
A aprendizagem cruzada tornou-se importante para a construção de representações a partir de dados emparelhados, como combinações de imagem e texto em IA. Revelou-se muito útil na transferência do conhecimento aprendido para atividades a jusante, especialmente em domínios com dependências de dados complexas, como a robótica e os cuidados de saúde. Na robótica, por exemplo, os agentes coletam dados de sensores visuais, táteis e impessoais, enquanto os profissionais de saúde combinam imagens médicas, biossinais e dados genômicos. Cada domínio requer um modelo que possa processar vários tipos de dados simultaneamente. No entanto, os modelos de aprendizagem diferencial existentes estão em grande parte limitados a dois tipos, limitando a qualidade da representação e a aplicabilidade em situações complexas e multimodais.
Um grande desafio reside nas limitações dos modelos bidirecionais, como o CLIP, que são projetados para capturar apenas dependências de dados entre pares. Esta configuração limita o modelo à compreensão da dependência condicional partilhada por mais de dois tipos de dados, levando a uma lacuna significativa de conhecimento. Ao analisar múltiplas modalidades – como imagens, áudio e texto – a interdependência entre cada par não reflete toda a complexidade; por exemplo, se existirem três tipos de dados, um modelo binário pode compreender a ligação entre imagem-texto e áudio-texto, mas perder a relação mais ampla, especialmente se um tipo de dados for condicionalmente dependente do outro. Esta capacidade de representar vários relacionamentos além de pares de tipos de dados continua sendo uma limitação em aplicações de saúde e multimídia.
Historicamente, os pesquisadores estenderam modelos bivariados multipercursos aplicando objetivos do tipo CLIP a pares de caminhos. Embora esta abordagem dual-time introduza um certo grau de compatibilidade multimodal, ela é limitada pela necessidade de estruturas especiais ou etapas de treinamento adicionais para cada par de modalidade, dificultando a generalização. Alguns modelos que lidam com vários tipos de dados exigem arquiteturas e ajustes complexos, o que acaba limitando seu desempenho. Embora eficazes para aplicações limitadas, estes métodos requerem intervenção manual para definir os pares de processos apropriados, deixando espaço para métodos que capturem todas as interações de processos dentro de uma única missão.
Pesquisadores da Universidade de Nova York apresentam o Symile, um modelo de aprendizagem exclusivo que supera essas limitações ao capturar dependências de alta ordem em caminhos de dados sem correções complexas. Ao contrário dos métodos duais, o Symile usa uma intenção relacional completa que combina qualquer número de métodos, criando uma representação unificada sem depender de mudanças estruturais complexas. Os pesquisadores projetaram o Symile para lidar com flexibilidade com uma variedade de métodos, facilitando a generalização do conhecimento compartilhado que equilibra as dependências entre os tipos de dados. Ao encontrar um limite inferior para conectividade completa, o modelo Symile visa capturar representações específicas do mecanismo que preservam informações importantes compartilhadas, tornando-o eficiente em situações onde dados de diversos tipos estão incompletos ou ausentes.
A metodologia Symile inclui um novo objetivo alternativo que utiliza o produto interno multilinear (MIP), uma função de chamada que combina produtos escalares para enfrentar três ou mais vetores, para medir a similaridade entre vários tipos de dados. Symile maximiza os pontos positivos de uma tupla e minimiza os negativos dentro da tupla com esta função. O modelo então calcula a média dessa perda em todos os caminhos. Isso permite que o Symile capture mais do que apenas informações binárias, adicionando uma terceira camada de “informações condicionais” entre os tipos de dados. Os pesquisadores desenvolveram o modelo usando um novo método de amostragem negativa, criando diferentes amostras negativas dentro de cada cluster para facilitar os cálculos para conjuntos de dados maiores.
O desempenho do Symile em tarefas de dados multimodais destaca seu desempenho em modelos bimodais. A avaliação envolveu uma variedade de testes, incluindo a classificação de vários métodos e a recuperação de vários conjuntos de dados. Em outro experimento utilizando um conjunto de dados sintético com variáveis controladas, Symile alcançou uma precisão quase perfeita de 1,00 ao interpretar dados com informações condicionais correspondentes aos três métodos. Ao mesmo tempo, o CLIP atingiu apenas 0,50, o que é uma medida eficaz de probabilidade aleatória. Testes adicionais em um grande conjunto de dados multilíngue, Symile-M3, mostraram a precisão de 93,9% do Symile na previsão de conteúdo de imagem com base em texto e áudio nos dois idiomas, enquanto o CLIP alcançou 47,3%. Esta lacuna aumenta à medida que aumenta a complexidade do conjunto de dados; Symile manteve 88,2% de precisão ao usar dez idiomas, enquanto CLIP caiu para 9,4%. Em um conjunto de dados médicos que consiste em radiografias de tórax, eletrocardiogramas e dados laboratoriais, Symile alcançou 43,5% de precisão na correspondência de previsões corretas, superando os 38,7% do CLIP.
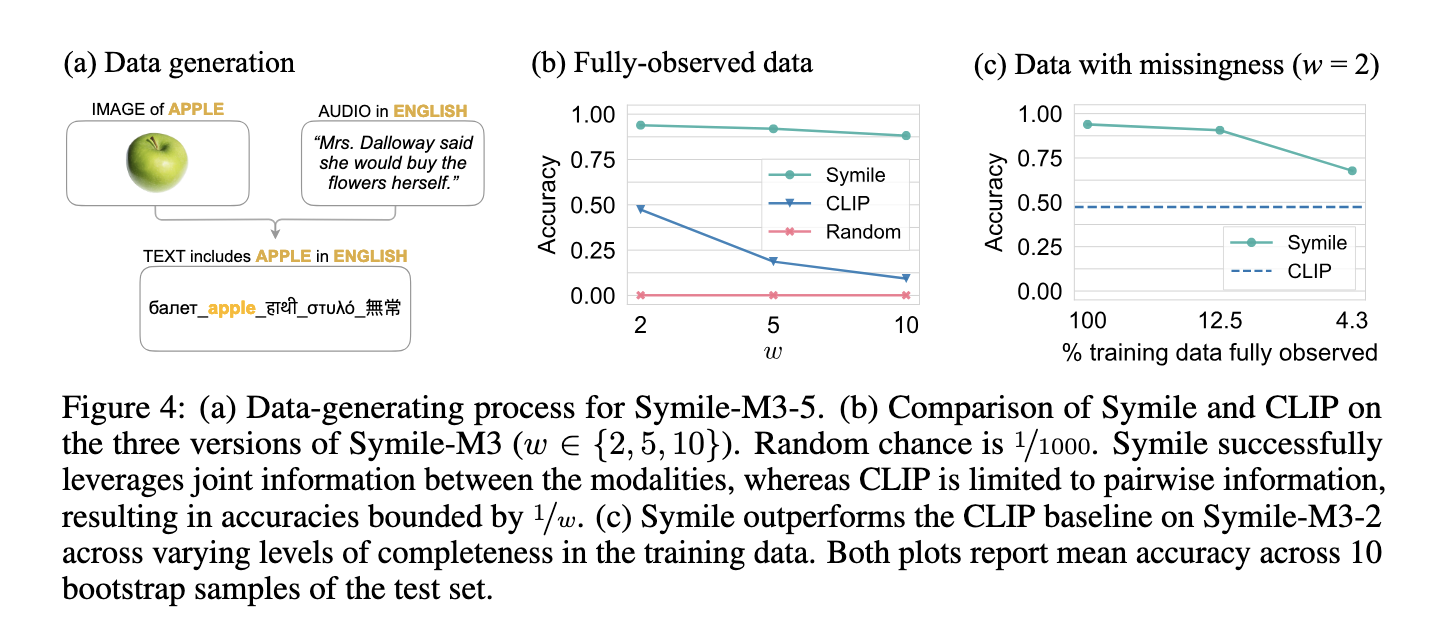
Com sua capacidade de capturar informações compartilhadas entre processos, o método Symile permite um bom desempenho mesmo quando outros tipos de dados não estão disponíveis. Por exemplo, na variante Symile-M3 onde cada caminho é deixado aleatoriamente com uma probabilidade de 50%, Symile manteve uma alta precisão de 90,6%, superando significativamente o CLIP sob as mesmas restrições. O modelo Symile lida com dados ausentes corrigindo objetivamente para manter a precisão com amostras fora de suporte, um recurso importante em aplicações do mundo real, como saúde, onde todos os dados podem nem sempre estar disponíveis.
Esta pesquisa aborda uma grande lacuna na aprendizagem transversal, permitindo que o modelo processe vários tipos de dados simultaneamente com um objetivo específico e independente da arquitetura. A abordagem relacional geral da Symile, ao capturar mais de duas informações, representa uma grande melhoria em relação aos modelos bidirecionais e oferece desempenho superior, especialmente em domínios complexos e com densidade de dados, como saúde e operações multilíngues. Ao melhorar a qualidade e a adaptabilidade da representação, o Symile está bem posicionado como uma ferramenta fundamental para a integração multimodal, fornecendo uma solução flexível adequada à natureza complexa e de alta dimensão dos dados do mundo real.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live LinkedIn event] 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão revitalizando o processo de desenvolvimento de dados para ajudar as equipes a construir modelos de IA multimodais revolucionários, rapidamente'
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


