
Os modelos linguísticos de grande escala (LLMs) revolucionaram vários campos ao permitir o processamento eficiente de dados, a resolução de problemas complexos e a compreensão da linguagem natural. Outra inovação é a geração aumentada de recuperação (RAG), que permite aos LLMs encontrar informações relevantes de fontes externas, como grandes bancos de dados, para gerar melhores respostas. No entanto, a integração de LLMs de longo prazo com RAG apresenta alguns desafios. Em particular, quando os LLMs conseguem lidar com longas sequências de entrada, o volume de informações retornadas pode sobrecarregar o sistema. O desafio é garantir que o contexto adicional melhore a precisão do resultado do LLM, em vez de confundir o modelo com informações irrelevantes.
O problema enfrentado pelos LLMs com conteúdo longo decorre do fato de que aumentar o número de passagens retornadas não melhora o desempenho. Em vez disso, muitas vezes leva à diminuição do desempenho, principalmente devido à inclusão de documentos irrelevantes ou enganosos, conhecidos como “fortes negativos”. Esses fortes negativos parecem ser apropriados com base em certos critérios de detecção, mas apresentam ruído que engana o LLM na geração da resposta correta. Como resultado, a precisão do modelo diminui apesar do acesso a mais informações. Isto é especialmente problemático em tarefas com uso intensivo de informação, onde é importante identificar informações relevantes.
Os sistemas RAG existentes usam um recuperador para selecionar as passagens mais relevantes do banco de dados, que o LLM então processa. As implementações padrão do RAG, entretanto, tendem a limitar o número de passagens retornadas a cerca de dez. Isso funciona bem para contextos curtos, mas só funciona bem quando o número de versículos aumenta. O problema torna-se mais óbvio quando se trata de conjuntos de dados complexos com muitas categorias relevantes. Os métodos atuais devem abordar adequadamente os riscos de apresentação de informações enganosas ou irrelevantes, o que poderia reduzir a qualidade das respostas do LLM.
Pesquisadores do Google Cloud AI e da Universidade de Illinois apresentaram novas maneiras de melhorar a robustez e o desempenho dos sistemas RAG ao usar LLMs de longo prazo. Sua abordagem combina métodos gratuitos e baseados em treinamento, projetados para reduzir o impacto de imprecisões graves. Uma das principais inovações é a reordenação de recuperação, um método sem treinamento que otimiza a sequência em que as passagens recuperadas são atribuídas ao LLM. Os pesquisadores propuseram priorizar passagens com pontuações relativas altas no início e no final da sequência de entrada, concentrando assim a atenção do LLM nas informações mais importantes. Além disso, métodos baseados em treinamento são introduzidos para melhorar a capacidade do modelo de lidar com dados triviais. Isso inclui provocações fortes e consistentes e configurações de correlação claras, que treinam o LLM para identificar melhor informações relevantes e filtrar conteúdo enganoso.
A regressão de recuperação é uma técnica simples, mas eficaz, que aborda o fenômeno “perdido no meio” comumente visto em LLMs, onde o modelo tende a se concentrar mais no início e no fim da sequência de entrada, enquanto perde a atenção para as partes intermediárias. . Ao reorganizar as entradas para que as informações mais importantes sejam colocadas nas bordas da corda, os pesquisadores melhoraram a capacidade do modelo de produzir respostas precisas. Além disso, eles testaram uma configuração específica, que envolveu o treinamento do LLM em conjuntos de dados contendo informações ruidosas e potencialmente enganosas. Esta abordagem incentiva o modelo a suportar tal ruído, tornando-o mais robusto em aplicações práticas. Uma configuração de correspondência clara vai além, ensinando o LLM a analisar os documentos devolvidos e identificar as passagens mais relevantes antes de emitir uma resposta. Esta abordagem melhora a capacidade do LLM de distinguir entre informações relevantes e irrelevantes em situações complexas e com vários documentos.
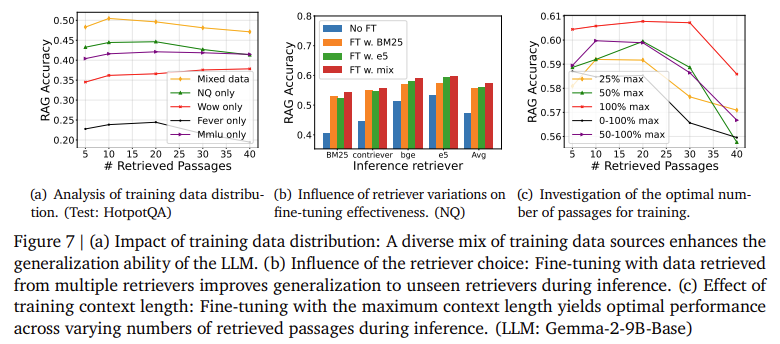
Os métodos propostos mostraram melhorias significativas em precisão e robustez. Estudos demonstraram que reordenar a recuperação melhorou a precisão do LLM em vários pontos percentuais, especialmente ao lidar com grandes conjuntos de passagens recuperadas. Por exemplo, testes no conjunto de dados Natural Questions mostraram que aumentar o número de passagens retornadas inicialmente melhorou a precisão. No entanto, o desempenho diminuiu após um certo ponto em que os aspectos negativos se tornaram mais predominantes. A introdução da reconfiguração e otimização reduziu este problema, mantendo a alta precisão à medida que o número de passagens aumentava. Notavelmente, a precisão do modelo Gemma-2-9B-Chat melhorou 5% quando o método de reamostragem foi aplicado a conjuntos de recuperação maiores, demonstrando a eficácia do método em situações do mundo real.
Principais conclusões do estudo:
- Uma melhoria na precisão de 5% foi alcançada aplicando a reordenação de recuperação a conjuntos maiores de passagens recuperadas.
- Uma configuração paralela clara permite que o modelo analise e identifique as informações mais relevantes, melhorando a precisão em situações complexas de recuperação.
- A configuração difusa torna o LLM mais robusto contra dados ruidosos e enganosos, treinando-o em conjuntos de dados desafiadores.
- Reordenar a recuperação reduz o efeito “perdido no meio”, ajudando o LLM a se concentrar nas funções mais importantes no início e no final da sequência de entrada.
- Os métodos apresentados podem ser usados para melhorar o desempenho de LLMs de longo prazo em uma variedade de conjuntos de dados, incluindo Perguntas Naturais e PopQA, onde demonstraram melhorar consistentemente a precisão.

Em conclusão, este estudo fornece soluções práticas para os desafios dos LLMs de longo prazo nos programas RAG. Ao introduzir novos métodos, como métodos de reprogramação e otimização, os pesquisadores mostraram uma maneira promissora de melhorar a precisão e a robustez desses sistemas, tornando-os mais confiáveis no tratamento de dados complexos do mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.



