 com decodificação inferencial")
Os modelos de linguagem em larga escala (LLMs) estão rapidamente se tornando uma parte fundamental das aplicações atuais de consumo e de negócios. No entanto, a necessidade de geração rápida de tokens continua sendo um desafio constante, tornando-se muitas vezes um gargalo para aplicações emergentes. Por exemplo, a última tendência em escalas de tempo preditivas utiliza resultados muito longos para realizar pesquisas e outros algoritmos complexos, enquanto os sistemas LLM têm muitos agentes e pipelines que visam melhorar a precisão e a confiabilidade, mas ambos sofrem frequentemente de longos tempos de resposta devido à espera. através de vários estágios de processamento. Abordar esta necessidade de acelerar a produção de tokens é fundamental para o desenvolvimento contínuo e a adoção generalizada de aplicações baseadas em LLM.
Os métodos de previsão baseados em modelos existentes têm limitações que dificultam a sua capacidade de enfrentar eficazmente o desafio de acelerar a produção de tokens em LLMs. Primeiro, estes métodos dependem fortemente do tamanho e da qualidade do modelo preliminar, que pode nem sempre estar disponível, exigindo formação dispendiosa ou afinação para criar um modelo adequado. Em segundo lugar, a integração de modelos preliminares e LLMs em GPUs pode levar a problemas e ineficiências, como conflitos entre o uso de memória do modelo preliminar e o cache de valores-chave do LLM. Para resolver esses problemas, trabalhos recentes exploraram a incorporação de cabeças de decodificação adicionais diretamente no LLM para realizar a decodificação preditiva. No entanto, esses métodos ainda enfrentam os mesmos desafios, pois cabeçotes adicionais precisam ser ajustados para cada LLM e consomem memória GPU significativa. Superar essas limitações é essencial para o desenvolvimento de estratégias robustas e eficientes para acelerar a obtenção do LLM.
Pesquisadores da Snowflake AI Research e da Carnegie Mellon University apresentam SufixoDecodificaçãoabordagem robusta sem modelo que evita a necessidade de modelos preliminares ou cabeçotes de decodificação adicionais. Em vez de depender de modelos separados, SuffixDecoding usa índices de árvore de sufixos construídos a partir de gerações anteriores de saída e aplicativos atuais de previsão contínua. O processo começa tokenizando rapidamente cada par de respostas usando o vocabulário LLM, extraindo todos os sufixos possíveis (de qualquer posição até o final) para construir uma estrutura de árvore de sufixos. Cada nó na árvore representa um símbolo e o caminho da raiz para qualquer nó corresponde a uma sequência dos dados de treinamento. Essa abordagem sem modelo elimina os problemas e a sobrecarga de GPU associados à integração de modelos de rascunho ou cabeçotes de decodificação adicionais, apresentando uma alternativa altamente eficiente para acelerar o acesso ao LLM.
Para cada nova solicitação de inferência, SuffixDecoding constrói uma árvore de sufixos exclusiva para cada solicitação dos tokens de informações atuais. Este design é importante para atividades em que se espera que o resultado do LLM faça referência ou reutilize o conteúdo das informações de entrada, como resumo de documentos, resposta a perguntas, sessões de discussão dinâmica e codificação. A árvore de sufixos armazena uma contagem de frequência em cada nó para rastrear com que frequência ocorrem diferentes sequências de tokens, permitindo uma correspondência eficiente de padrões. Dada qualquer sequência de tokens recentes na geração atual, SuffixDecoding pode percorrer rapidamente a árvore para encontrar todas as continuações possíveis da saída imediata ou anterior. Em cada etapa de inferência, SuffixDecoding seleciona as melhores subárvores de tokens de continuação com base em estatísticas de frequência e probabilidades funcionais. Esses tokens inferidos são então passados para o LLM para verificação, o que é feito em uma passagem direta graças ao operador de árvore geradora de máscara causal com reconhecimento de topologia.
Semelhante a trabalhos anteriores, como LLMA e Prompt Lookup Decoding, SuffixDecoding é um método livre de modelo que encontra sequências candidatas a partir de um corpus de referência. No entanto, ao contrário dos métodos anteriores que processavam pequenos textos de referência, como alguns trechos ou informações atuais, o SuffixDecoding foi projetado para usar um corpus de grande escala, composto por centenas ou milhares de resultados gerados anteriormente.
Trabalhando a partir deste grande corpus de referência, SuffixDecoding pode usar cálculos de frequência de forma sistemática para selecionar as sequências candidatas mais prováveis. Para permitir a geração rápida dessas sequências candidatas, SuffixDecoding constrói uma árvore de sufixos sobre sua referência. O nó raiz da árvore representa o início da anexação de qualquer documento do corpus, onde o documento é o resultado de uma consideração anterior ou a entrada e saída de uma consideração atual em andamento. O caminho da raiz para cada nó representa uma sequência do corpus de referência e cada nó filho representa uma possível continuação do token.
SuffixDecoding usa essa estrutura de árvore de sufixos para correspondência de padrões bem-sucedida. Dados os tokens gerados da informação composta atualmente considerada, ele identifica a sequência do padrão e percorre a árvore de sufixos para encontrar todas as continuações possíveis que aparecem no corpus de referência. Embora isso possa produzir um grande conjunto de sequências candidatas, SuffixDecoding usa um processo ganancioso de escalonamento e pontuação para construir uma árvore de predição menor, que pode então ser usada na etapa final da predição baseada em árvore.
Os resultados dos testes completos demonstram o poder do método SuffixDecoding. No conjunto de dados AgenticSQL, que representa um pipeline LLM complexo e de vários estágios, o SuffixDecoding atinge uma taxa de transferência até 2,9x maior e uma latência de tempo de token (TPOT) até 3x menor em comparação com a linha de base do SpecInfer. Para tarefas mais abertas, como diálogo e codificação, SuffixDecoding ainda oferece forte desempenho, até 1,4x maior e 1,1x menor latência TPOT do que SpecInfer.
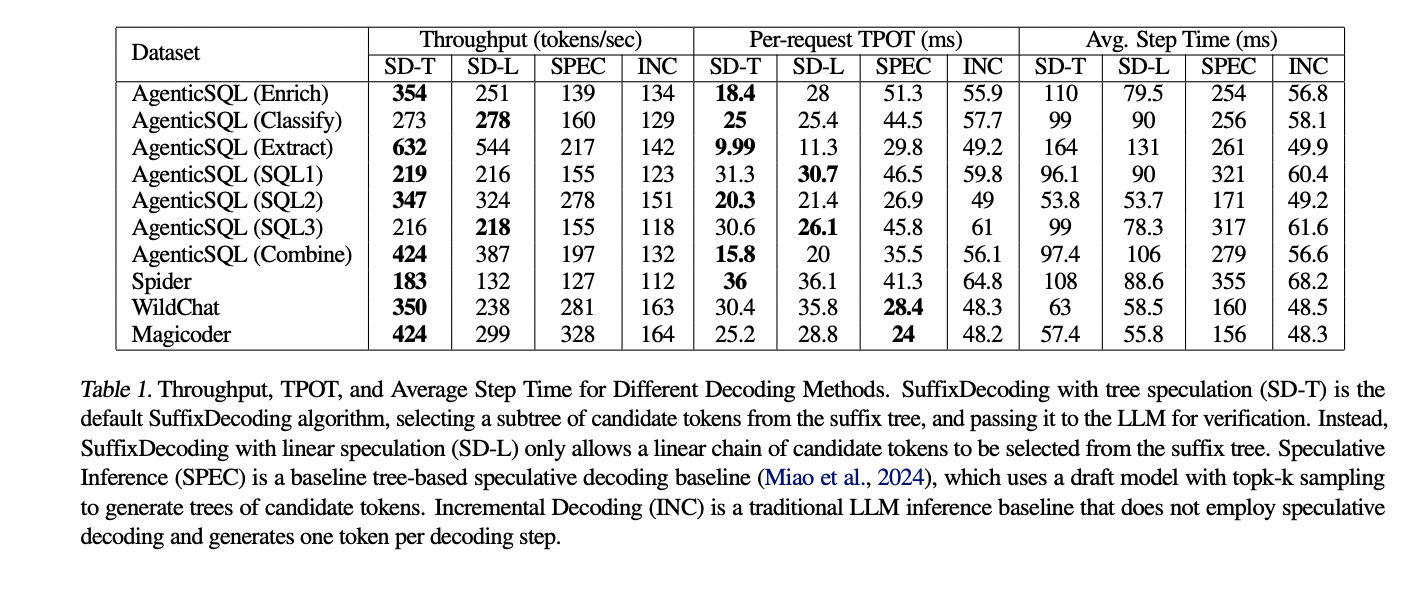
O teste também avalia a eficácia dos recursos de decodificação preditiva do SuffixDecoding. SuffixDecoding pode atingir um número médio muito maior de tokens inferidos aceitos em cada etapa de verificação em comparação com o método SpecInfer baseado no modelo preliminar. Isso mostra que a estrutura da árvore de sufixos SuffixDecoding sem modelo permite a produção de tokens de previsão mais precisos e confiáveis, aumentando a velocidade possível da coleta de suposições sem manter um modelo de rascunho diferente.


Este trabalho apresenta SufixoDecodificaçãouma abordagem sem modelo para acelerar a previsão do LLM usando árvores de sufixos construídas a partir de resultados anteriores. SuffixDecoding alcança velocidades competitivas em relação aos métodos de previsão baseados em modelos existentes em uma ampla variedade de cargas de trabalho, ao mesmo tempo que é adequado para pipelines LLM complexos e de vários estágios. Ao medir o corpus de referência em vez de depender de modelos preliminares, o SuffixDecoding mostra uma forte direção para melhorar a eficiência da modelagem preditiva e desbloquear todo o potencial de grandes modelos de linguagem em aplicações do mundo real.
Confira Detalhes aqui. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI WEBINAR] Usando processamento inteligente de documentos e GenAI em serviços financeiros e transações imobiliárias
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
🐝🐝 O próximo evento ao vivo do LinkedIn, 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão reinventando o processo de desenvolvimento de dados para ajudar as equipes a construir modelos de IA revolucionários , rápido.


