
Pensar é essencial para a resolução de problemas, permitindo que as pessoas tomem decisões e encontrem soluções. Dois tipos principais de pensamento são usados na resolução de problemas: pensamento progressivo e pensamento retrógrado. Pensar no futuro envolve trabalhar desde uma pergunta até uma solução, usando etapas incrementais. Em contraste, o pensamento retrógrado começa com uma solução possível e remonta à questão original. Esta abordagem é benéfica para tarefas que requerem validação ou verificação de erros, pois ajuda a identificar inconsistências ou etapas perdidas no processo.
Um dos principais desafios da inteligência artificial é a integração de métodos de raciocínio, especialmente o raciocínio retroativo, em modelos de aprendizado de máquina. Os sistemas atuais baseiam-se numa visão de futuro, gerando respostas a partir de um conjunto de dados específico. Contudo, esta abordagem pode resultar em erros ou soluções incompletas, pois o modelo necessita verificar e corrigir o seu raciocínio. A introdução do raciocínio retroativo em modelos de IA, especialmente em modelos de grandes linguagens (LLMs), oferece uma oportunidade para melhorar a precisão e a confiabilidade desses sistemas.
As abordagens existentes para pensar nos LLMs concentram-se mais na visão de futuro, onde os modelos dão respostas baseadas no conhecimento. Outras técnicas, como a filtragem de informações, tentam melhorar o raciocínio ajustando modelos com etapas de raciocínio apropriadas. Esses métodos são frequentemente usados durante testes, onde as respostas geradas pelo modelo são verificadas cruzadamente usando raciocínio retroativo. Embora isto melhore a precisão do modelo, o pensamento retrospectivo não deve ser incluído no processo de construção do modelo, o que limita os benefícios potenciais deste processo.
Pesquisadores da UNC Chapel Hill, Google Cloud AI Research e Google DeepMind introduziram o Enhanced Thinking Framework (REVTINK). Desenvolvido pelas equipes Google Cloud AI Research e Google DeepMind, REVTINK integra o pensamento diretamente por trás do treinamento LLM. Em vez de usar o raciocínio retroativo como ferramenta de validação, esta estrutura o incorpora no processo de treinamento, ensinando modelos para lidar com tarefas de raciocínio progressivo e retrógrado. O objetivo é criar um processo de consulta poderoso e eficaz que possa ser usado para gerar respostas para uma variedade de tarefas.
A estrutura REVTINK treina modelos em três tarefas diferentes: gerar pensamento progressivo a partir de uma pergunta, uma questão retrógrada a partir de uma solução e pensamento retrógrado. Ao aprender a pensar nas duas direções, o modelo se torna mais apto a lidar com tarefas complexas, especialmente aquelas que exigem um processo de validação passo a passo. A abordagem dupla de pensamento progressivo e retrógrado melhora a capacidade do modelo de avaliar e melhorar seus resultados, levando, em última análise, a uma melhor precisão e à redução de erros.
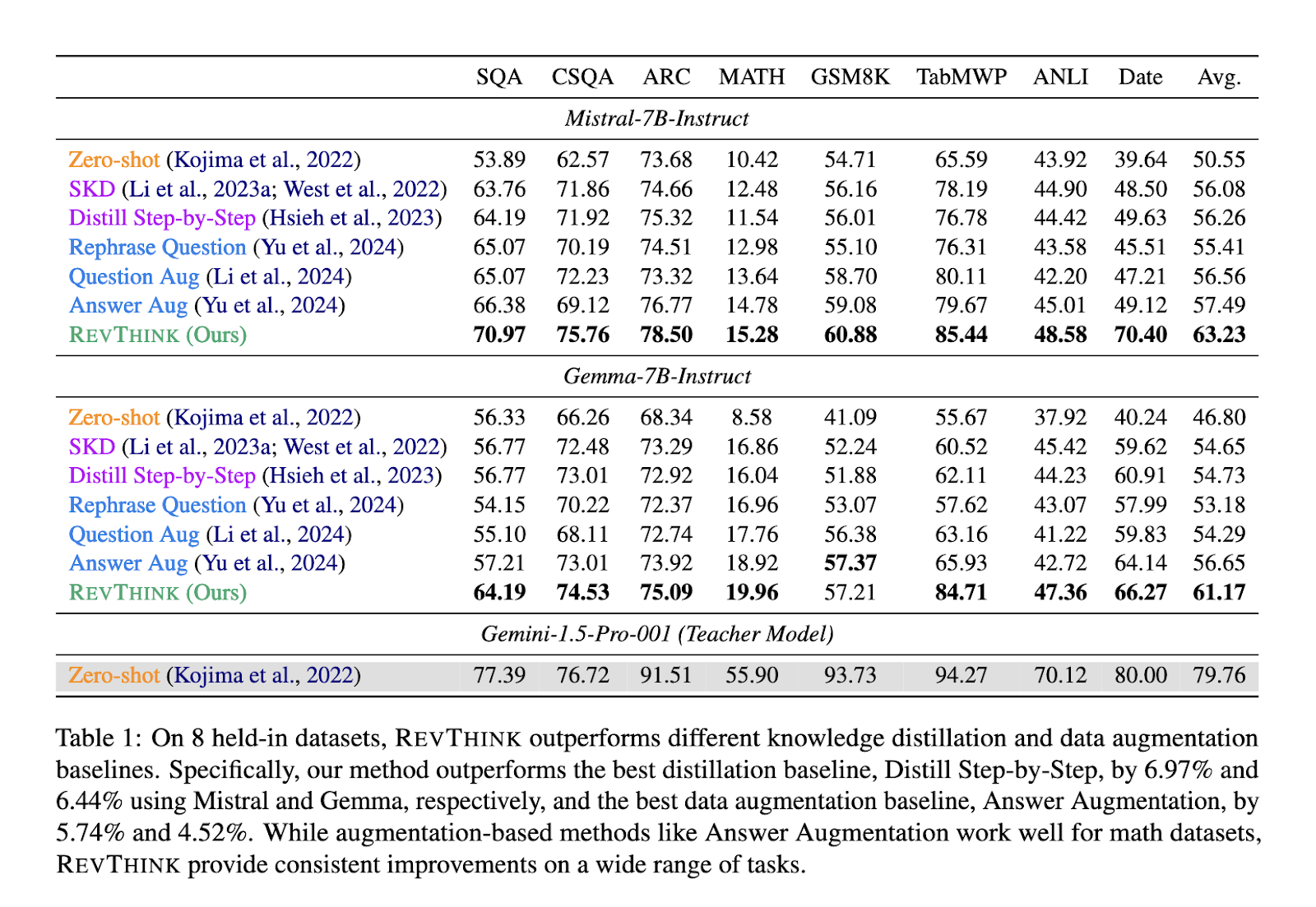
Os testes de desempenho do REVTINK mostraram melhorias significativas em relação aos métodos convencionais. A equipe de pesquisa testou a estrutura em 12 conjuntos de dados diferentes, que incluíam tarefas relacionadas ao pensamento lógico, resolução de problemas matemáticos e tarefas lógicas. Comparado ao desempenho zero shot, o modelo obteve uma melhoria média de 13,53%, demonstrando sua capacidade de compreender e gerar melhor respostas para questões complexas. A estrutura REVTINK superou os métodos robustos de mineração de dados em 6,84%, destacando seu desempenho superior. Além disso, o modelo mostrou-se mais eficaz com o uso da amostra. São necessários muito poucos dados de treinamento para alcançar esses resultados, tornando-se uma opção mais eficiente do que os métodos tradicionais que dependem de grandes conjuntos de dados.
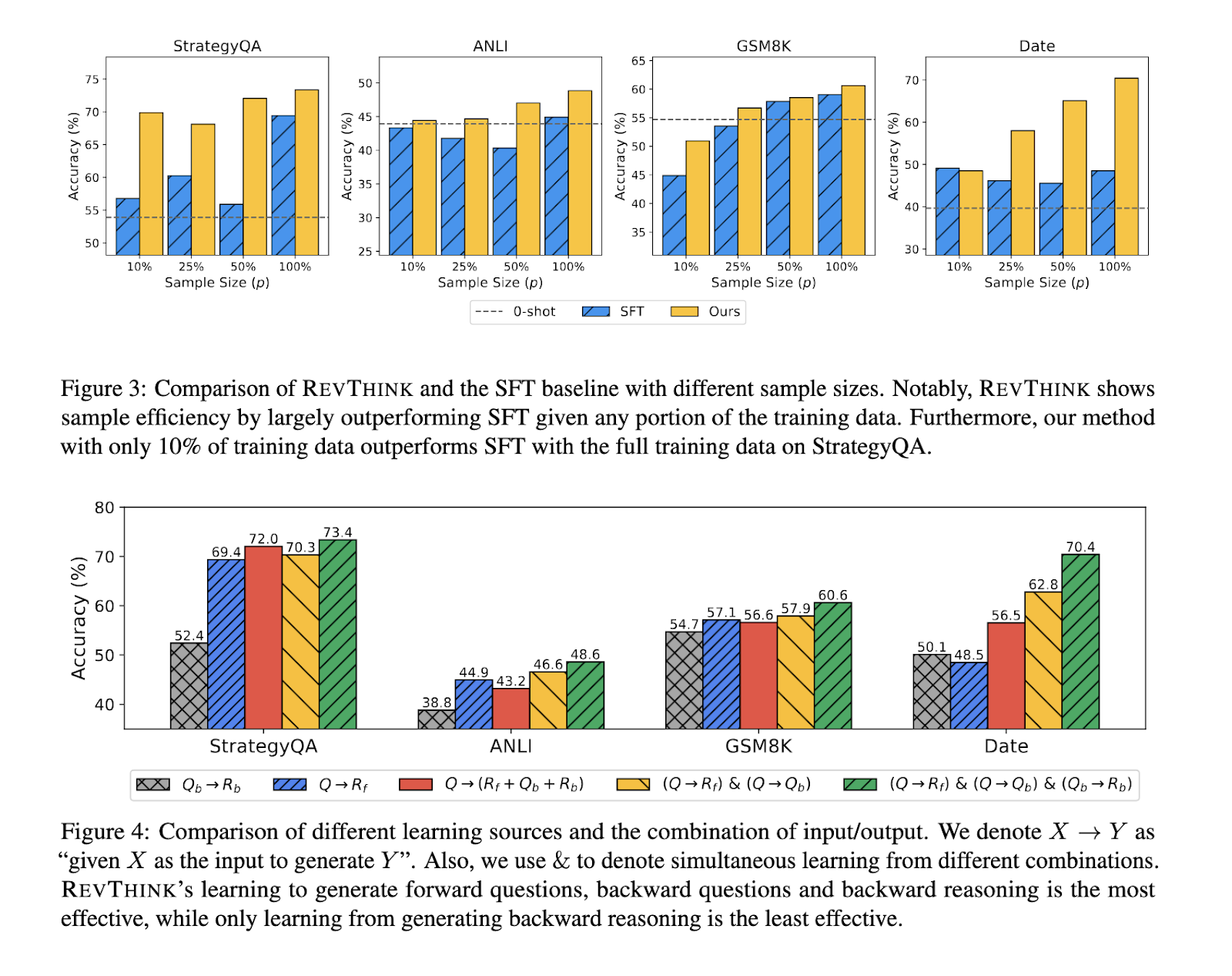
Em termos de métricas específicas, o desempenho do modelo REVTINK em diferentes domínios também demonstrou a sua multimodalidade. O modelo apresentou uma melhoria de 9,2% nas tarefas de raciocínio lógico em relação aos modelos convencionais. Mostrou um aumento de 14,1% na precisão do raciocínio lógico, indicando sua forte capacidade de raciocinar sobre situações cotidianas. A eficiência do método também se destacou, exigindo 20% menos dados de treinamento e superando benchmarks anteriores. Esta eficiência torna o REVTINK uma opção atraente para aplicações onde os dados de treinamento podem ser limitados ou caros.
O lançamento do REVTINK marca um grande avanço na forma como os modelos de IA lidam com tarefas cognitivas. O modelo pode gerar respostas mais precisas usando menos recursos, incorporando o raciocínio retroativo ao processo de treinamento. A capacidade da estrutura de melhorar o desempenho em vários domínios – especialmente com pequenos dados – demonstra o seu potencial para revolucionar o pensamento da IA. No geral, REVTINK promete criar sistemas de IA mais confiáveis que lidam com uma variedade de tarefas, desde problemas matemáticos até tomadas de decisões no mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 [Must Attend Webinar]: 'Transforme provas de conceito em aplicativos e agentes de IA prontos para produção' (Promovido)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🚨🚨 WEBINAR DE IA GRATUITO: 'Acelere suas aplicações LLM com deepset e Haystack' (promovido)


