
Modelos linguísticos de grande escala (LLMs) revolucionaram o campo da IA com sua capacidade de gerar textos semelhantes aos humanos e realizar raciocínios complexos. No entanto, independentemente das suas competências, os LLMs precisam de ajuda em empregos que exijam conhecimentos específicos de um domínio, especialmente em saúde, direito e finanças. Quando treinados em grandes conjuntos de dados, esses modelos muitas vezes perdem informações críticas de domínios especializados, levando à falta de observações ou a respostas imprecisas. O desenvolvimento de LLMs com dados externos foi proposto como uma solução para essas limitações. Ao integrar informações relevantes, os modelos tornam-se mais precisos e eficientes, melhorando significativamente o seu desempenho. O método Retrieval Advanced Generation (RAG) é um excelente exemplo deste método, que permite aos LLMs obter os dados necessários durante o processo de produção para fornecer respostas precisas e oportunas.
Um dos problemas mais importantes na emissão de LLMs é a incapacidade de lidar com questões que exigem conhecimentos específicos e atualizados. Embora os LLMs sejam altamente qualificados quando trabalham com conhecimentos gerais, eles falham quando recebem tarefas especializadas ou urgentes. Essa deficiência ocorre porque a maioria dos modelos é treinada em dados estáticos, portanto, eles só podem atualizar seu conhecimento com informações externas. Por exemplo, nos cuidados de saúde, um modelo que necessita de acesso às orientações médicas atuais terá dificuldade em fornecer conselhos precisos, o que poderá colocar vidas em risco. Da mesma forma, os sistemas jurídicos e financeiros precisam de ser actualizados regularmente para acompanharem a evolução das leis e das condições de mercado. Portanto, o desafio reside no desenvolvimento de um modelo que possa capturar os dados certos para atender às necessidades específicas destes domínios.
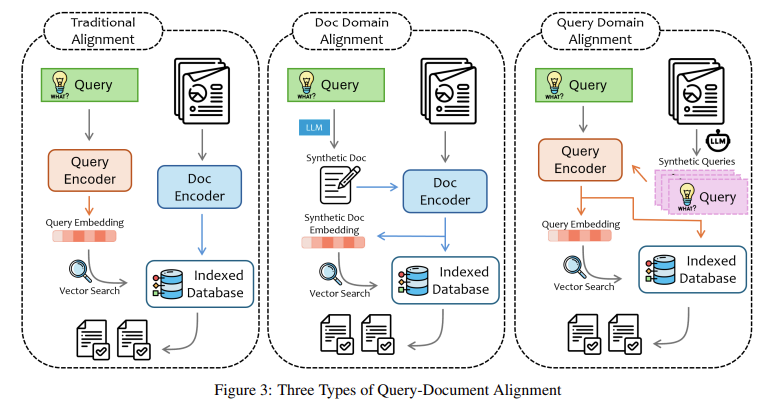
As soluções atuais, como a otimização e o RAG, fizeram progressos na abordagem destes desafios. O ajuste fino permite que o modelo seja treinado novamente em dados específicos do domínio, adaptados para tarefas específicas. No entanto, este método é demorado e requer uma grande quantidade de dados de treinamento, que só estão disponíveis algumas vezes. Além disso, o ajuste fino muitas vezes leva ao overfitting, onde o modelo se torna muito especializado e precisa de ajuda com questões gerais. Por outro lado, o RAG oferece uma abordagem mais flexível. Em vez de depender apenas de informações pré-treinadas, o RAG permite que os modelos adquiram dados externos em tempo real, melhorando a sua precisão e consistência. Apesar de suas vantagens, o RAG ainda exige diversos desafios, como a dificuldade de processamento de dados não estruturados, agregados em diversas formas como textos, imagens e tabelas.
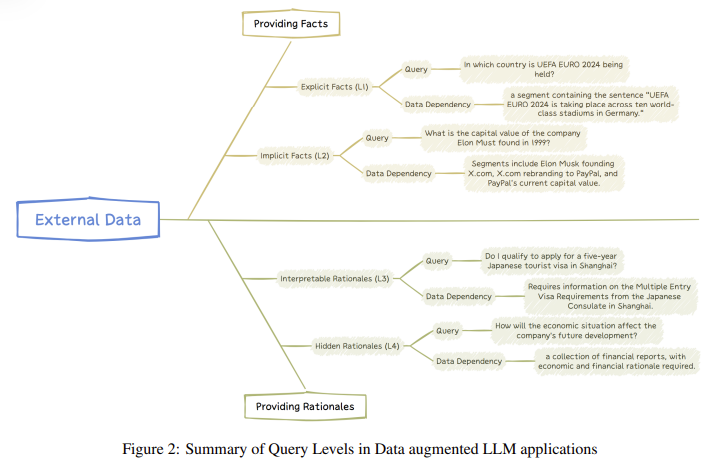
Pesquisadores da Microsoft Research Asia introduziram um novo método que divide as consultas dos usuários em quatro níveis diferentes com base na complexidade e no tipo de dados externos necessários. Esses níveis são fatos óbvios, fatos óbvios, opiniões inexplicáveis e razões sutis. A classificação ajuda a ajustar a forma de recuperação e processamento dos dados do modelo, garantindo que ele selecione as informações mais relevantes para uma determinada tarefa. Por exemplo, perguntas implícitas incluem perguntas diretas, como “Qual é a capital da França?” onde a resposta pode ser obtida a partir de dados externos. Perguntas ambíguas exigem mais reflexão, como combinar várias informações para chegar a uma conclusão. As questões de raciocínio interpretativo envolvem diretrizes específicas de domínio, enquanto as questões de raciocínio implícito requerem pensamento crítico e muitas vezes lidam com ideias abstratas.
A abordagem proposta pela Microsoft Research permite que os LLMs distingam entre esses tipos de questões e apliquem o nível apropriado de raciocínio. Por exemplo, no caso de questões de lógica implícita, onde não há uma resposta clara, o modelo pode captar padrões e utilizar o raciocínio específico do domínio para gerar uma resposta. Ao dividir as perguntas nestas categorias, o modelo torna-se mais apto a encontrar as informações necessárias e a fornecer respostas precisas e orientadas para o contexto. Essa classificação também ajuda a reduzir a carga computacional do modelo, pois agora ele pode se concentrar na recuperação apenas de dados relevantes para o tipo de consulta, em vez de verificar grandes quantidades de informações não relacionadas.
A pesquisa também revela resultados surpreendentes dessa abordagem. O programa melhorou muito o desempenho em domínios especializados, como cuidados de saúde e análise jurídica. Por exemplo, em aplicações de saúde, o modelo reduziu a taxa de alucinações em até 40%, fornecendo respostas confiáveis. A precisão do modelo no processamento de documentos complexos e no fornecimento de análises detalhadas aumentou 35% nos sistemas jurídicos. No geral, o método proposto permitiu uma recuperação mais precisa de dados relevantes, levando a uma melhor tomada de decisão e resultados mais confiáveis. A pesquisa descobriu que os sistemas baseados em RAG reduzem a incidência de alucinações, baseando as respostas do modelo em dados verificáveis, melhorando a precisão em aplicações críticas, como diagnóstico médico e processamento de documentos legais.

Em conclusão, este estudo fornece uma solução importante para uma das questões-chave na aplicação de LLMs em domínios especializados. Ao introduzir um sistema que categoriza questões com base na dificuldade e no tipo, os pesquisadores da Microsoft Research desenvolveram um método que melhora a precisão e a interpretabilidade dos resultados do LLM. Esta estrutura permite que os LLMs encontrem os dados externos mais relevantes e os utilizem de forma mais eficaz para questões específicas de domínio, reduzindo suposições e melhorando o desempenho geral. A pesquisa mostrou que o uso da segmentação de consultas estruturadas pode melhorar os resultados em até 40%, tornando este um importante avanço em aplicativos baseados em IA. Ao abordar o problema da recuperação de dados e da integração de conhecimento externo, este estudo abre caminho para aplicações LLM confiáveis e robustas em vários setores.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.


