
Nos últimos anos, houve desenvolvimentos significativos no campo de modelos pré-treinados em larga escala para a aprendizagem de políticas robóticas. O termo “representação de políticas” aqui se refere às diferentes interações e métodos de tomada de decisão dos robôs, o que pode facilitar a generalização de novas tarefas e ambientes. Visão-linguagem-ação (VLA) os modelos são pré-treinados com dados de robôs em grande escala para integrar percepção visual, compreensão da linguagem e tomada de decisão baseada em ações para orientar os robôs em diversas tarefas. No topo de modelos de linguagem de visão (VLMs)eles vêm com a promessa de fazer coisas, cenas e atividades familiares. No entanto, VLAs ele ainda precisa ser mais confiável para uso fora dos ambientes restritos de laboratório em que foram treinados. Embora esses problemas possam ser mitigados aumentando a amplitude e a diversidade dos conjuntos de dados robóticos, isso exige muitos recursos e é difícil de escalar. Em termos simples, estas apresentações políticas devem fornecer mais contexto ou um contexto mais específico que apresente políticas menos rígidas.
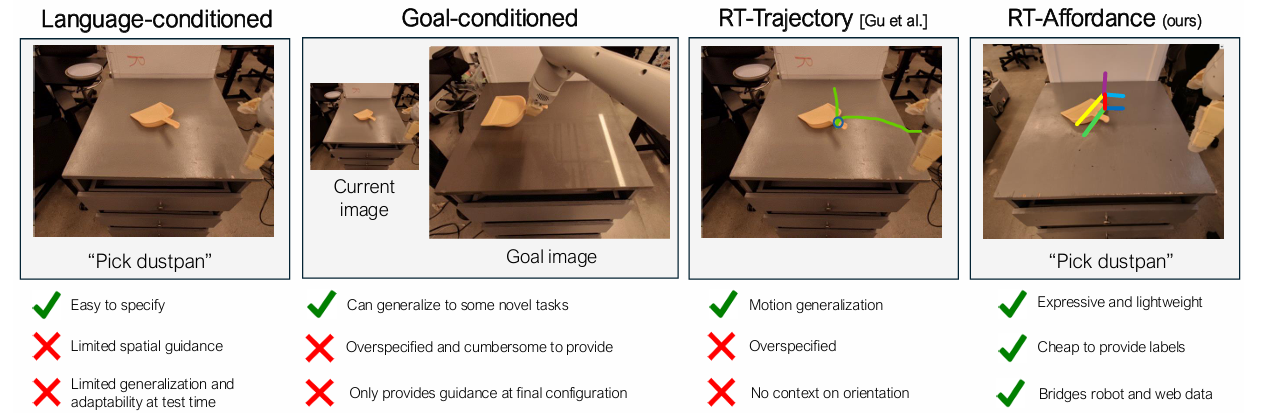
As propostas políticas existentes, como linguagem, fotos de golde novo diagramas de trajetória eles são amplamente utilizados e úteis. Uma das propostas de política mais comuns é congelar a linguagem. A maioria dos conjuntos de dados de robôs são rotulados com descrições de trabalho menos específicas, e a orientação baseada no idioma não fornece orientação suficiente sobre como realizar o trabalho. Políticas com estado de imagem de meta fornecem informações locais detalhadas sobre a configuração de meta final da cena. No entanto, as imagens dos objetivos são de alta dimensão, o que apresenta desafios de aprendizagem devido a problemas de excesso de especificação. Representações centrais, como diagramas de trajetória ou pontos-chave, tentam fornecer planos espaciais para orientar as ações do robô. Embora estes planos locais forneçam orientação, ainda carecem de informação política suficiente sobre como implementar movimentos específicos.

Uma equipe de pesquisadores do Google DeepMind conduziu um estudo detalhado sobre a representação da política de robôs e propôs RT-Acessibilidade que é um modelo hierárquico que primeiro cria um sistema de custeio dada uma linguagem de tarefa e depois usa a política desse sistema de custeio para orientar as ações manipulativas do robô. Em robôs, pagar refere-se às possíveis interações que o robô permite, com base em sua forma, tamanho, etc. RT-Acessibilidade o modelo pode conectar facilmente várias fontes de vigilância, incluindo grandes conjuntos de dados da web e trajetórias de robôs.
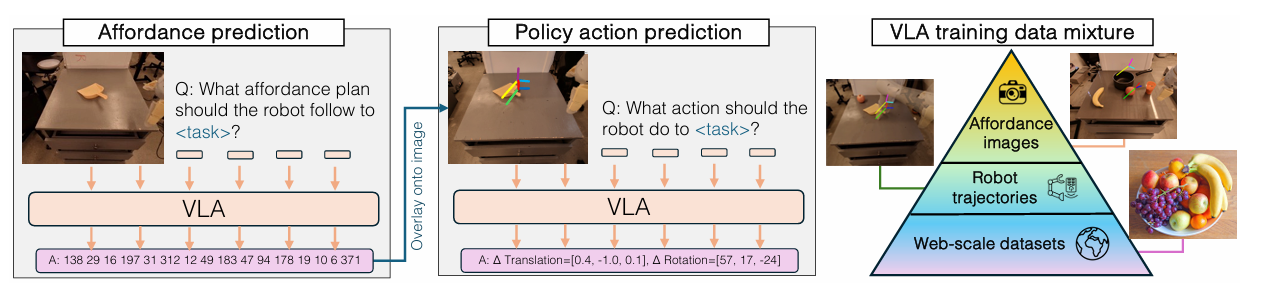
Primeiro, o sistema de custeio é previsto no idioma da obra e na imagem original da obra. Este sistema de cálculo de custos é então combinado com instruções linguísticas para definir uma meta de desempenho. Em seguida, é exibida na imagem e, em seguida, a apólice é colocada nas imagens abrangidas pelo plano de pagamento. O modelo é treinado em conjunto em conjuntos de dados da web (uma enorme fonte de dados), trajetórias de robôs e um número limitado de imagens que são baratas para coletar e rotuladas por tamanho. Essa abordagem se beneficia do uso de dados de trajetória do robô e de extensos conjuntos de dados da web, permitindo que o modelo se integre bem a novos objetos, cenas e tarefas.
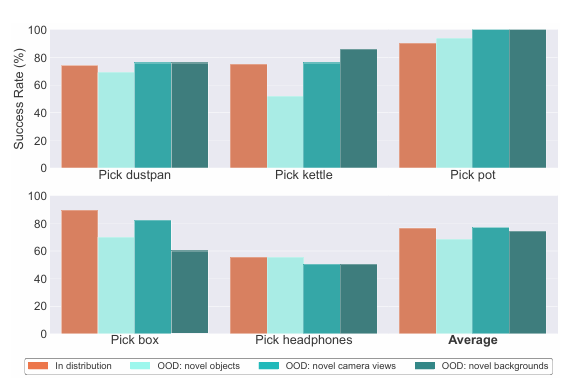
A equipe de pesquisa conduziu vários experimentos com foco em como o poder de compra ajuda a melhorar a aderência do robô, especialmente o movimento de objetos domésticos com formatos complexos (como chaleiras, pás de lixo e panelas). Um exame detalhado mostrou que RT-A permanece forte em vários lugares fora de distribuição (OOD) situações, como objetos novos, ângulos de câmera e planos de fundo. O modelo RT-A teve melhor desempenho que RT-2 e sua variação condicional, alcançando taxas de sucesso de 68%-76% em comparação com o RT-2 24%-28%. Para tarefas além da preensão, como colocar objetos em recipientes, o RT-A apresentou desempenho significativo 70% taxa de sucesso. No entanto, o desempenho do RT-A caiu ligeiramente quando confrontado com objetos completamente novos.
Em última análise, as políticas baseadas em contratos públicos são mais bem orientadas e mais eficazes. O método RT-Affordance melhora muito a robustez e generalização das políticas robóticas, tornando-o uma ferramenta importante para diversas tarefas de manipulação. Embora não consiga se adaptar aos tempos ou às novas competências, o RT-Affordance supera os métodos tradicionais em termos de desempenho. Esta abordagem de custo-benefício abre portas para uma variedade de oportunidades futuras de pesquisa em robótica e pode servir de base para estudos futuros!
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


