
O tamanho é uma maneira importante de resgatar o custo de integrar e melhorar o desempenho do modelo. Os principais modelos de idiomas buscam o processamento da força principal, capacitando a chave para reduzir o uso da memória e a velocidade do desenvolvimento. Ao girar instrumentos lógicos em formato de baixo bit-bit, como INT8, INT4 ou INT2, o aumento reduz os requisitos de armazenamento. No entanto, estratégias regulares geralmente reduzem a precisão, especialmente em dados baixos, como o INT2. Os pesquisadores devem reduzir a precisão para funcionar corretamente ou manter vários modelos com diferentes níveis de valor. Novas estratégias são mais necessárias para manter a qualidade do modelo enquanto fazem um bom desempenho no computador.
O problema básico com a qualificação trata uma redução na precisão com precisão. Os métodos disponíveis até agora treinam modelos diferentes com precisão ou não para beneficiar a natureza do número do número do número. A perda da precisão da quantidade, como no AT2, é muito difícil porque sua memória ganha um distúrbio generalizado. A semelhança de Gemma-2 9b e Misttral 7B é a maior organização e o processo que permite que um modelo funcione em uma série de precisão que pode melhorar a eficiência. A necessidade de mudanças de moderação mais altas que fizeram dos pesquisadores buscar soluções sem maneiras comuns.
Estratégias de equilíbrio menores, cada precisão e eficiência. O Minmax sem os métodos Minimax e GPTQ usa as estatísticas de medição no peso do modelo de mapa para reduzir a pequena largura sem alterar os parâmetros, mas perdeu a precisão da direita. O financiamento baseado no aprendizado, como o treinamento, está ciente dos preços (QAT) e do suprimento eficiente de energia usando penas de gradiente usando penas de gradiente. O QAT estimula modelos de modelos para reduzir a precisão da precisão da pós-química, enquanto o omniquâncer aprende medir e modificar parâmetros sem alterar metais importantes. No entanto, ambos os métodos ainda requerem modelos diferentes para informações diferentes, envio estranho.
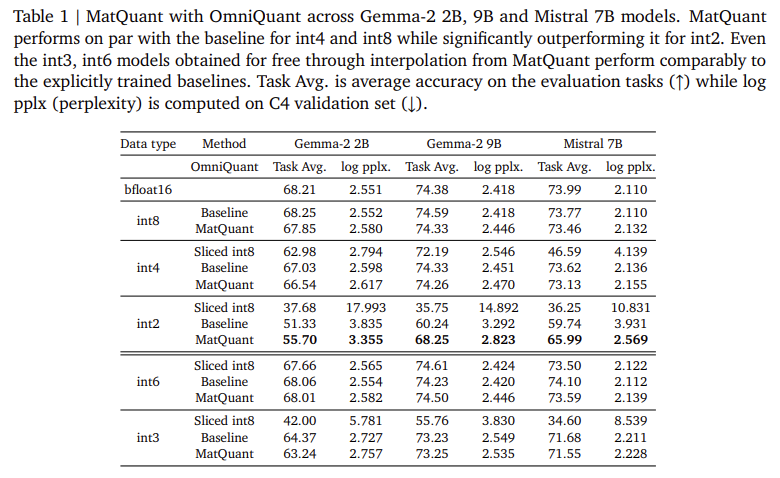
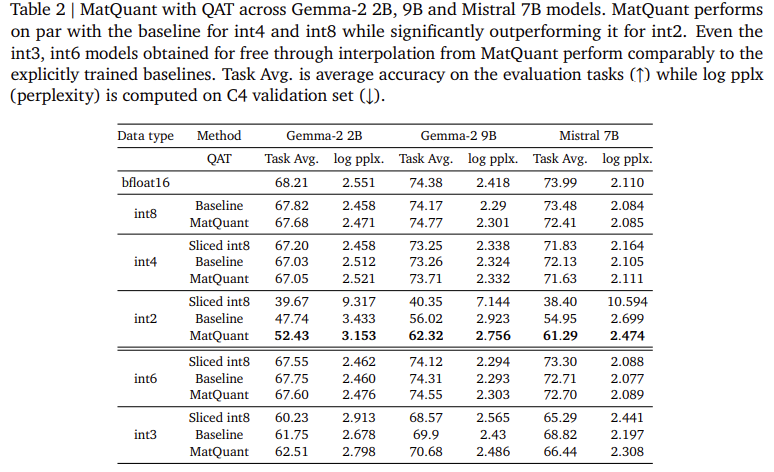
Os investigadores no Google DeepMind são introduzidos Matyooshka de Naked (Matquant) Para criar um modelo que se aplique a todos os muitos níveis. Ao contrário de maneiras comuns de realizar o alcance de cada parte, geralmente faz bem para o modelo IT8, INT4 e AT2 usando uma pequena apresentação roubada. Isso permite que os modelos sejam incluídos em informações diferentes sem retornar, reduzindo o custo da integração. O Matquant remove os modelos de baixo bit de um modelo mais alto, enquanto armazena a precisão, contribuindo com a estrutura hierárquica do número do número. Visualizando os modelos Gemma-2b, Gemma-2 9. E Martqual 7B mostram que os matquants promovem a precisão do TI2, atingindo 10% em relação a estratégias padrão como Qat e Omniquant.
O Matquant representa os instrumentos de modelo em diferentes níveis da lista usando os bits mais importantes (MSB) e os informa para manter a precisão. O procedimento de treinamento inclui treinamento cooperativo e lavagem de dinheiro, garante que a apresentação do IT2 mantenha as informações sensíveis perdidas na construção geral. Em vez de renunciar a edifícios baixos, o Matequant inclui a estrutura para o uso adequado de compressões, que funcionam bem sem a perda de desempenho.
O teste de avaliação Matquant mostra sua energia que reduz a perda de precisão da extensão. Os investigadores verificaram o caminho em Transformmer com base nos parâmetros de alimentação de alimentação (FFN), o principal recurso da chave para a latência da chave de medição. Os resultados indicam que os modelos INT8 e INT4 de MAT8 e IT4 atingiram a precisão comparativa com bantinos treinados enquanto os aliviam do IT2. No modelo GEMMA-2B, uma matrícula avançada de 81%, enquanto o modelo Mittral 7B reconhece 6,35% do desenvolvimento de 6,35% sobre maneiras tradicionais. Este estudo também descobriu que o aborto dos pesos matquant melhora a precisão em uma gama mínima e benéfica de modelos precisos. Além disso, Matquant permite a tradução do bit-bulse de email
Várias chaves do estudo do estudo estão marcando:
- Cautização em várias escalas: Mattquant apresenta o novo método para um fluxo que pode funcionar em muitos níveis.
- Bullying de um edifício menor: o método de receber uma estrutura com recursos naturais nos tipos de dados inteiros, que permite que pequenas larguras sejam tiradas.
- Desenvolveu precisão de baixa qualidade: o Mattuquant desenvolve a precisão dos modelos IT2 separados, as últimas formas tradicionais como Qat e o ompernt com 8%.
- Uma aplicação flexível: o Matequant é compatível com as estratégias de aprendizado existentes com base na aprendizagem, como treinamento de informações (QAT) e muitos jogadores.
- Referência: Como usar com êxito os parâmetros FFN no ffn elmma – 2b, 9b e Misttral 7b, mostrando seu uso ativo.
- Aceitação da prestação de serviços: Mattuquant permite que a criação de modelos forneça melhor precisão entre precisão e computadores, tornando -o melhor para os recursos oprimidos.
- As trocas ideais de pareto: permite a remoção de um pequeno detalhe, como IT6 e AT3, e concordou em densa precisão-chama a negociação de pareto ativa, permitindo informações diferentes.
Em conclusão, o MateQuant traz uma solução para uma solução de gerenciamento de modelos múltiplos usando muito treinamento nos dados do NESTEQED. Isso fornece uma opção flexível, o desempenho mais alto da menor qualidade da detecção real. Este estudo mostra que um modelo pode ser treinado em um modelo de vários números sem uma faixa muito baixa, especialmente na faixa mais baixa, marcando o desenvolvimento importante nos modelos.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, fique à vontade para segui -lo Sane E não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Recomendado para um código aberto de IA' (Atualizado)
O Asphazzaq é um Markteach Media Inc. De acordo com um negócio e desenvolvedor de visualização, a ASIFI está comprometida em integrar uma boa inteligência social. Sua última tentativa é lançada pelo lançamento do Plano de Química para uma Inteligência, Marktechpost, uma prática íntima devastadora de um aprendizado de máquina e problemas de aprendizado profundo que são de forma clara e facilmente compreendida. A plataforma está aderindo a mais de dois milhões de visitas à lua, indicando sua popularidade entre o público.
✅ [Recommended] Junte -se ao nosso canal de telégrafo
: um novo método que melhora a precisão na geração de texto longo combinando memória de trabalho")
 lança OLMo 2: uma nova família de modelos de linguagem 7B e 13B de código aberto treinados em tokens de até 5T")
: uma nova estrutura bidirecional de tokenização de fala aprimorada por Mamba para detecção eficiente de tempo de fala")