
Os avanços no processamento de linguagem natural aumentaram enormemente o poder dos modelos linguísticos, tornando-os ferramentas valiosas para uma variedade de aplicações, incluindo assistentes virtuais, geração automatizada de conteúdo e processamento de dados. À medida que estes modelos se tornam mais complexos, garantir que produzem resultados seguros e éticos torna-se mais crítico. Os modelos de linguagem, por definição, podem ocasionalmente produzir conteúdo prejudicial ou incorreto, o que apresenta riscos significativos quando usados em ambientes do mundo real. Isto levou a preocupações crescentes sobre a sua segurança, especialmente ao lidar com questões sensíveis ou potencialmente perigosas. Garantir que estes modelos sejam úteis e inofensivos continua a ser um grande desafio para os investigadores.
Um dos principais problemas nesta área é evitar que modelos de linguagem gerem textos inseguros. Embora técnicas como o ajuste fino em conjuntos de dados seguros tenham sido desenvolvidas para resolver este problema, elas não são infalíveis. Os modelos podem ser vulneráveis a dados contra-intuitivos ou não conseguirem reconhecer efeitos subtis mas prejudiciais. Além disso, uma vez que o modelo começa a produzir texto inseguro, tende a continuar da mesma forma, exigindo mais capacidade de autocorreção. Esta incapacidade de recuperação de gerações inseguras cria um problema contínuo, uma vez que o conteúdo malicioso, uma vez criado, muitas vezes circula sem uma forma integrada de reverter o caminho. Portanto, o desafio reside em prevenir resultados inseguros e criar uma forma de corrigi-los ou revertê-los quando ocorrerem.
As abordagens existentes para resolver problemas de segurança em modelos de linguagem são principalmente orientadas para a prevenção. Técnicas como o ajuste fino supervisionado (SFT) e o aprendizado por reforço a partir do feedback humano (RLHF) são frequentemente usadas para reduzir a probabilidade de resultados inseguros. Esses métodos envolvem treinar o modelo com exemplos de respostas seguras, orientando-o a favorecer resultados éticos e apropriados em detrimento dos prejudiciais. No entanto, apesar destas melhorias, os modelos treinados com estas técnicas ainda podem ser induzidos a produzir scripts inseguros através de ataques adversários sofisticados. Há também uma lacuna importante nos métodos atuais: eles não possuem um mecanismo que permita ao modelo voltar atrás ou “reiniciar” quando gera conteúdo impróprio, limitando sua capacidade de lidar com situações problemáticas de forma eficaz.
Pesquisadores da Meta AI introduziram uma técnica chamada “reversão” para resolver essa lacuna. Esta abordagem dá aos modelos de linguagem a capacidade de reverter resultados inseguros através de implementações especiais [RESET] um símbolo. A introdução deste token permite que o modelo descarte conteúdo inseguro gerado anteriormente e inicie uma nova geração a partir de um local seguro. Este método de regressão pode ser incorporado em programas de treinamento existentes, como SFT ou Direct Preference Optimization (DPO), que melhora a capacidade do modelo de detectar e se recuperar de resultados inseguros. Ao contrário das técnicas convencionais baseadas na prevenção, o feedback centra-se na manutenção, permitindo ao modelo ajustar o seu comportamento em tempo real.
O mecanismo de regressão permite que o modelo de linguagem monitore a saída e detecte quando começa a gerar conteúdo inseguro. Quando isso acontece, o modelo gera um [RESET] símbolo, que diz para descartar a parte perigosa do script e reiniciar de um local seguro. Este método é inovador na sua capacidade de bloquear uma ampla gama de conteúdos nocivos e flexibilidade. Os pesquisadores treinaram seus modelos usando técnicas SFT e DPO, garantindo que a regressão possa ser aplicada a todas as diferentes estruturas e modelos. Incorporar isso no treinamento de modelos de linguagem fornece uma maneira perfeita para os modelos se autocorrigirem durante o processo de produção, sem exigir intervenção manual.
A eficácia do método reverso foi extensivamente testada, com resultados impressionantes. Na análise, o modelo Llama-3-8B treinado em regressão apresentou melhora significativa na segurança, reduzindo a taxa de resultados inseguros de 6,1% para apenas 1,5%. Da mesma forma, o modelo Gemma-2-2B reduziu a produção insegura de 10,6% para 6,1%. Notavelmente, esta melhoria na segurança não ocorreu às custas da usabilidade do modelo. Em termos de utilidade, os modelos mantiveram a sua utilização em atividades não relacionadas com a segurança. Os pesquisadores também testaram o método de reversão contra vários ataques adversários, incluindo busca semidirigida e ataques baseados em mutação, e descobriram que os modelos equipados com reversão eram mais resistentes a esses ataques do que os modelos básicos. Por exemplo, o modelo Llama-3-8B mostrou uma redução de 70% em todas as violações de segurança, provando que a regressão pode melhorar significativamente a segurança do modelo, mesmo sob condições desafiadoras.
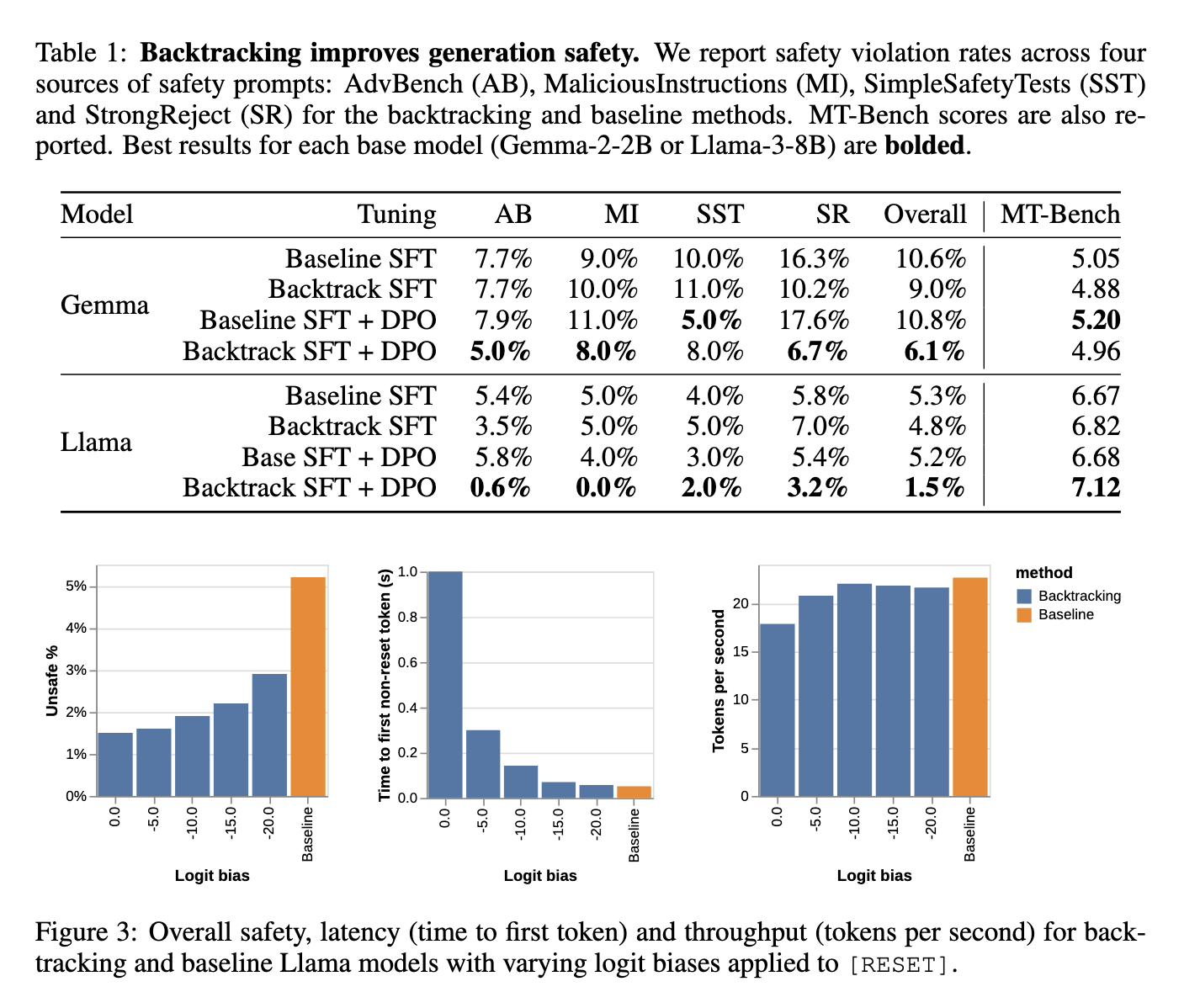
Além disso, a regressão mostrou maior robustez à eficiência operacional. Embora a adição de uma reversão tenha acrescentado algum atraso ao processo de produção (devido à necessidade de descartar e atualizar o conteúdo), o impacto na velocidade geral de produção foi mínimo. Os pesquisadores descobriram que a correção do viés logarítmico poderia reduzir ainda mais o equilíbrio entre segurança e eficiência, permitindo o ajuste fino do efeito do método no desempenho. Eles relataram que o uso de um pequeno viés logit pode manter o desempenho do modelo e, ao mesmo tempo, manter um alto nível de segurança. Essas descobertas destacam que o método equilibra segurança e desempenho com sucesso, tornando-o uma adição viável aos modelos de linguagem do mundo real.
Concluindo, o método de regressão fornece uma nova solução para o problema de gerações de modelos de linguagem inseguros. Permitir que modelos descartem resultados inseguros e gerem respostas novas e mais seguras aborda uma lacuna crítica nas actuais estratégias de segurança. Os resultados de um estudo conduzido por pesquisadores da Meta e da Carnegie Mellon University mostram que a regressão pode melhorar significativamente a segurança dos tipos de linguagem sem afetar sua funcionalidade. Esta abordagem representa um avanço promissor no esforço contínuo para garantir que os modelos linguísticos sejam úteis e inofensivos quando utilizados na prática prática.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.


