao desenvolvimento de modelos básicos confiáveis de linguagem visual.
Pesquisadores da Meta e da Universidade do Sul da Califórnia apresentaram o Prêmio Detetive de Nível Token (TLDR) modelo, representando sucesso na avaliação dos resultados do VLM, fornecendo testes token a token em vez de testes de ponto único. Esta abordagem granular permite a identificação precisa de ideias e erros no texto gerado, tornando-o inestimável para anotadores humanos que são capazes de identificar e corrigir rapidamente certas partes problemáticas. O TLDR aborda o preconceito inerente aos modelos de recompensa binária, que tendem a favorecer textos longos sem conteúdo enganoso, incorporando fortes mecanismos de suporte visual. Ao combinar cuidadosamente indicadores multimodais com métodos avançados para exibir recursos visuais, o modelo alcança um desempenho significativamente melhorado na detecção de incompatibilidades de conteúdo. A arquitetura do sistema facilita a integração perfeita com métodos de desenvolvimento de modelos existentes, como DPO e PPO, ao mesmo tempo que serve como objetivos de treinamento que podem melhorar o desempenho do modelo de visão subjacente.
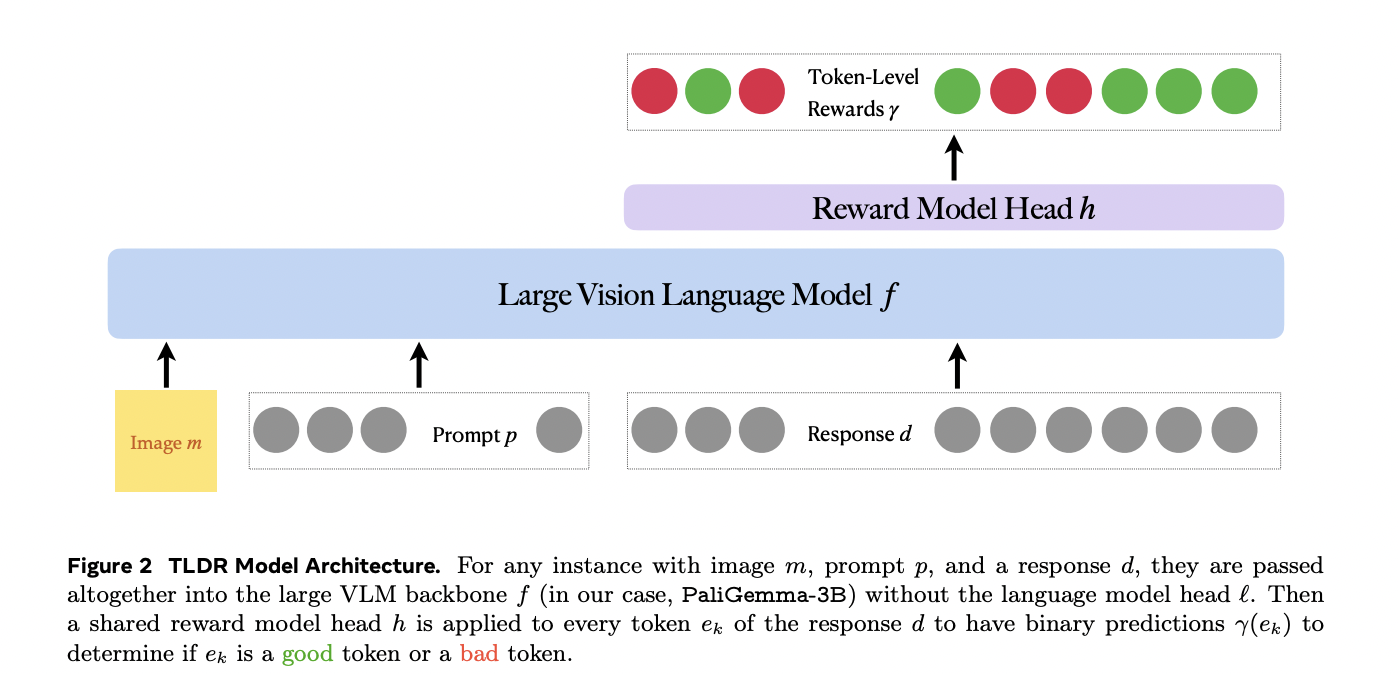
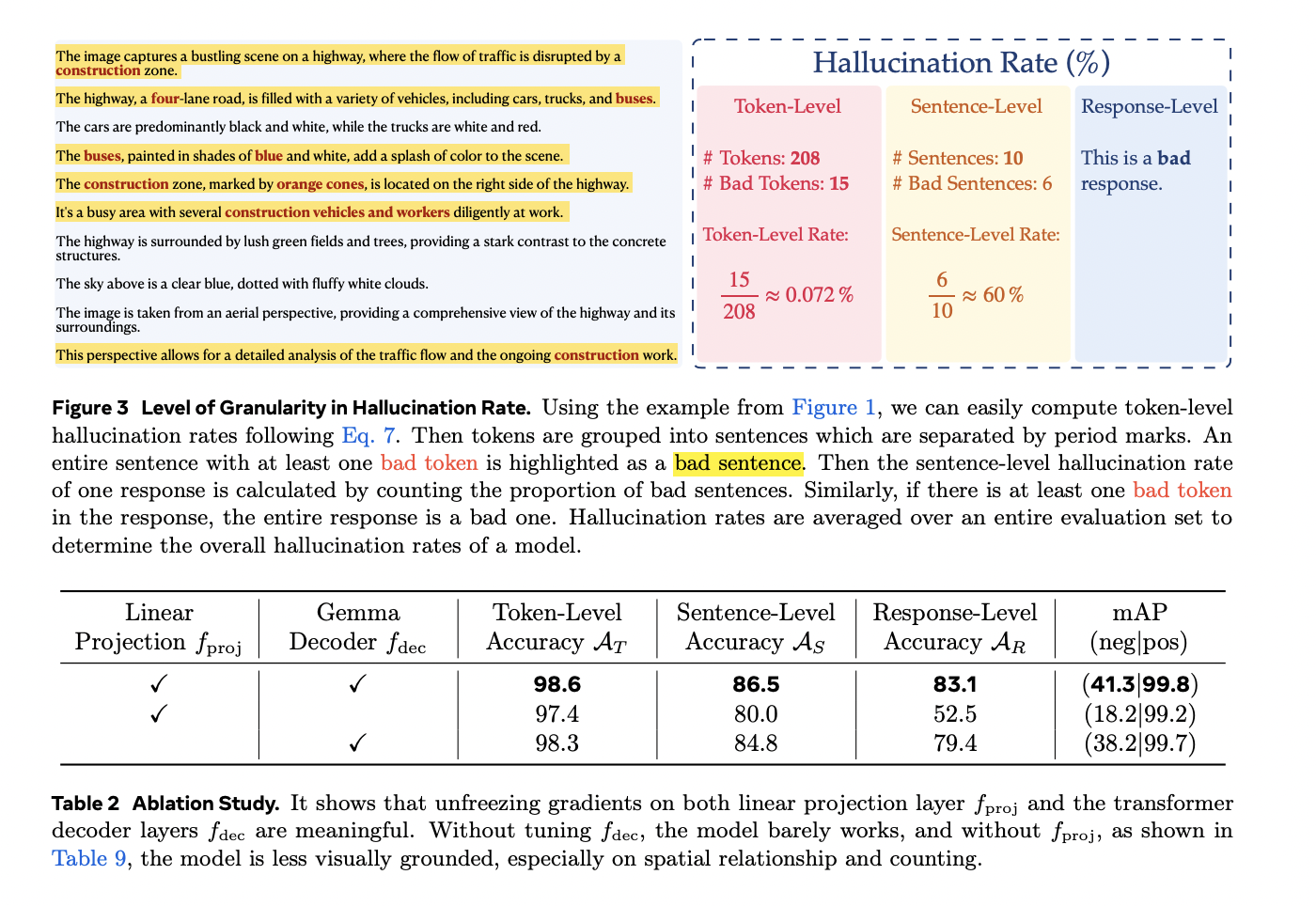
O modelo TLDR se aplica a vários cenários de resposta de consulta, incluindo imagem, entrada de texto do usuário e resposta de texto. Ao contrário dos modelos de premiação tradicionais que geram categorias binárias, o TLDR avalia cada token em cada resposta, gerando uma pontuação entre 0 e 1 com base em um limite θ (normalmente 0,5). O desempenho do modelo é avaliado usando três métricas de precisão diferentes: precisão em nível de token para avaliar tokens individuais, precisão em nível de frase para avaliar segmentos de texto correspondentes e precisão em nível de resposta para avaliar toda a saída. Para lidar com problemas de escassez e granularidade de dados, o sistema utiliza técnicas sofisticadas de processamento de dados, concentrando-se principalmente em legendas densas e funções de resposta visual a consultas. Os dados de treinamento são desenvolvidos por meio de um processo sistemático de perturbação usando grandes modelos linguísticos, visando principalmente oito taxonomias importantes: relações espaciais, características visuais, ligação de atributos, identificação de objetos, contagem, detecção de pequenos objetos, OCR de texto e casos falsos. Essa abordagem abrangente garante testes rigorosos em uma variedade de desafios de linguagem visual.
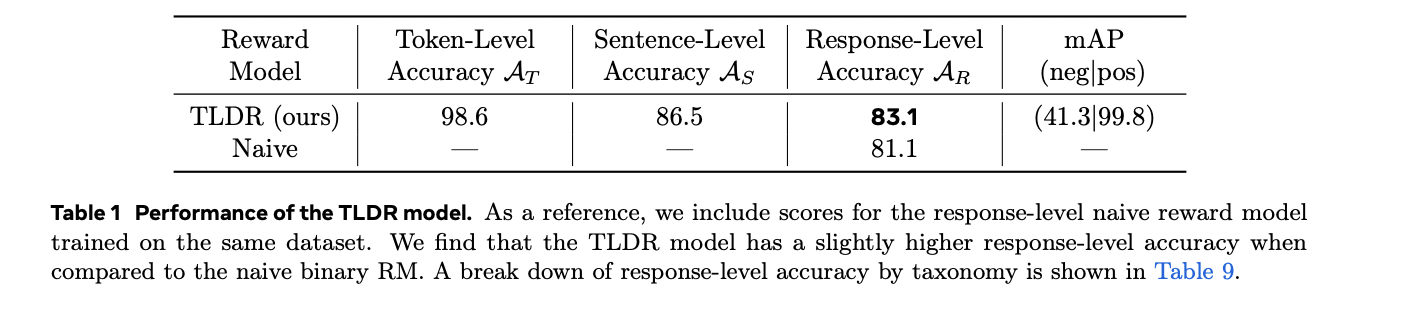
O modelo TLDR mostra desempenho robusto em múltiplas métricas de teste quando testado em dados sintéticos do conjunto de dados DOCCI. A análise de desempenho revela uma precisão de taxa de resposta ligeiramente maior em comparação com os modelos tradicionais de recompensa binária, alcançando uma pontuação significativa de 41,3 mAP(neg). A classificação detalhada da taxonomia apresenta alguns desafios na avaliação das relações espaciais, em linha com as limitações conhecidas da atual tecnologia VLM. Os testes humanos de previsão de nível de token em imagens WinoGround, que se concentram em falsos positivos, mostram uma baixa taxa de falsos positivos de 8,7%. Em aplicações práticas, a eficácia do TLDR é demonstrada pela detecção de quase acidentes em todos os principais VLMs, incluindo Llama-3.2-Vision, variantes de GPT-4, MiniCPM, PaLiGemma e Phi 3.5 Vision. O GPT-4o apresenta o melhor desempenho com níveis mínimos de fantasmas em todos os níveis de granularidade. A aplicabilidade do modelo estende-se a aplicações do mundo real, como evidenciado pela análise do conjunto de dados PixelProse, onde identificou tokens associados a 22,39% das ideias de legenda, com uma taxa de tokens e uma taxa de sentenças falsas de 0,83% e 5,23%, respectivamente.


Modelo de recompensa do Token Level Explorer representa um avanço significativo na avaliação e desenvolvimento de modelos linguísticos de percepção através de suas capacidades de anotação no nível de tokens puros. Além de simplesmente apontar erros, o TLDR identifica áreas problemáticas específicas, permitindo uma autocorreção e detecção de erros eficazes. O desempenho do modelo também se estende a aplicações do mundo real, servindo como um método de otimização potencial e facilitando processos rápidos de anotação humana. Esta abordagem inovadora estabelece a base para métodos avançados de pós-treinamento em nível de DPO e PPO, marcando um importante passo em frente no desenvolvimento do VLM.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️
 ajustado a partir do PaLM-2 para prever múltiplas propriedades de negócios relevantes para o desenvolvimento terapêutico")

