
A modelagem linguística é um campo crescente que se concentra no aumento do uso de modelos linguísticos de grande escala (LLMs) em diversas tarefas. Com recursos que incluem geração de texto, resumo e inferência, esses modelos são cada vez mais aplicados a diversos dados de entrada. A capacidade de mudar dinamicamente tarefas específicas para o modelo mais apropriado tornou-se um grande desafio, visando equilibrar eficiência e precisão no tratamento destas tarefas multifacetadas.
Outro grande desafio na emissão de LLMs é escolher o modelo mais adequado para uma determinada função de entrada. Embora muitos LLMs pré-qualificados estejam disponíveis, seu desempenho pode variar muito de acordo com a profissão. Decidir qual modelo usar para uma determinada entrada geralmente envolve confiar em conjuntos de dados rotulados ou em anotações humanas. Esses métodos que consomem muitos recursos impõem restrições significativas à escalabilidade e à produtividade, especialmente para aplicações que exigem decisões em tempo real ou diversas habilidades.
As abordagens existentes para carreiras de LLM geralmente envolvem treinamento de facilitação ou seleção baseada em heurística. Esses métodos geralmente dependem de conjuntos de dados rotulados para estimar ou prever o modelo de melhor desempenho para uma determinada entrada. Embora eficazes até certo ponto, essas técnicas são limitadas pela disponibilidade de dados de anotação de alta qualidade e pelo custo computacional dos modelos auxiliares de treinamento. Como resultado, a utilização generalizada destes métodos continua atrasada.
Pesquisadores da Universidade de Stanford apresentaram o SMOOTHIE, uma nova técnica de processamento de linguagem não supervisionada projetada para superar as limitações dos dados rotulados. SMOOTHIE propõe princípios de supervisão fraca, utilizando um modelo de imagem variável latente para avaliar os efeitos de múltiplos LLMs. Ao calcular a média dos índices de qualidade específicos da amostra, o método move cada entrada para o LLM que tem maior probabilidade de produzir bons resultados. Esta abordagem fornece uma solução inovadora ao remover a dependência de conjuntos de dados rotulados, reduzindo significativamente os requisitos de recursos.
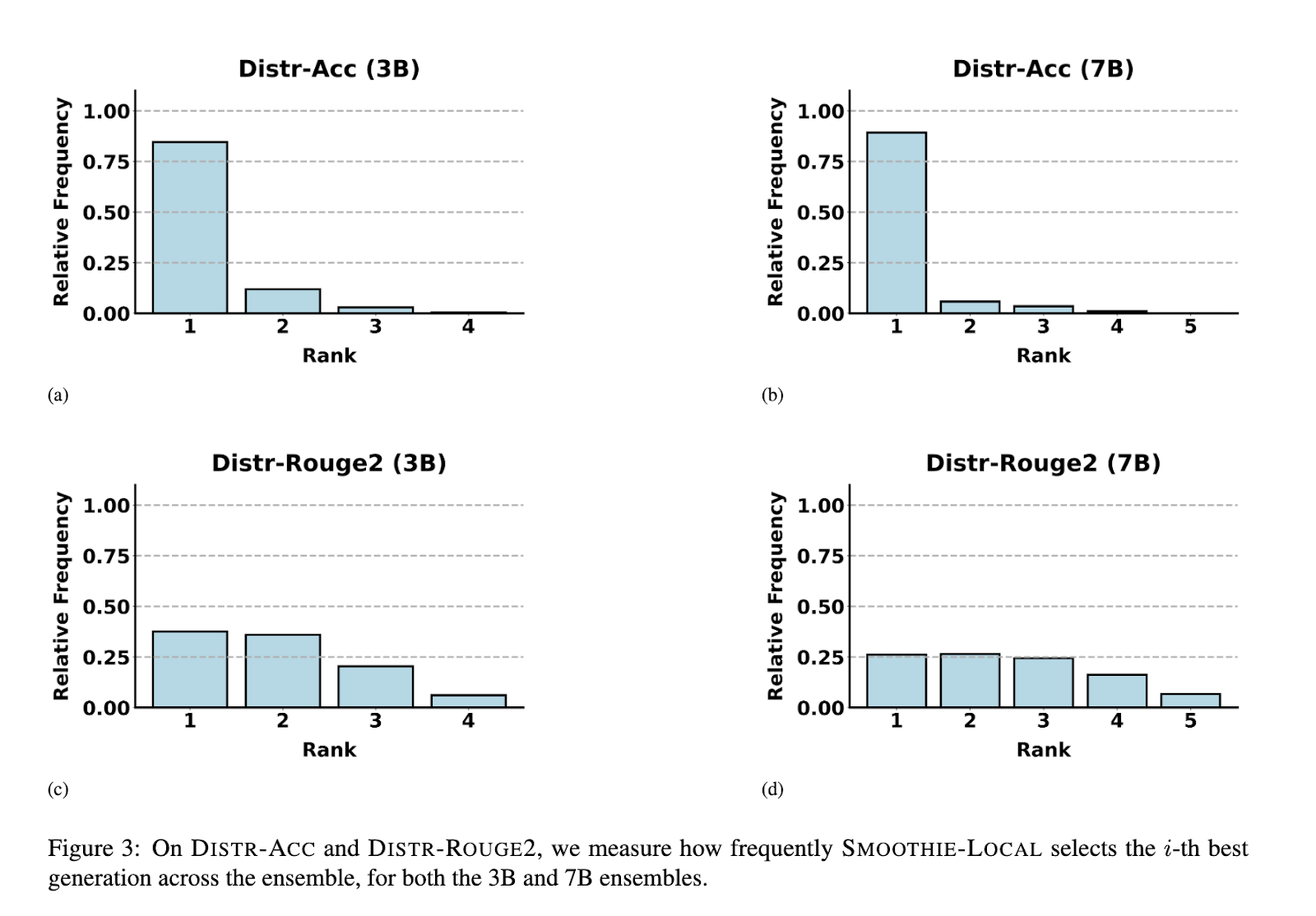
SMOOTHIE consiste em duas variantes principais: SMOOTHIE-GLOBAL e SMOOTHIE-LOCAL. SMOOTHIE-GLOBAL obtém estimativas de qualidade para todos os dados de teste, criando testes abrangentes de desempenho de modelo. Em contraste, o SMOOTHIE-LOCAL melhora este processo concentrando-se nos vizinhos mais próximos da amostra na área de incorporação, melhorando a precisão da trajetória. A metodologia utiliza representações incorporadas de resultados observáveis e variáveis latentes para modelar a diferença entre o resultado gerado e o resultado verdadeiro assumido. Essas diferenças são representadas como variáveis gaussianas, que permitem aos pesquisadores obter estimativas fechadas dos índices de qualidade. O método também inclui suavização de kernel no SMOOTHIE-LOCAL para melhorar as medidas de qualidade correspondentes a amostras individuais, garantindo que as decisões de roteamento sejam melhoradas dinamicamente.
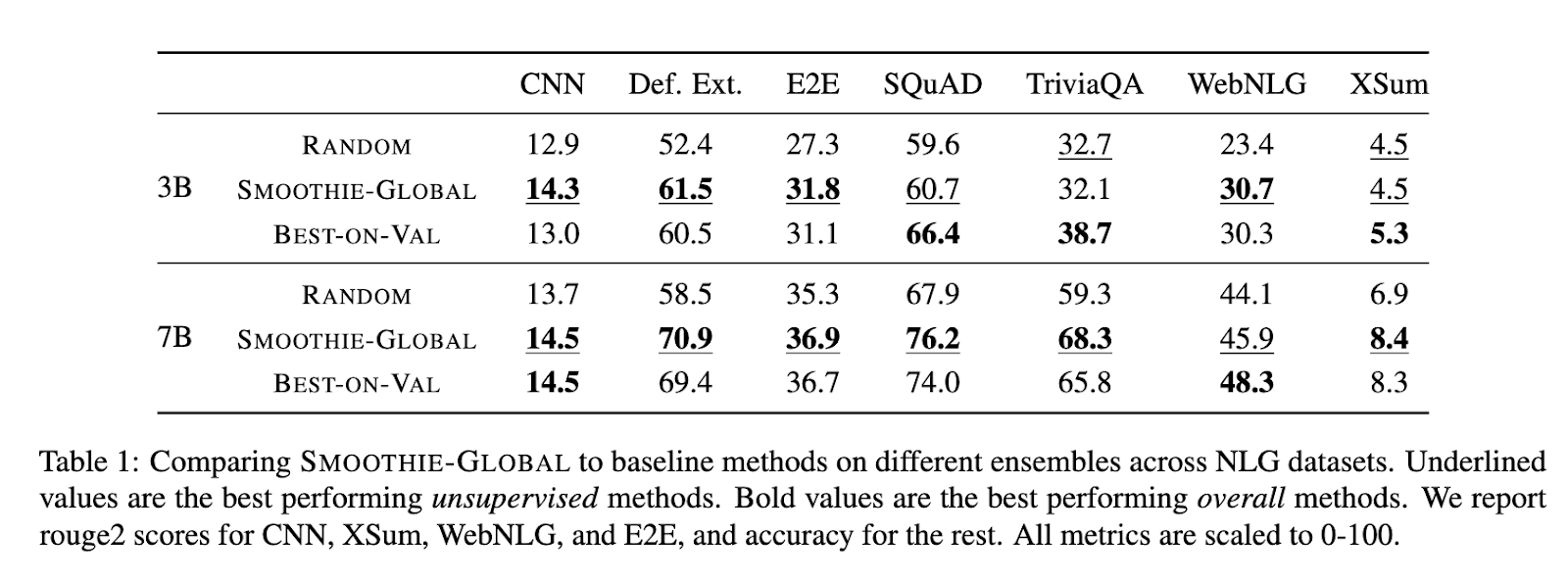
O desempenho do SMOOTHIE foi extensivamente analisado em vários conjuntos de dados e configurações. O SMOOTHIE-GLOBAL demonstrou sua capacidade de identificar o modelo com melhor desempenho em 9 das 14 tarefas. Por exemplo, em conjuntos de dados como AlpacaEval, o SMOOTHIE-GLOBAL melhorou as taxas de vitória em até 15 pontos percentuais em comparação com bases de amostragem aleatória e 8 pontos para o SQuAD. A variante LOCAL continua a ser a melhor, apresentando desempenho mais eficiente que os métodos de roteamento global e supervisionado em situações multitarefa. Em conjuntos de dados de funções mistas, o SMOOTHIE-LOCAL melhorou a precisão da função em até 10 pontos em relação aos métodos de linha de base. Além disso, encontrou uma forte correlação entre a qualidade estimada e real do modelo, com um coeficiente de correlação de classificação de 0,72 para tarefas de geração de linguagem natural e 0,94 para MixInstruct. A rota local SMOOTHIE permitiu que os modelos mais pequenos superassem os seus homólogos maiores em diversas configurações, destacando a sua eficiência em condições de eficiência de recursos.
Os resultados sublinham o potencial do SMOOTHIE para transformar o caminho LLM, abordando a dependência de dados rotulados e formação de facilitação. A combinação de técnicas fracas de monitoramento com modelos inovadores de estimativa de qualidade permite decisões de roteamento robustas e eficientes em ambientes multi-habilidades. O estudo fornece uma solução confiável e eficaz para melhorar o desempenho do LLM, abrindo caminho para uma adoção mais ampla em aplicações do mundo real onde a diversidade e a precisão das tarefas são críticas.
Esta pesquisa representa um progresso significativo no campo da modelagem de linguagem. Enfrentar os desafios na escolha de um LLM específico para um trabalho de maneira não supervisionada abre maneiras de melhorar a implantação de LLMs em uma variedade de aplicações. A introdução do SMOOTHIE agiliza o processo e garante uma melhoria significativa na qualidade dos resultados, demonstrando o potencial crescente da supervisão fraca na inteligência artificial.
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


