 para resposta a consultas de contexto longo aprimorada com modelos de linguagem grande (LLMs)")
A geração aumentada de recuperação (RAG), uma técnica que melhora a eficiência de modelos linguísticos de grande escala (LLMs) no tratamento de grandes quantidades de texto, é importante para o processamento de linguagem natural, especialmente para aplicações como resposta a consultas, onde o contexto da informação está armazenado. é essencial para gerar respostas precisas. À medida que os modelos linguísticos se desenvolvem, os investigadores esforçam-se por ultrapassar os limites, melhorando a forma como estes modelos processam e obtêm informações relevantes a partir de dados de texto em grande escala.
Um grande problema com os LLMs existentes é a sua dificuldade em gerir condições de longo prazo. À medida que a extensão do contexto aumenta, os modelos precisam de ajuda para manter um foco claro nas informações relevantes, o que pode levar a uma diminuição significativa na qualidade das suas respostas. Esta questão é particularmente importante em questionários, onde a precisão é muito importante. Os modelos muitas vezes ficam sobrecarregados com o volume de informações, o que pode fazer com que retornem dados irrelevantes, reduzindo a precisão das respostas.
Em implementações recentes, LLMs como GPT-4 e Gemini são projetados para lidar com sequências de texto muito longas, com alguns modelos suportando até 1 milhão de tokens no contexto. No entanto, esses desenvolvimentos trazem seu próprio conjunto de desafios. Embora os LLMs com contextos longos possam, teoricamente, lidar com grandes entradas, eles muitas vezes introduzem informações desnecessárias ou irrelevantes no processo, resultando em baixas taxas de precisão. Portanto, os pesquisadores ainda buscam melhores soluções para gerenciar com eficiência cenários longos, mantendo a qualidade da resposta e o uso eficiente dos recursos computacionais.
Pesquisadores da NVIDIA, com sede em Santa Clara, Califórnia, propuseram um método de geração aumentada de recuperação com preservação de ordem (OP-RAG) para enfrentar esses desafios. O OP-RAG oferece melhorias significativas em relação aos métodos RAG convencionais, preservando a ordem dos fragmentos de texto retornados para processamento. Ao contrário dos sistemas RAG existentes, que priorizam fragmentos com base em pontuações relativas, o método OP-RAG preserva a sequência original do texto, garantindo que o contexto e a coerência sejam preservados durante todo o processo de recuperação. Este desenvolvimento permite uma recuperação de informação mais estruturada, evitando as armadilhas dos sistemas RAG tradicionais que podem devolver dados altamente relevantes, mas fora de contexto.
A abordagem OP-RAG introduz uma nova abordagem que reorganiza a forma como a informação é processada. Primeiro, o texto em grande escala é dividido em pedaços menores e sequenciais. Essas peças são então avaliadas com base em sua relevância para a questão. Em vez de alinhá-los apenas em sequência, o OP-RAG garante que os fragmentos sejam armazenados na ordem em que aparecem no texto fonte. Esse salvamento sequencial ajuda o modelo a se concentrar na recuperação dos dados mais relevantes para o contexto, sem introduzir distrações irrelevantes. Os pesquisadores demonstraram que este método melhora significativamente a qualidade da geração de respostas, especialmente em situações de contexto longo, onde manter a consistência é importante.
O desempenho do método OP-RAG foi bem avaliado em relação a outros modelos líderes. Pesquisadores da NVIDIA realizaram testes usando conjuntos de dados públicos, como os benchmarks EN.QA e EN.MC do ∞Bench. Seus resultados mostraram uma melhoria significativa tanto na precisão quanto na eficiência em comparação aos LLMs tradicionais com núcleos longos sem RAG. Por exemplo, no conjunto de dados EN.QA, que contém uma média de 150.374 palavras por contexto, o OP-RAG alcançou uma pontuação máxima F1 de 47,25 ao usar tokens de 48K como entrada, uma melhoria significativa em relação a modelos como o GPT-4O. Da mesma forma, para o conjunto de dados EN.MC, o OP-RAG superou os outros modelos por uma grande margem, atingindo uma precisão de 88,65 com apenas 24 mil tokens, enquanto o modelo tradicional Llama3.1 sem RAG só conseguiu atingir uma precisão de 71,62 usando 117 mil tokens .
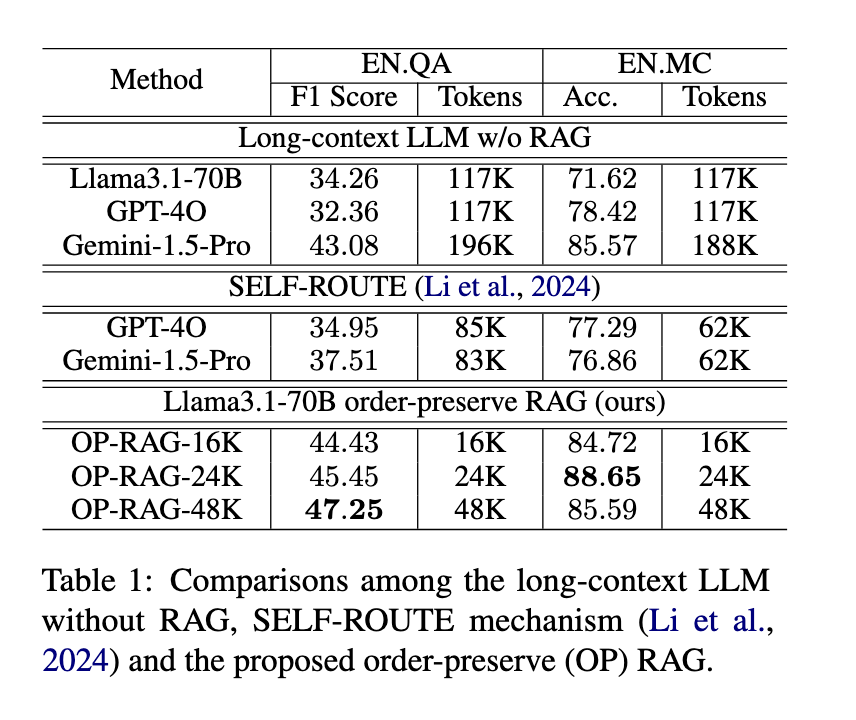
Outras comparações mostraram que o OP-RAG melhorou a qualidade das respostas geradas e reduziu significativamente o número de tokens necessários, tornando o modelo mais eficiente. LLMs convencionais com núcleos longos, como GPT-4O e Gemini-1.5-Pro, exigiram quase o dobro do número de tokens em comparação com OP-RAG para atingir pontuações de desempenho baixas. Esta eficiência é especialmente importante em aplicações do mundo real, onde o custo computacional e a alocação de recursos são fatores-chave na execução de grandes modelos de linguagem.
Concluindo, o OP-RAG apresenta um avanço importante no campo da geração expandida por recuperação, fornecendo uma solução para as limitações dos LLMs de longo prazo. Ao preservar a ordem dos fragmentos de texto retornados, o método permite a geração de respostas consistentes e contextualmente relevantes, mesmo para questionários grandes. Pesquisadores da NVIDIA demonstraram que este método inovador supera os métodos existentes em termos de qualidade e eficiência, tornando-o uma solução promissora para avanços futuros no processamento de linguagem natural.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter de novo LinkedIn. Junte-se a nós Estação telefônica.
Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🐝 Participe do boletim informativo de pesquisa de IA de crescimento mais rápido, lido por pesquisadores do Google + NVIDIA + Meta + Stanford + MIT + Microsoft e muito mais…


